Aqui na Seagate, nossas equipes de engenharia e eu nos reunimos regularmente com os maiores construtores de infraestrutura de nuvem e IA do mundo.
Além de fornecer a eles exabytes de discos rígidos de alta capacidade, trabalhamos lado a lado para ajudar a moldar suas arquiteturas de armazenamento.
Por meio dessas parcerias, tive um lugar privilegiado para observar como as decisões de armazenamento em hiperescala são tomadas. O fio condutor é claro: a economia, a orquestração de software e as capacidades de hardware devem estar alinhadas para maximizar o desempenho, a eficiência e o valor dos dados.
Esse alinhamento tornou-se ainda mais importante à medida que as cargas de trabalho de IA continuam a aumentar o tamanho dos conjuntos de dados, a frequência de acesso, as janelas de contexto, o paralelismo, o tempo de retenção e as demandas impostas aos sistemas de armazenamento compartilhado.
Essas mudanças de escala alteraram fundamentalmente o significado de "armazenamento primário".
Historicamente, o armazenamento primário se referia a sistemas de blocos ou arquivos fortemente acoplados, posicionados próximos ao centro de computação. Em ambientes de nuvem e IA, no entanto, o armazenamento primário é cada vez mais definido por arquiteturas distribuídas globalmente e definidas por software, que tratam o armazenamento de objetos como um sistema de registro persistente que retém e fornece volumes massivos de dados em diversas cargas de trabalho.
Para entender melhor como essa redefinição se desenrolou, vamos analisar os princípios de design que originalmente moldaram o armazenamento empresarial.
Como a escala mudou o paradigma de armazenamento
Durante décadas, o ecossistema operou sob um padrão comum: a Interface de Sistema Operacional Portátil (POSIX). Concebido numa era de infraestrutura mais localizada, o POSIX ofereceu aos desenvolvedores um modelo previsível para interagir com dados.
Enfatizou-se a forte consistência de leitura após a gravação, o bloqueio síncrono de arquivos e as estruturas de diretório hierárquicas. Para uma única máquina ou um cluster localizado, era altamente eficaz e continua sendo fundamental para muitos ambientes corporativos e de aplicativos atualmente.
No entanto, com o surgimento do modelo de nuvem, as compensações que o regia mudaram. Os sistemas em escala de nuvem foram construídos para uma escala, um modelo de distribuição e uma estrutura de custos fundamentalmente diferentes daqueles para os quais os sistemas POSIX foram originalmente projetados.
Em um ambiente distribuído, as implementações no estilo POSIX podem exigir uma orquestração significativa entre os nós para preservar a semântica de diretórios, o bloqueio de arquivos e as atualizações no local.
As plataformas em nuvem precisavam de uma escalabilidade massiva — eventualmente expandindo-se para suportar dezenas a centenas de exabytes — e, nesse ambiente, a sobrecarga de coordenação de projetos fortemente acoplados começou a introduzir latência e a impor limites práticos ao crescimento.
Em cargas de trabalho modernas de IA que exigem conjuntos de dados ainda maiores, checkpointing, processamento de tokens, inferência e pipelines de dados altamente paralelos, essas pressões apenas se intensificaram.
Em todo o setor — do Google Cloud Storage (GCS) e Colossus ao Microsoft Azure Blob, Amazon S3 e Tectonic da Meta — as plataformas de nuvem adotaram arquiteturas definidas por software, criadas especificamente para dados distribuídos globalmente e cargas de trabalho em hiperescala, e as refinaram ao longo do tempo à medida que a escala e os requisitos evoluíam.
Nesse novo paradigma, o software assume mais responsabilidade pela orquestração, resiliência e fluxo de dados, para que a mídia de armazenamento subjacente possa ser usada da forma mais eficiente possível.
Discos rígidos ancoram o armazenamento em grande escala.
Em arquiteturas de nuvem como as que mencionei acima, os discos rígidos são a base para o armazenamento de dados em grande escala.
Isso reflete a economia duradoura da capacidade e a física da gravação de alta densidade. Os discos rígidos modernos de alta capacidade incorporam tecnologias como a gravação magnética sobreposta (SMR) e a gravação magnética assistida por calor (HAMR) para continuar aumentando a densidade de área e tornar possível o armazenamento em escala de exabyte.
Nessa escala, frotas de discos rígidos servem como sistema de registro, oferecendo durabilidade, custo-benefício e densidade volumétrica que outras tecnologias de armazenamento simplesmente não conseguem igualar.
Existe um motivo pelo qual 87% dos exabytes de grandes centros de dados são armazenados em discos rígidos1!
