为大规模人工智能部署准备企业数据基础设施
人工智能工作负载会产生海量的结构化和非结构化数据。为了支持训练、推理和再训练周期,企业需要可扩展的高容量存储,以应对持续的数据增长。
没有数据——海量数据——人工智能就不会成功。
没有充足、高效的数据存储,就没有海量数据集。AI 工作负载会创建连续的数据流——从训练数据集和推理日志到元数据、嵌入和模型输出。随着生成式人工智能和大型语言模型(LLM)的扩展,企业数据的数量和种类呈指数级增长。这种快速扩展要求存储架构能够处理持续的数据摄取、高速访问和长期可靠的数据保存。
数据支撑着人工智能,大容量硬盘支撑着数据。
研究公司 Recon Analytics 的一项 2025 年调查清晰地揭示了这些观点。
这项全球调查详细介绍了多个行业的企业如何调整其基础设施以支持人工智能。受访者代表了已经使用或计划使用人工智能的组织,他们就存储需求、扩展挑战和企业数据基础设施的未来提供了见解。
该全球调查由 Seagate 委托开展,涵盖 1,062 名受访者,他们是 IT 存储采购员和决策者,在年收入超过 1000 万美元、当前存储使用量超过 50 TB、已采用人工智能或计划在未来三年内采用人工智能的公司中担任存储基础设施职务,并且位于美国、中国、英国、韩国、新加坡、法国、印度、日本、台湾和德国。
该调查重点关注人工智能应用对基础设施优先级、数据保留和数据管理的影响。其结果揭示了 AI 在未来三年内对基础设施需求的深远影响。
全球调查洞察:人工智能的应用将如何改变数据基础设施
Recon Analytics 的最新调查显示,企业在规划其数据生态系统以迎接人工智能时代时,正在发生重大转变。与其将人工智能视为一项孤立的举措,不如让各组织重新评估存储策略、资源分配和长期基础设施设计,以应对人工智能的加速普及。该调查反映了全球 IT 领导者如何为未来做好准备,未来数据增长、数据保留要求和性能期望将比以往任何时候都增长得更快。
