在 Seagate,我们的工程团队和我会定期与全球最大的云计算和人工智能基础设施建设者进行交流。
除了为他们提供数 EB 级大容量硬盘外,我们还与他们并肩合作,帮助他们构建存储架构。
通过这些合作关系,我得以近距离了解超大规模存储决策是如何制定的。共同点很明显:经济性、软件编排和硬件能力必须协调一致,才能最大限度地提高性能、效率和数据价值。
随着人工智能工作负载不断增加,数据集规模、访问频率、上下文窗口、并行性、保留时间和对共享存储系统的要求也越来越高,这种一致性变得更加重要。
规模上的这些变化从根本上改变了“主存储”的含义。
从历史上看,主存储指的是紧耦合的块存储或文件系统,它们位于计算区域附近。然而,在云计算和人工智能环境中,主存储越来越多地由软件定义的全球分布式架构来定义,这些架构将对象存储视为持久记录系统,用于跨工作负载保留和提供海量数据。
为了更好地理解这种重新定义是如何展开的,让我们来剖析一下最初塑造企业存储的设计原则。
规模如何改变了存储范式
几十年来,该生态系统一直遵循一个通用标准:可移植操作系统接口(POSIX)。POSIX 标准诞生于基础设施更加本地化的时代,它为开发人员提供了一个可预测的数据交互模型。
它强调了强大的读写一致性、同步文件锁定和分层目录结构。对于单台机器或本地集群而言,它非常有效,并且至今仍对许多企业和应用程序环境至关重要。
然而,随着云计算模式的出现,权衡取舍的格局发生了变化。云规模系统的构建是为了满足与 POSIX 优先系统最初设计所服务的规模、分布模型和成本结构截然不同的需求。
在分布式环境中,POSIX 风格的实现可能需要跨节点进行大量的协调,以保持目录语义、文件锁定和就地更新。
云平台需要大规模扩展——最终扩展到支持数十到数百艾字节——在这种环境下,紧密耦合设计的协调开销开始引入延迟,并对增长施加了实际限制。
在现代人工智能工作负载需要更大的数据集、检查点、标记处理、推理和高度并行的数据管道时,这些压力只会加剧。
从 Google Cloud Storage (GCS) 和 Colossus 到 Microsoft Azure Blob、Amazon S3 和 Meta 的 Tectonic,整个行业都采用了专为全球分布式数据和超大规模工作负载而构建的软件定义架构,并随着规模和需求的演变而不断改进。
在这种新模式下,软件承担了更多的编排、弹性和数据流方面的责任,以便尽可能高效地利用底层存储介质。
硬盘驱动器是规模化存储的基石
在我上面提到的那些云架构中,硬盘是大规模存储数据的基础。
这反映了容量的持久经济性和高密度记录的物理特性。现代大容量硬盘采用了叠瓦式磁记录 (SMR) 和 热辅助磁记录 (HAMR) 等技术,不断提高面密度,使 EB 级存储成为可能。
在这种规模下,硬盘集群充当记录系统,提供其他存储技术根本无法比拟的耐用性、成本效益和体积密度。
大型数据中心 87% 的 EB 数据都存储在硬盘上是有原因的1!
随着云环境的不断扩展,以及人工智能工作负载消耗、生成、保留和重用更多数据,这些优势变得更加重要。
但只有当软件架构的设计与大容量磁盘的优势相匹配时,这些优势才能得到充分发挥。