À medida que os ambientes de nuvem continuam a se expandir e as cargas de trabalho de IA consomem, geram, retêm e reutilizam volumes cada vez maiores de dados, essas vantagens se tornam ainda mais relevantes.
Mas elas só podem ser plenamente aproveitadas se a arquitetura do software for projetada para se alinhar com os pontos fortes dos discos de alta capacidade.
Os padrões tradicionais de acesso POSIX — especialmente em modelos de sistemas de arquivos distribuídos e fortemente acoplados que enfatizam atualizações fragmentadas, aleatórias e in-place — nem sempre estão bem alinhados com esses pontos fortes em escala extrema.
As plataformas modernas de nuvem definidas por software resolveram esse problema projetando suas estruturas de armazenamento em torno de discos rígidos, o que lhes permite priorizar fluxos de dados sequenciais e de alta taxa de transferência, ao mesmo tempo que oferecem suporte a uma economia operacional escalável.
No caso do Amazon S3, um serviço que armazena 500 trilhões de objetos e atende 200 milhões de solicitações por segundo—uma recente palestra principal do AWS re:Invent2 enfatizou que o segredo do desempenho do armazenamento em nuvem é escrever software que otimize os recursos do disco rígido—descrito na apresentação como uma “maravilha da engenharia”.
Em vez de forçar o disco rígido a se conformar a abstrações de software projetadas para uma era diferente, as arquiteturas de nuvem modernas são projetadas para complementar os pontos fortes dos discos rígidos modernos de alta densidade.
Como as arquiteturas em nuvem desbloqueiam a eficiência dos discos rígidos
Esse projeto de engenharia assumiu diversas formas, mas, nas principais plataformas de nuvem, geralmente reflete quatro princípios arquitetônicos. Em conjunto, demonstram como o armazenamento em nuvem se tornou cada vez mais definido por software na forma como gerencia o fluxo de dados, os metadados, a resiliência e o comportamento de ingestão.