到 2028 年人工智能数据增长情况:人工智能存储需求为何激增?
首先,调查显示,到 2028 年,人工智能的普及将推动数据存储需求呈指数级增长。
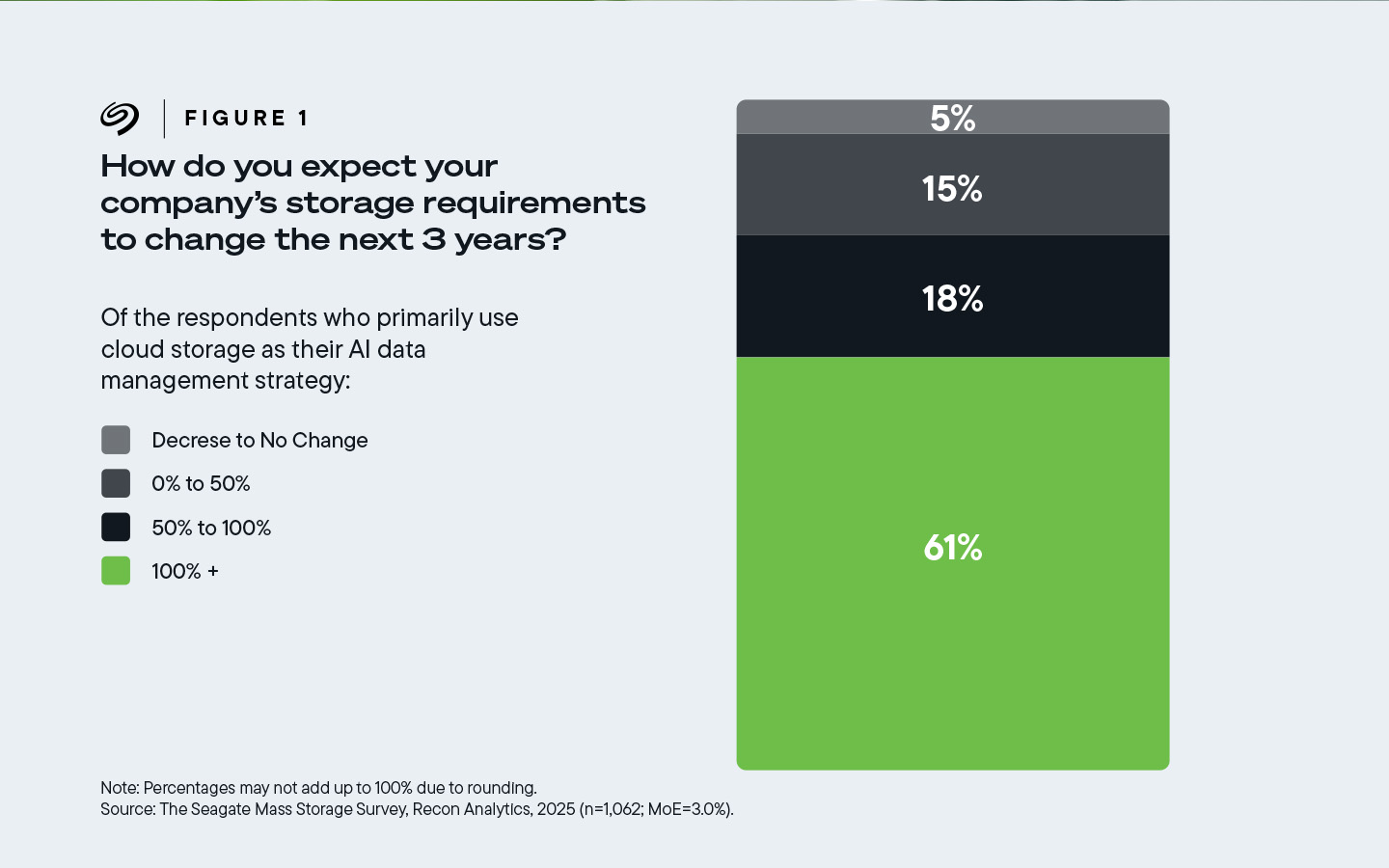
多达 61% 的受访者来自主要使用 云存储的公司,他们表示,未来三年内,他们公司的云存储必须增加 100% 以上 ,也就是说,必须翻一番。
图 1:主要使用云存储进行 AI 数据管理的受访公司中,61% 的人预计其存储需求将增加 100% 或更多。
为什么长期数据保留能够提高人工智能的准确性和可信度
随着人工智能应用带来前所未有的数据创造,企业保存的数据越多,就越能验证人工智能是否按预期运行。通过获取行为数据(如训练数据集、模型检查点、提示和答案),企业可以审查算法,更好地理解和改进人工智能决策。如果数据中心无法实现规模和效率的提升,AI 的潜力将受到限制,因为存储和检索海量数据集的能力是 AI 成功的核心。
人工智能的成功不仅仅取决于存储容量。数据存储时长也很重要。
金融、医疗保健、制造业和政府运营等行业依赖长期留住人才来满足合规要求和审计需求。保留历史数据可以加强治理框架,支持监管报告,并使人工智能输出随着时间的推移更加准确。
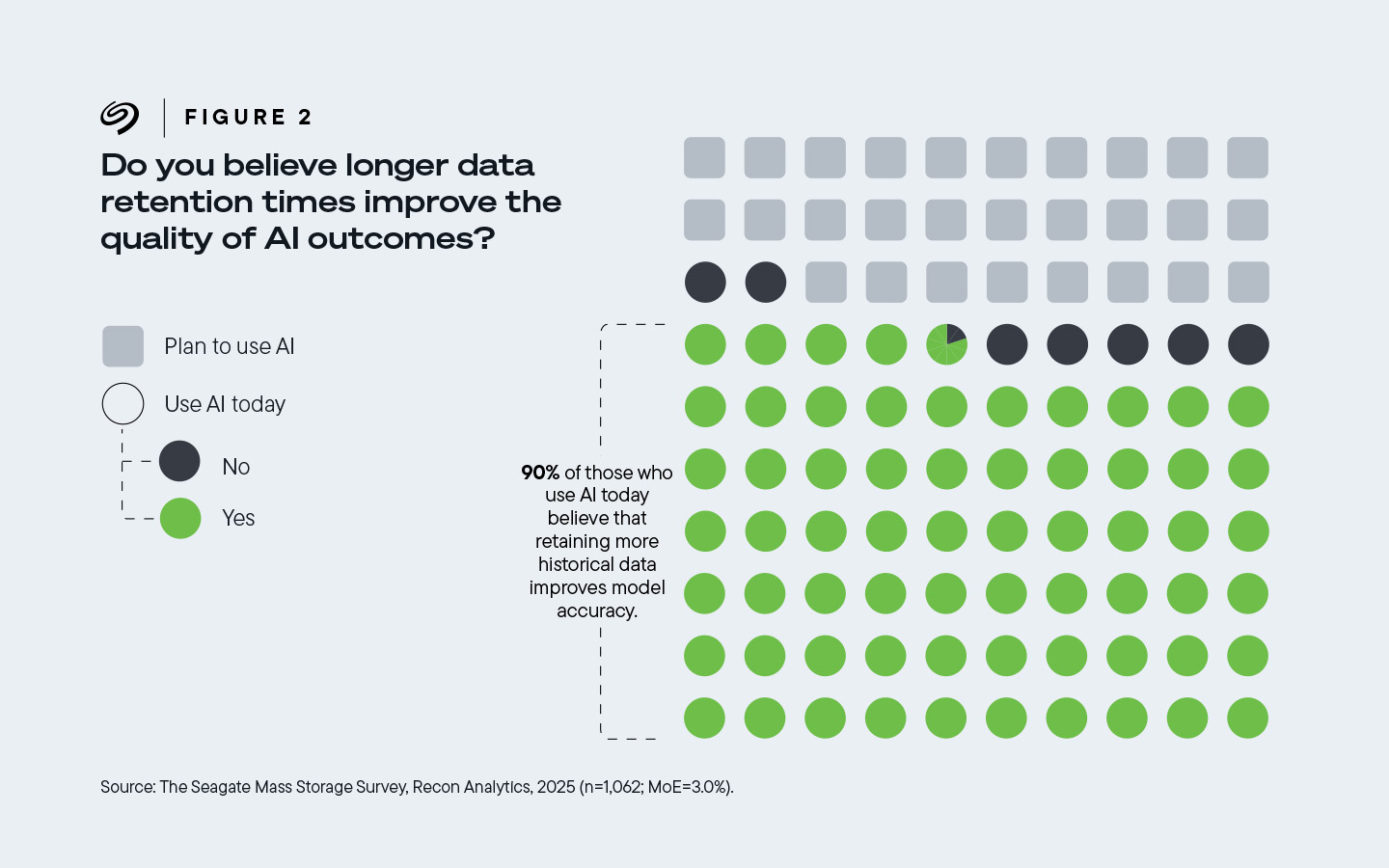
在接受调查的、受雇于已采用人工智能技术的企业的受访者中,90%的人认为更长的数据保留期可以提高人工智能结果的质量 。
图 2:如今,90% 使用人工智能的公司认为,保留更多历史数据可以提高模型准确性。