传统的 POSIX 访问模式——尤其是在强调碎片化、随机、就地更新的紧密耦合分布式文件系统模型中——在极端规模下并不总是能很好地发挥这些优势。
现代软件定义云平台通过围绕硬盘设计存储堆栈来解决这个问题,使其能够优先处理顺序的高吞吐量数据流,同时支持可扩展的运营经济性。
以 Amazon S3 为例,这项服务存储 500 万亿个对象,每秒处理 2 亿个请求——最近的 AWS re:Invent 主题演讲2强调,云存储性能的秘诀在于编写针对硬盘驱动器功能进行优化的软件——在演讲中,硬盘驱动器被描述为“工程奇迹”。
现代云架构的设计目的并非强迫硬盘驱动器适应为不同时代设计的软件抽象,而是与现代高密度硬盘驱动器的优势相辅相成。
云架构如何释放硬盘效率
这种工程设计有多种形式,但在主流云平台中,它通常体现了四个架构原则。它们共同表明,云存储如何以软件定义的方式管理数据流、元数据、弹性和摄取行为。
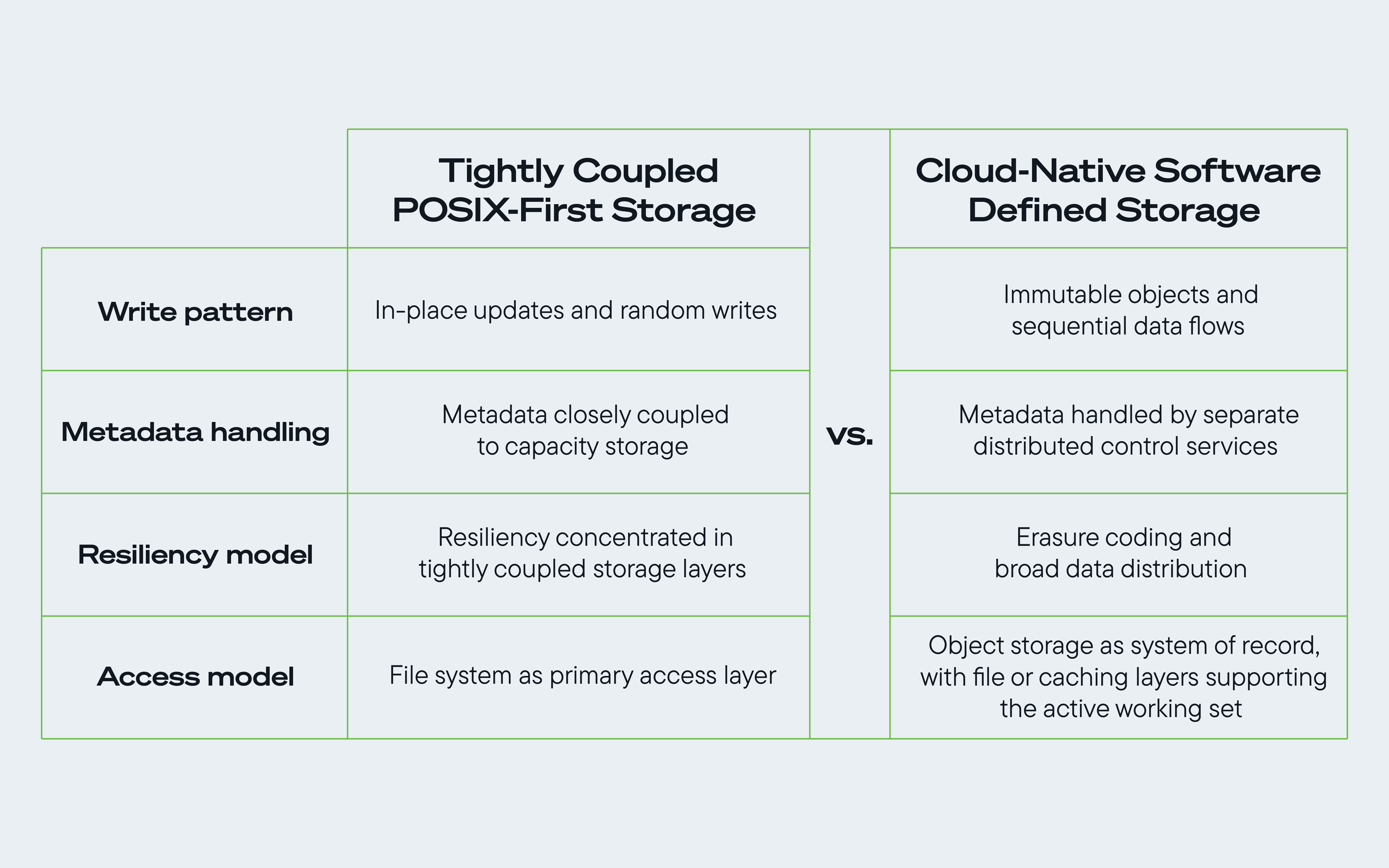
1.对象不可变性有利于顺序数据流
GCS 和 Amazon S3 等服务旨在支持对象不可变性和版本化更新。数据写入对象存储后,更新通常是通过写入对象的新版本而不是就地修改现有对象来处理的。
通过减少对随机、原地二进制写入的需求,云规模架构将磁盘的更多工作负载转移到大型顺序数据流上。这与大容量硬盘大规模提供吞吐量和效率的方式更加契合。在 AI 工作负载下,这种优势变得更加重要,因为检查点、数据集移动和并行管道会对共享存储系统造成持续的压力。
2.元数据越来越多地由独立或分布式的控制服务处理
在传统的 POSIX 环境中,存储系统通常以紧密耦合的方式管理文件元数据和文件有效负载。超大规模云平台通过将元数据服务与容量存储分离来改变这种状况,将大部分跟踪和协调工作转移到速度更快、可扩展性更强的控制层,而不是将这些负担留给磁盘本身。
Google Cloud 的 Colossus 将大部分此类工作转移到内存驻留服务中,而 Meta 的 Tectonic 将元数据(在分布式文件系统模型中)分离成在水平可扩展的键值存储上运行的无状态微服务。这样一来,底层硬盘的结构开销就减少了,硬盘就有了更多机会大规模地提供高密度、高效的容量。
3.纠删码增强分布式弹性
第三个原则是使用纠删码和广泛的数据分发,使大规模存储系统更具弹性和效率。
云架构通过纠删码和广泛的数据分发来降低这种敏感性。通过将对象分散到多个磁盘上,这些系统可以隔离局部热点,在短暂的延迟高峰期间继续提供数据,并根据需要进行重建。这使得存储层更具弹性,并有助于在混合云和 AI 工作负载下维持吞吐量。
4.多层数据路径
第四个原则是数据在到达容量介质之前是如何进行暂存的。
为了弥合不可预测的应用流量与高密度硬盘最擅长处理的结构化环境之间的差距,现代架构采用多层数据路径,结合闪存或内存来缓冲数据摄取并优化数据放置。
闪存层吸收来自 API 流量和应用程序写入的可变到达速率。它会在数据移动到存储介质之前对其进行暂存和整理,从而允许后台进程以长时间的顺序方式将其刷新到硬盘阵列。
