Bij Seagate gaan onze technische teams en ik regelmatig in gesprek met ’s werelds grootste ontwikkelaars van cloud- en AI-infrastructuur.
We leveren hen niet alleen exabytes aan harde schijven met een hoge opslagcapaciteit, maar werken ook nauw met hen samen om hun opslagarchitecturen vorm te geven.
Dankzij deze samenwerkingsverbanden heb ik uit de eerste hand kunnen zien hoe beslissingen over hyperscale-opslag tot stand komen. De rode draad is duidelijk: economische aspecten, software-orkestratie en hardwaremogelijkheden moeten op elkaar worden afgestemd om de prestaties, efficiëntie en de waarde van gegevens te maximaliseren.
Die afstemming is nog belangrijker geworden nu AI-workloads de omvang van datasets, de toegangsfrequentie, de contextvensters, de mate van parallellisme, de bewaartermijn en de eisen die aan gedeelde opslagsystemen worden gesteld, steeds verder doen toenemen.
Deze schaalveranderingen hebben de betekenis van het begrip „primaire opslag“ ingrijpend veranderd.
Van oudsher werd onder primaire opslag verstaan: nauw geïntegreerde blok- of bestandssystemen die dicht bij de rekenkracht waren geplaatst. In cloud- en AI-omgevingen wordt primaire opslag echter steeds vaker gekenmerkt door softwaregedefinieerde, wereldwijd verspreide architecturen die objectopslag beschouwen als een permanent registratiesysteem dat enorme hoeveelheden gegevens bewaart en beschikbaar stelt voor diverse workloads.
Om beter te begrijpen hoe deze herdefiniëring tot stand is gekomen, gaan we eens kijken naar de ontwerpprincipes die oorspronkelijk bepalend waren voor bedrijfsopslag.
Hoe schaalgrootte het opslagparadigma heeft veranderd
Al tientallen jaren functioneert het ecosysteem volgens een gemeenschappelijke standaard: de Portable Operating System Interface (POSIX). POSIX, dat is ontstaan in een tijdperk waarin infrastructuur nog grotendeels lokaal was, bood ontwikkelaars een voorspelbaar model voor het werken met gegevens.
Het legde de nadruk op een sterke consistentie tussen lezen en schrijven, synchrone bestandsvergrendeling en hiërarchische mappenstructuren. Voor een enkele machine of een lokaal cluster was het uiterst effectief, en het blijft ook vandaag de dag van cruciaal belang voor veel bedrijfs- en applicatieomgevingen.
Toen het cloudmodel echter zijn intrede deed, veranderden de afwegingen die daarbij een rol speelden. Cloudsystemen zijn ontwikkeld voor een schaal, een distributiemodel en een kostenstructuur die fundamenteel verschillen van die waarvoor POSIX-systemen oorspronkelijk waren ontworpen.
In een gedistribueerde omgeving kunnen POSIX-achtige implementaties een aanzienlijke mate van coördinatie tussen knooppunten vereisen om de directorystructuur, bestandsvergrendeling en updates ter plaatse te waarborgen.
Cloudplatforms moesten op enorme schaal kunnen opereren – en uiteindelijk uitbreiden tot tientallen tot honderden exabytes – en in deze omgeving begon de coördinatie-overhead van nauw gekoppelde ontwerpen vertraging te veroorzaken en praktische beperkingen op te leggen aan de groei.
Bij moderne AI-toepassingen, die nog grotere datasets, checkpointing, tokenverwerking, inferentie en sterk parallelle datapijplijnen vereisen, zijn die druk alleen maar toegenomen.
In de hele sector – van Google Cloud Storage (GCS) en Colossus tot Microsoft Azure Blob, Amazon S3 en Meta’s Tectonic – hebben cloudplatforms gebruikgemaakt van softwaregedefinieerde architecturen die speciaal zijn ontworpen voor wereldwijd verspreide gegevens en hyperscale-workloads, en hebben zij deze in de loop der tijd verder verfijnd naarmate de schaal en de vereisten zich ontwikkelden.