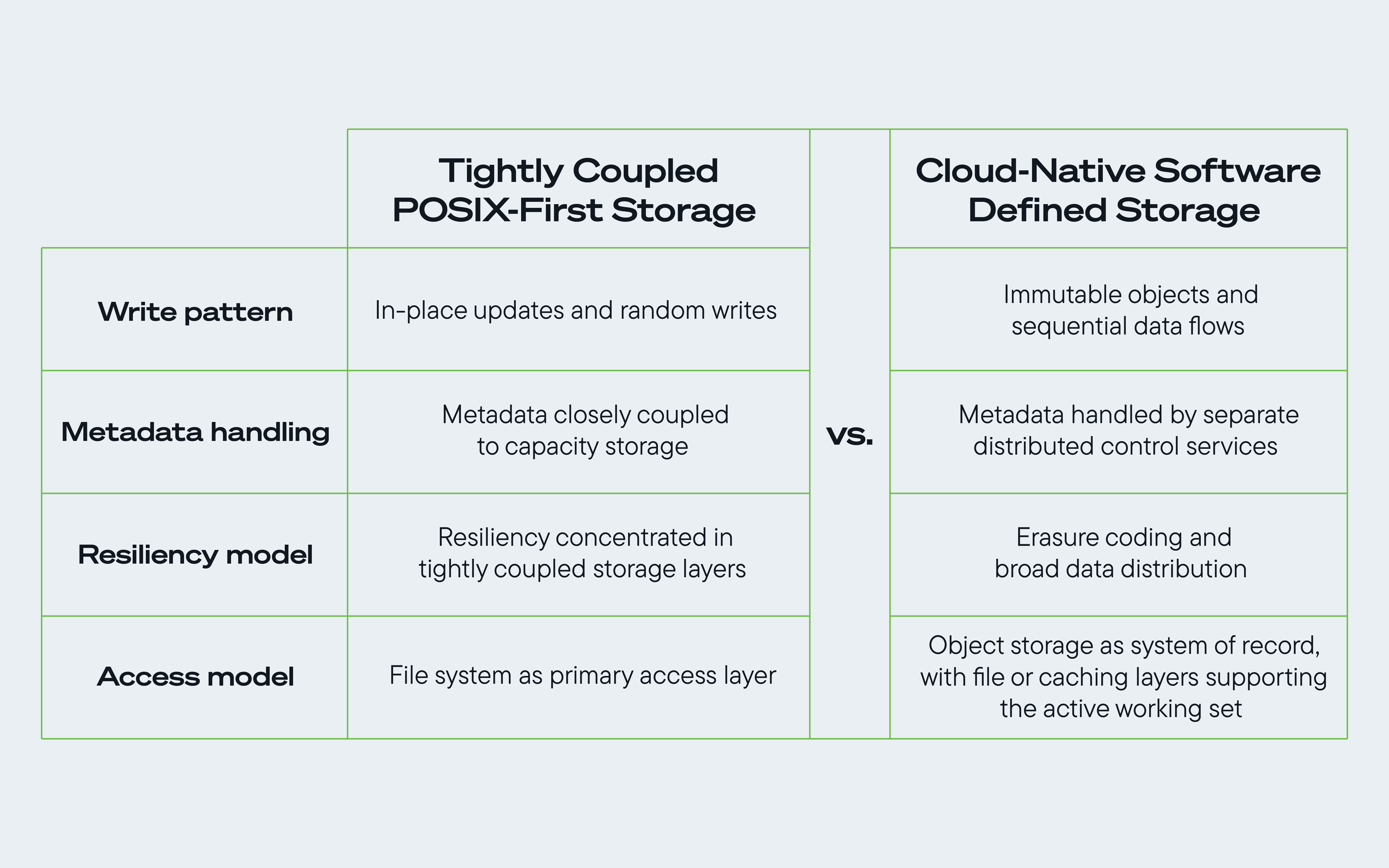
1. A imutabilidade dos objetos favorece fluxos de dados sequenciais.
Serviços como o GCS e o Amazon S3 são projetados para oferecer suporte à imutabilidade de objetos e atualizações versionadas. Depois que os dados são gravados em um armazenamento de objetos, as atualizações geralmente são tratadas gravando uma nova versão do objeto em vez de modificar a versão existente no mesmo local.
Ao reduzir a necessidade de gravações binárias aleatórias e in-loco, as arquiteturas em escala de nuvem transferem mais da carga de trabalho do disco para grandes fluxos de dados sequenciais. Isso se alinha melhor com a forma como os drives de alta capacidade proporcionam rendimento e eficiência em grande escala. Essa vantagem torna-se ainda mais importante em cargas de trabalho de IA, onde o checkpointing, a movimentação de conjuntos de dados e os pipelines paralelos podem gerar pressão constante sobre os sistemas de armazenamento compartilhado.
2. Metadados são cada vez mais gerenciados por serviços de controle separados ou distribuídos.
Em um ambiente POSIX tradicional, os sistemas de armazenamento geralmente gerenciam os metadados e o conteúdo dos arquivos de maneira bastante integrada. As plataformas de nuvem hiperescaláveis mudaram isso ao separar os serviços de metadados do armazenamento de capacidade, transferindo grande parte do rastreamento e da coordenação para camadas de controle mais rápidas e escaláveis, em vez de deixar essa carga sobre os próprios discos.
O Colossus do Google Cloud transfere grande parte desse trabalho para serviços residentes em memória, enquanto o Tectonic da Meta separa os metadados — dentro de um modelo de sistema de arquivos distribuído — em microsserviços sem estado executados em um armazenamento de chave-valor horizontalmente escalável. O resultado é uma menor sobrecarga estrutural nos discos rígidos subjacentes e mais oportunidades para que eles ofereçam capacidade densa e eficiente em grande escala.
3. A codificação de apagamento fortalece a resiliência distribuída.
Um terceiro princípio é o uso de codificação de apagamento e ampla distribuição de dados para tornar os sistemas de armazenamento em larga escala mais resilientes e eficientes.
As arquiteturas em nuvem reduzem essa sensibilidade por meio de codificação de apagamento e ampla distribuição de dados. Ao distribuir os objetos por vários discos, esses sistemas conseguem isolar pontos de acesso críticos localizados, continuar fornecendo dados mesmo durante breves picos de latência e reconstruir a infraestrutura conforme necessário. Isso torna a camada de armazenamento mais resiliente e ajuda a manter a taxa de transferência em cargas de trabalho mistas de nuvem e IA.
4. O Caminho de Dados de Múltiplas Camadas
Um quarto princípio diz respeito à forma como os dados são organizados antes de atingirem a capacidade máxima da mídia.
Para colmatar a lacuna entre o tráfego imprevisível das aplicações e o ambiente estruturado que os discos rígidos de alta densidade melhor suportam, as arquiteturas modernas utilizam um caminho de dados multicamadas, incorporando memória flash ou memória RAM para armazenar em buffer a ingestão de dados e otimizar a sua colocação.
Uma camada flash absorve taxas de chegada variáveis do tráfego da API e das gravações do aplicativo. Ele prepara e organiza os dados recebidos antes de serem transferidos para mídias de alta capacidade, permitindo que processos em segundo plano os transfiram para matrizes de discos rígidos em longas passagens sequenciais.