在 AI 工作负载下,数据摄取、检查点和数据集移动可能特别频繁,因此这种缓冲作用变得更加重要,因为它有助于保持低延迟摄取和高效的硬盘利用率。
图 1.比较传统 POSIX 存储软件与云原生存储软件在最大限度发挥以硬盘为中心的存储架构优势方面的差异。
主存储的新模型
这些架构上的转变共同重塑了主存储的定义。从历史上看,“主存储”通常指的是昂贵、高可用性的块存储或文件系统,它们与计算紧密相连。对象存储通常被视为归档、备份或辅助数据的较低层级目的地。
如今,许多云原生架构对主存储的定义更加广泛:无状态计算与全局对象存储相结合。基于 S3、Azure 和 GCS 等平台构建的数据湖正日益成为大规模分析、云应用程序和 AI 工作流的记录系统。
在这种模式下,主存储越来越依赖软件定义,对象服务、元数据层、闪存缓冲和大容量硬盘作为一个协调的系统协同工作。
计算实例通常被视为更具弹性和无状态的,它们从对象层提取数据,对其进行处理,并将结果写回同一个共享环境。
对象存储与文件语义的融合
过去十年,对象存储对云架构的重要性日益凸显,最近又对人工智能工作流程产生了重要影响,由此出现了另一个重要趋势:高性能并行文件系统。
Lustre、Weka 和 VAST 等系统旨在最大限度地提高紧密耦合工作负载的性能,通常会公开符合 POSIX 标准的接口,以支持检查点、协调和高吞吐量数据访问。
与此同时,对象存储平台也在不断发展——在优化全球可扩展性的同时,不断提升性能,以支持不断扩展的人工智能和数据密集型工作负载。
在大规模云计算和人工智能环境中,这些方法正在趋于融合。高性能文件系统通常叠加在对象存储后端之上,或分层到对象存储后端之中,将活动工作集的性能与对象存储作为记录系统的可扩展性和经济性相结合。
这种融合反映了更广泛的架构转变:现代系统不再在文件和对象之间做出选择,而是将它们结合起来。它保留了文件夹、命名空间和熟悉的文件行为的便利性,同时又不牺牲对象存储的规模优势。
对云计算和人工智能基础设施构建者的影响
综合来看,这些转变指向一个更广泛的结论:云和人工智能架构需要与 POSIX 优先模型最初设计时所追求的优化不同的软件和系统权衡。
这些权衡取舍使得设计软件以优化底层硬盘驱动器群的使用变得尤为重要,因为系统正是建立在这些硬盘驱动器群之上的。从这个意义上讲,云计算和人工智能工作负载不仅改变了存储架构,而且重新定义了主存储本身。
对于基础设施建设者来说,结论很明确:为现代系统进行设计意味着要超越主存储必须与本地操作系统文件树完全对应这一假设。这意味着要选择与大规模人工智能的经济性、物理性和工作负载实际情况相符的软件和访问模式。
能够正确处理这个问题的组织将更有能力高效地执行人工智能战略,获得更高的 GPU 利用率、更好的推理经济效益和更少的性能瓶颈。
了解更多为全球最大的人工智能和云基础设施建设者提供主存储的硬盘创新技术。
来源
1.IDC Datasphere 和 IDC Storagesphere
2.AWS re:Invent 2025,Andy Warfield 主题演讲:S3 存储超过 500 万亿个对象,每秒处理 2 亿个请求,每年处理超过 1 千万亿个请求。