In dit nieuwe paradigma neemt software meer verantwoordelijkheid op zich voor de coördinatie, de veerkracht en de gegevensstroom, zodat de onderliggende opslagmedia zo efficiënt mogelijk kunnen worden benut.
Harde schijven vormen de basis voor opslag op grote schaal
In cloudarchitecturen zoals ik hierboven beschrijf, vormen harde schijven de basis voor het opslaan van gegevens op grote schaal.
Dit weerspiegelt de blijvende economische aspecten van opslagcapaciteit en de fysische wetten van opname met hoge dichtheid. Moderne harde schijven met een hoge opslagcapaciteit maken gebruik van technologieën zoals Shingled Magnetic Recording (SMR) en Heat-Assisted Magnetic Recording (HAMR) om de opslagdichtheid per oppervlakte-eenheid steeds verder te verhogen en opslag op exabyte-schaal mogelijk te maken.
Op deze schaal fungeren reeksen harde schijven als het primaire opslagsysteem en bieden ze een duurzaamheid, kostenefficiëntie en opslagcapaciteit per eenheid die alternatieve opslagtechnologieën simpelweg niet kunnen evenaren.
Er is een reden waarom 87% van de exabytes in grote datacenters op harde schijven wordt opgeslagen1!
Naarmate cloudomgevingen zich verder uitbreiden en AI-workloads steeds grotere hoeveelheden gegevens verbruiken, genereren, bewaren en hergebruiken, worden deze voordelen nog belangrijker.
Maar deze voordelen kunnen alleen ten volle worden benut als de softwarearchitectuur zo is ontworpen dat deze aansluit bij de sterke punten van schijven met een hoge capaciteit.
Traditionele POSIX-toegangspatronen – met name binnen nauw geïntegreerde gedistribueerde bestandssysteemmodellen die de nadruk leggen op gefragmenteerde, willekeurige updates ter plaatse – sluiten op extreme schaal niet altijd goed aan bij die sterke punten.
Moderne softwaregedefinieerde cloudplatforms hebben dit probleem opgelost door hun opslagarchitectuur rond harde schijven te ontwerpen, waardoor ze prioriteit kunnen geven aan sequentiële gegevensstromen met een hoge doorvoercapaciteit en tegelijkertijd een schaalbare bedrijfsvoering kunnen ondersteunen.
In het geval van Amazon S3, een dienst die 500 biljoen objecten opslaat en 200 miljoen verzoeken per seconde verwerkt—werd in een recente keynote op AWS re:Invent2 benadrukt dat het geheim achter de prestaties van cloudopslag ligt in het schrijven van software die is geoptimaliseerd voor de mogelijkheden van de harde schijf—die in de presentatie werd omschreven als een „technisch wonder“.
In plaats van de schijf te dwingen zich aan te passen aan software-abstracties die voor een ander tijdperk zijn ontworpen, zijn moderne cloudarchitecturen zo ontworpen dat ze de sterke punten van moderne harde schijven met hoge opslagdichtheid optimaal benutten.
Hoe cloudarchitecturen de efficiëntie van harde schijven optimaliseren
Dit technisch ontwerp heeft verschillende vormen aangenomen, maar bij de toonaangevende cloudplatforms komt het over het algemeen neer op vier architecturale principes. Samen laten zij zien hoe cloudopslag steeds meer softwaregestuurd is geworden in de manier waarop de gegevensstroom, metagegevens, veerkracht en het invoerproces worden beheerd.