Em cargas de trabalho de IA, onde a ingestão, o checkpoint e a movimentação de conjuntos de dados podem ser especialmente intermitentes, essa função de bufferização torna-se ainda mais importante, pois ajuda a preservar tanto a baixa latência na ingestão quanto a utilização eficiente do disco rígido.
Fig. Uma comparação entre o software de armazenamento POSIX tradicional e o software de armazenamento nativo da nuvem para maximizar os benefícios da arquitetura de armazenamento centrada em discos rígidos.
Um novo modelo para armazenamento primário
Em conjunto, essas mudanças arquitetônicas remodelaram a definição de armazenamento primário. Historicamente, o termo "armazenamento primário" frequentemente se referia a sistemas de blocos ou arquivos caros e de alta disponibilidade, conectados diretamente ao computador. O armazenamento de objetos era mais comumente tratado como um destino de nível inferior para arquivos, backups ou dados secundários.
Atualmente, muitas arquiteturas nativas da nuvem definem o armazenamento primário de forma mais ampla: computação sem estado combinada com um armazenamento de objetos global. Os data lakes construídos em plataformas como S3, Azure e GCS servem cada vez mais como um sistema de registro para análises em larga escala, aplicações em nuvem e fluxos de trabalho de IA.
Nesse modelo, o armazenamento primário é cada vez mais definido por software, com serviços de objetos, camadas de metadados, buffer flash e discos rígidos de alta capacidade trabalhando juntos como um sistema coordenado.
As instâncias de computação são frequentemente tratadas como mais elásticas e sem estado, obtendo dados da camada de objetos, processando-os e gravando os resultados de volta no mesmo ambiente compartilhado.
A convergência do armazenamento de objetos e da semântica de arquivos
Com a crescente importância do armazenamento de objetos nas arquiteturas de nuvem na última década e, mais recentemente, nos fluxos de trabalho de IA, surgiu outra tendência importante: sistemas de arquivos paralelos de alto desempenho.
Sistemas como Lustre, Weka e VAST são projetados para maximizar o desempenho de cargas de trabalho fortemente acopladas, frequentemente expondo interfaces compatíveis com POSIX para suportar checkpointing, coordenação e acesso a dados de alta taxa de transferência.
Ao mesmo tempo, as plataformas de armazenamento de objetos continuaram a evoluir, otimizando a escalabilidade global e aprimorando o desempenho para suportar um conjunto crescente de cargas de trabalho de IA e de uso intensivo de dados.
Em ambientes de nuvem e IA de grande escala, essas abordagens estão convergindo. Sistemas de arquivos de alto desempenho frequentemente se sobrepõem ou se intercalam em camadas com backends de armazenamento de objetos, combinando o desempenho do conjunto de trabalho ativo com a escalabilidade e a economia do armazenamento de objetos como sistema de registro.
Essa convergência reflete uma mudança arquitetônica mais ampla: em vez de escolher entre arquivo e objeto, os sistemas modernos os combinam. Ele preserva a conveniência de pastas, namespaces e comportamentos familiares de arquivos sem sacrificar as vantagens de escalabilidade do armazenamento de objetos.
Implicações para construtores de infraestrutura de nuvem e IA
Vistas em conjunto, essas mudanças apontam para uma conclusão mais ampla: as arquiteturas de nuvem e IA exigiam compensações de software e sistema diferentes daquelas para as quais os modelos POSIX-first foram originalmente projetados para otimizar.
Essas compensações aumentaram a importância de projetar software para otimizar o uso dos conjuntos de discos rígidos subjacentes nos quais os sistemas são construídos. Nesse sentido, as cargas de trabalho em nuvem e de IA não apenas alteraram a arquitetura de armazenamento; elas redefiniram o próprio armazenamento primário.
Para os construtores de infraestrutura, a conclusão é clara: projetar para sistemas modernos significa ir além da suposição de que o armazenamento primário deve ser mapeado perfeitamente para uma árvore de arquivos do sistema operacional local. Significa escolher softwares e modelos de acesso que estejam alinhados com as realidades econômicas, físicas e de carga de trabalho da IA em grande escala.
Organizações que acertarem nesse ponto estarão em melhor posição para executar estratégias de IA com eficiência, com maior utilização de GPUs, melhor economia de inferência e menos gargalos de desempenho.
Saiba mais sobre a inovação em discos rígidos que impulsiona o armazenamento primário para os maiores criadores de infraestrutura de IA e nuvem do mundo.
Fontes
1. IDC Datasphere e IDC Storagesphere
2. AWS re:Invent 2025, palestra de Andy Warfield: O S3 armazena mais de 500 trilhões de objetos, atende a 200 milhões de solicitações por segundo e processa mais de 1 quatrilhão de solicitações por ano.