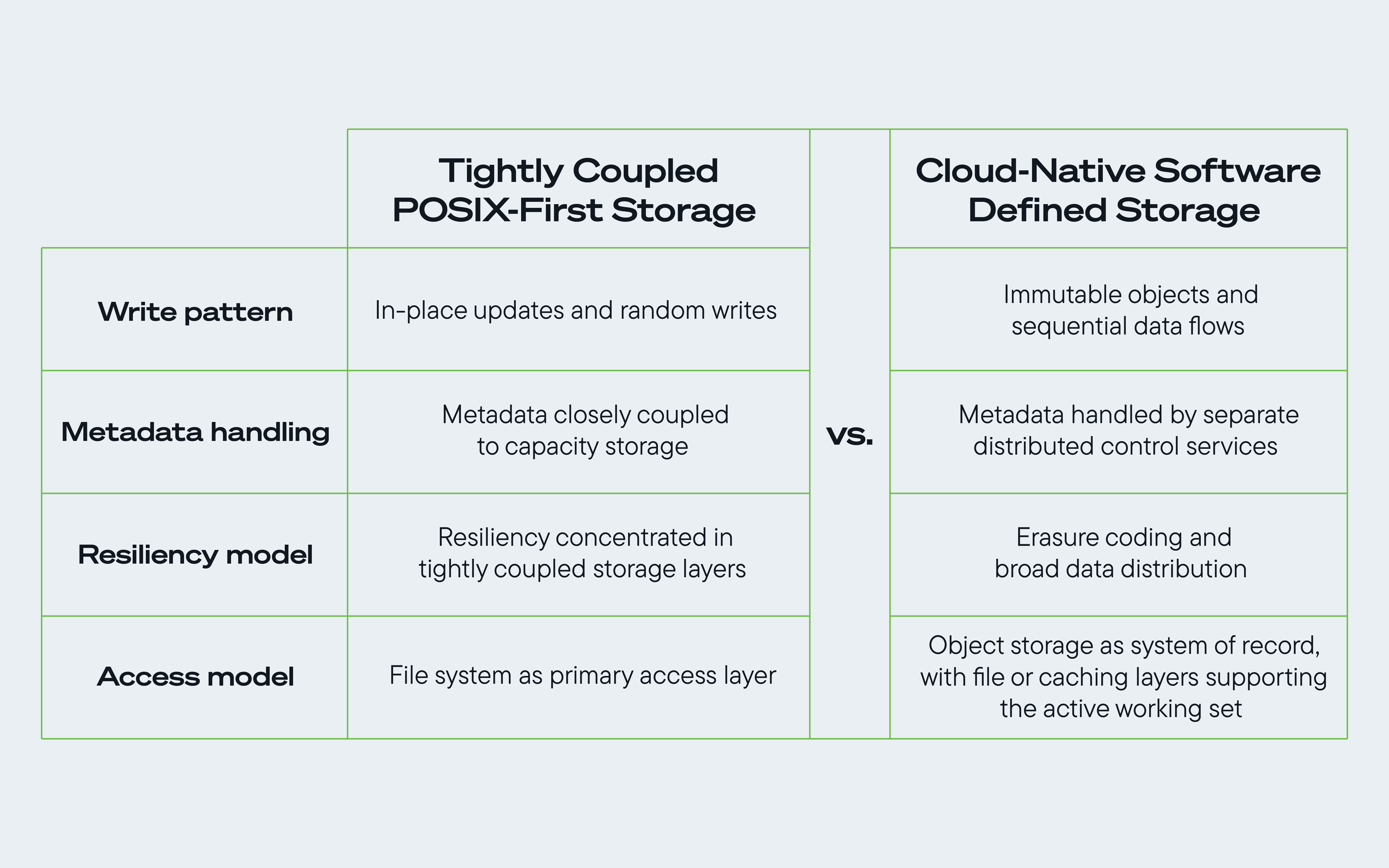
1. De onveranderlijkheid van objecten bevordert sequentiële gegevensstromen
Diensten zoals GCS en Amazon S3 zijn ontworpen om de onveranderbaarheid van objecten en updates met versiebeheer te ondersteunen. Zodra gegevens naar een objectopslag zijn geschreven, worden updates doorgaans afgehandeld door een nieuwe versie van het object te schrijven in plaats van het bestaande object ter plekke te wijzigen.
Door de noodzaak van willekeurige, ter plekke uitgevoerde binaire schrijfbewerkingen te verminderen, verleggen architecturen op cloudschaal een groter deel van de werklast van de schijf naar grote, sequentiële gegevensstromen. Dat sluit beter aan bij de manier waarop schijven met een hoge capaciteit op grote schaal doorvoersnelheid en efficiëntie bieden. Dit voordeel wordt nog belangrijker bij AI-workloads, waarbij het opslaan van checkpoints, het verplaatsen van datasets en parallelle pijplijnen een voortdurende druk op gedeelde opslagsystemen kunnen uitoefenen.
2. Metadata worden steeds vaker beheerd door afzonderlijke of gedistribueerde beheersdiensten
In een traditionele POSIX-omgeving worden bestandsmetadata en bestandsinhoud in opslagsystemen vaak op nauw met elkaar verweven wijze beheerd. Hyperscale-cloudplatforms hebben hier verandering in gebracht door metadataservices los te koppelen van de opslagcapaciteit, waardoor een groot deel van de monitoring en coördinatie is verplaatst naar snellere, beter schaalbare besturingslagen, in plaats van die taak aan de schijven zelf over te laten.
Colossus van Google Cloud verplaatst een groot deel van dit werk naar diensten die in het geheugen worden uitgevoerd, terwijl Tectonic van Meta metadata – binnen een gedistribueerd bestandssysteemmodel – opsplitst in stateloze microservices die draaien op een horizontaal schaalbare sleutel-waarde-opslag. Het resultaat is minder structurele overhead op de onderliggende harde schijven en meer mogelijkheden voor deze schijven om op grote schaal compacte, efficiënte opslagcapaciteit te bieden.
3. Erasure-codering versterkt de veerkracht van gedistribueerde systemen
Een derde principe is het gebruik van erasure-codering en brede gegevensverspreiding om grootschalige opslagsystemen veerkrachtiger en efficiënter te maken.
Cloudarchitecturen verminderen die kwetsbaarheid door middel van erasure coding en een brede verspreiding van gegevens. Door gegevens over meerdere schijven te verspreiden, kunnen deze systemen lokale piekbelastingen isoleren, gegevens blijven leveren tijdens korte pieken in de latentie en de gegevens indien nodig herstellen. Dit maakt de opslaglaag veerkrachtiger en draagt bij aan het behoud van de doorvoercapaciteit bij gemengde cloud- en AI-workloads.
4. Het meerlaagse gegevenspad
Een vierde principe betreft de manier waarop gegevens worden opgeslagen voordat ze op de opslagmedia terechtkomen.
Om de kloof te overbruggen tussen onvoorspelbaar applicatieverkeer en de gestructureerde omgeving waarin harde schijven met hoge opslagdichtheid het best tot hun recht komen, maken moderne architecturen gebruik van een meerlagig gegevenspad, waarbij flashgeheugen of werkgeheugen wordt ingezet om de gegevensinvoer te bufferen en de gegevensplaatsing te optimaliseren.
Een flash-laag vangt variabele binnenkomstsnelheden op van API-verkeer en schrijfbewerkingen door applicaties. Het bereidt binnenkomende gegevens voor en organiseert deze voordat ze naar opslagmedia worden overgebracht, waardoor achtergrondprocessen deze in lange, opeenvolgende stappen naar harde-schijfarrays kunnen kopiëren.
Bij AI-workloads, waarbij het invoeren van gegevens, het maken van checkpoints en het verplaatsen van datasets bijzonder piekerig kunnen zijn, wordt deze bufferfunctie nog belangrijker, omdat deze ervoor zorgt dat zowel de invoer met lage latentie als een efficiënt gebruik van de harde schijf gewaarborgd blijven.
Fig. 1. Een vergelijking tussen traditionele POSIX- en cloud-native opslagsoftware met het oog op het optimaal benutten van de voordelen van een op harde schijven gebaseerde opslagarchitectuur.
Een nieuw model voor primaire opslag
Al deze architecturale veranderingen hebben samen de definitie van primaire opslag ingrijpend gewijzigd. In het verleden verwees de term „primaire opslag“ vaak naar dure, zeer betrouwbare blok- of bestandssystemen die nauw waren gekoppeld aan de rekenkracht. Objectopslag werd doorgaans beschouwd als een minder belangrijke opslaglocatie voor archief-, back-up- of secundaire gegevens.
Tegenwoordig wordt primaire opslag in veel cloud-native architecturen ruimer gedefinieerd: stateless computing in combinatie met een wereldwijde objectopslag. Datameren die zijn gebouwd op platforms zoals S3, Azure en GCS fungeren in toenemende mate als een referentiesysteem voor grootschalige analyses, cloudtoepassingen en AI-workflows.
In dit model wordt primaire opslag in toenemende mate softwarematig gedefinieerd, waarbij objectdiensten, metadatalagen, flashbuffering en harde schijven met hoge capaciteit als een gecoördineerd systeem samenwerken.
Compute-instances worden vaak beschouwd als flexibeler en stateless; ze halen gegevens op uit de objectlaag, verwerken deze en schrijven de resultaten terug naar dezelfde gedeelde omgeving.
De convergentie van objectopslag en bestandssemantiek
Naarmate objectopslag het afgelopen decennium een steeds centralere rol ging spelen in cloudarchitecturen en recentelijk ook in AI-workflows, deed zich een andere belangrijke trend voor: krachtige, parallelle bestandssystemen.
Systemen zoals Lustre, Weka en VAST zijn ontworpen om de prestaties voor nauw gekoppelde workloads te optimaliseren, waarbij vaak POSIX-conforme interfaces worden aangeboden ter ondersteuning van checkpointing, coördinatie en gegevensverwerking met hoge doorvoercapaciteit.
Tegelijkertijd zijn objectopslagplatforms zich blijven ontwikkelen: ze zijn geoptimaliseerd voor wereldwijde schaalbaarheid en bieden betere prestaties om een groeiend aantal AI- en data-intensieve workloads te ondersteunen.
In grootschalige cloud- en AI-omgevingen lopen deze benaderingen steeds meer in elkaar over. Krachtige bestandssystemen worden vaak bovenop objectopslagbackends ingebouwd of daarin geïntegreerd, waarbij de prestaties voor de actieve werkverzameling worden gecombineerd met de schaalbaarheid en de kostenefficiëntie van objectopslag als het primaire opslagsysteem.
Deze convergentie weerspiegelt een bredere architecturale verschuiving: in plaats van te kiezen tussen bestanden en objecten, combineren moderne systemen deze. Het behoudt het gebruiksgemak van mappen, naamruimten en vertrouwde bestandsfuncties, zonder afbreuk te doen aan de schaalvoordelen van objectopslag.
Gevolgen voor ontwikkelaars van cloud- en AI-infrastructuur
Alles bij elkaar genomen wijzen deze verschuivingen op een bredere conclusie: cloud- en AI-architecturen vereisten andere afwegingen op het gebied van software en systemen dan waarvoor POSIX-first-modellen oorspronkelijk waren ontworpen.
Door die afwegingen werd het steeds belangrijker om software zo te ontwerpen dat het gebruik van de onderliggende harde-schijvenparken waarop systemen zijn gebaseerd, optimaal wordt benut. In die zin hebben cloud- en AI-workloads niet alleen de opslagarchitectuur veranderd; ze hebben de primaire opslag zelf opnieuw gedefinieerd.
Voor infrastructuurontwikkelaars is de conclusie duidelijk: ontwerpen voor moderne systemen betekent dat men verder moet kijken dan de aanname dat primaire opslag één op één moet aansluiten bij de lokale bestandsstructuur van het besturingssysteem. Dit houdt in dat er software en toegangsmodellen moeten worden gekozen die aansluiten bij de economische, fysische en werkbelastinggerelateerde realiteit van AI op grote schaal.
Organisaties die dit goed aanpakken, zullen beter in staat zijn om AI-strategieën efficiënt uit te voeren, met een hogere GPU-benutting, betere kosten-batenverhoudingen bij inferentie en minder prestatieknelpunten.
Lees meer over de innovaties op het gebied van harde schijven die de primaire opslag vormen voor ’s werelds grootste ontwikkelaars van AI- en cloudinfrastructuur.
Bronnen
1. IDC Datasphere en IDC Storagesphere
2. AWS re:Invent 2025, Keynote van Andy Warfield: S3 slaat meer dan 500 biljoen objecten op, verwerkt 200 miljoen verzoeken per seconde en verwerkt meer dan 1 quadriljoen verzoeken per jaar