这一调查结果表明,长期保存数据与更可靠的 AI 洞察之间存在一定关联。这一现象可能由多个因素驱动:首先,AI 算法依赖于持续的迭代处理。内容输出会反馈至模型,不断提升其准确性,并支持新模型的开发。原始数据集及其分析结果也会成为后续优化和新工作流的基础。
数据沿袭、合规性和知识产权保护在可信赖人工智能中的作用
但长期保存数据集还有其他重要的业务功能,因为它可以保护公司的知识产权。它会保留模型原始数据集和过程的“收据”,并在需要时(例如,作为法律程序的一部分)提供结果解释。
这些收据建立了数据沿袭,清晰地记录了数据从输入到输出的路径。数据沿袭使组织能够追踪数据集的来源和使用情况,从而确保人工智能模型建立在准确的数据之上。它使人工智能系统完全可审计,并支持监管合规性和内部问责制。
此外,公司可能会选择存储更多数据更长时间,因为他们意识到,他们今天无法知道明天的算法可能会从昨天的数据中发现哪些新的、有价值的见解。更长的数据保留期使得尚未开发的 AI 模型能够处理旧数据。基于这些原因,更长的数据保留时间可以提升人工智能能够提供的商业价值。
相关研究发现,基础设施决策者认为延长数据保留时间对于建立信任至关重要——没有信任,人工智能洞察就几乎没有价值。
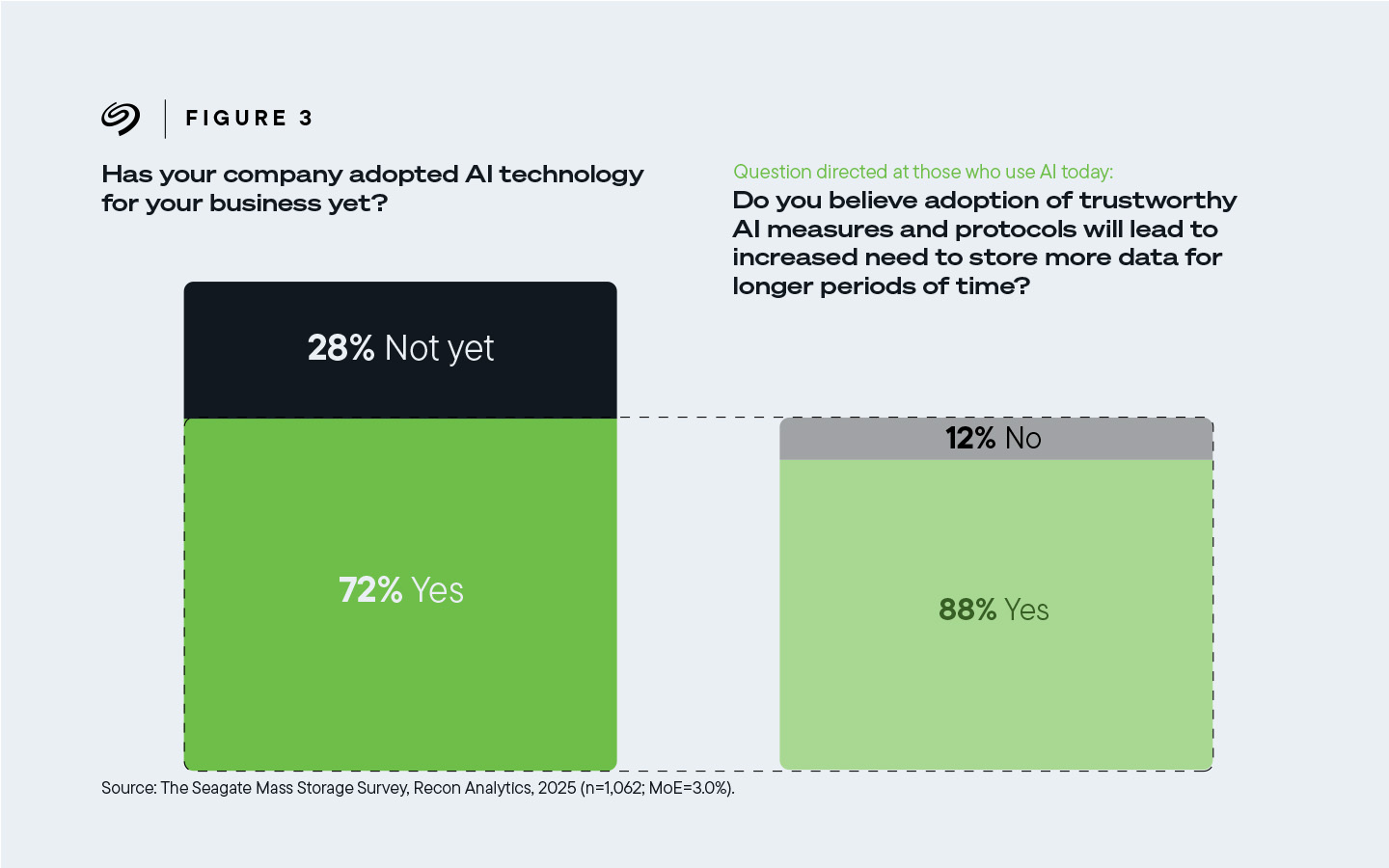
88% 的受访者认为,如今使用人工智能的公司采用可信赖的人工智能会增加存储更多数据并延长存储时间的需求 。
图 3:88% 的受访者表示,他们所在的公司目前使用人工智能,而采用可信赖的人工智能需要存储更多数据并延长存储时间。
Seagate 将 值得信赖的 AI 定义为使用可靠输入并生成可靠见解的 AI 数据工作流和模型。“可信赖 AI”以具备以下要素的数据为支撑:
高质量和高精度
明确的合法性、所有权和来源
安全存储和保护
算法实现可解释和可追溯的转换
数据处理输出结果一致且可靠。
可扩展的存储基础设施能够支持可信赖的人工智能,因为它能够妥善管理、存储和保护人工智能系统使用的大量数据。
作为构建可信任人工智能的一部分,80% 的调查受访者强调了检查点(checkpointing)的重要性。
检查点:为什么频繁的模型快照依赖于可靠的大容量硬盘存储
检查点 是指在 AI 模型训练过程中,以较短的时间间隔保存模型状态的过程。人工智能模型通过迭代过程在大数据集上进行训练,这个过程可能需要几分钟到几个月的时间。模型训练所需时间取决于模型的复杂程度、数据集的大小以及可用的计算能力。在此期间,模型会接收数据,参数会进行调整,系统会根据处理的信息学习如何预测结果。
检查点本质上就像是模型在训练过程中多个阶段的当前状态(数据、参数和设置)的快照。定期保存快照可以保留模型进展的记录,并防止因意外中断而导致的数据丢失。
根据调查,使用 100PB 以上存储空间的公司每天或每周都会保存和备份检查点,其中 87% 的公司将这些检查点存储在云端或硬盘和 SSD 的混合存储中。
为了支持这种规模的检查点,企业需要能够持续进行写入活动而不中断模型进度的存储系统。高容量硬盘和混合云架构提供了维持这些快速快照周期所需的可靠性和成本效益。通过持续捕获和保护检查点,组织可以保障培训进度,加快从中断中恢复的速度,并维持稳定、可预测的 AI 开发工作流程。
存储:可扩展、低成本人工智能系统背后的秘密驱动因素
在 AI 发展趋势的讨论中,计算能力和能源消耗是常见话题。但 Recon Analytics 的调查显示,存储是关键驱动因素。
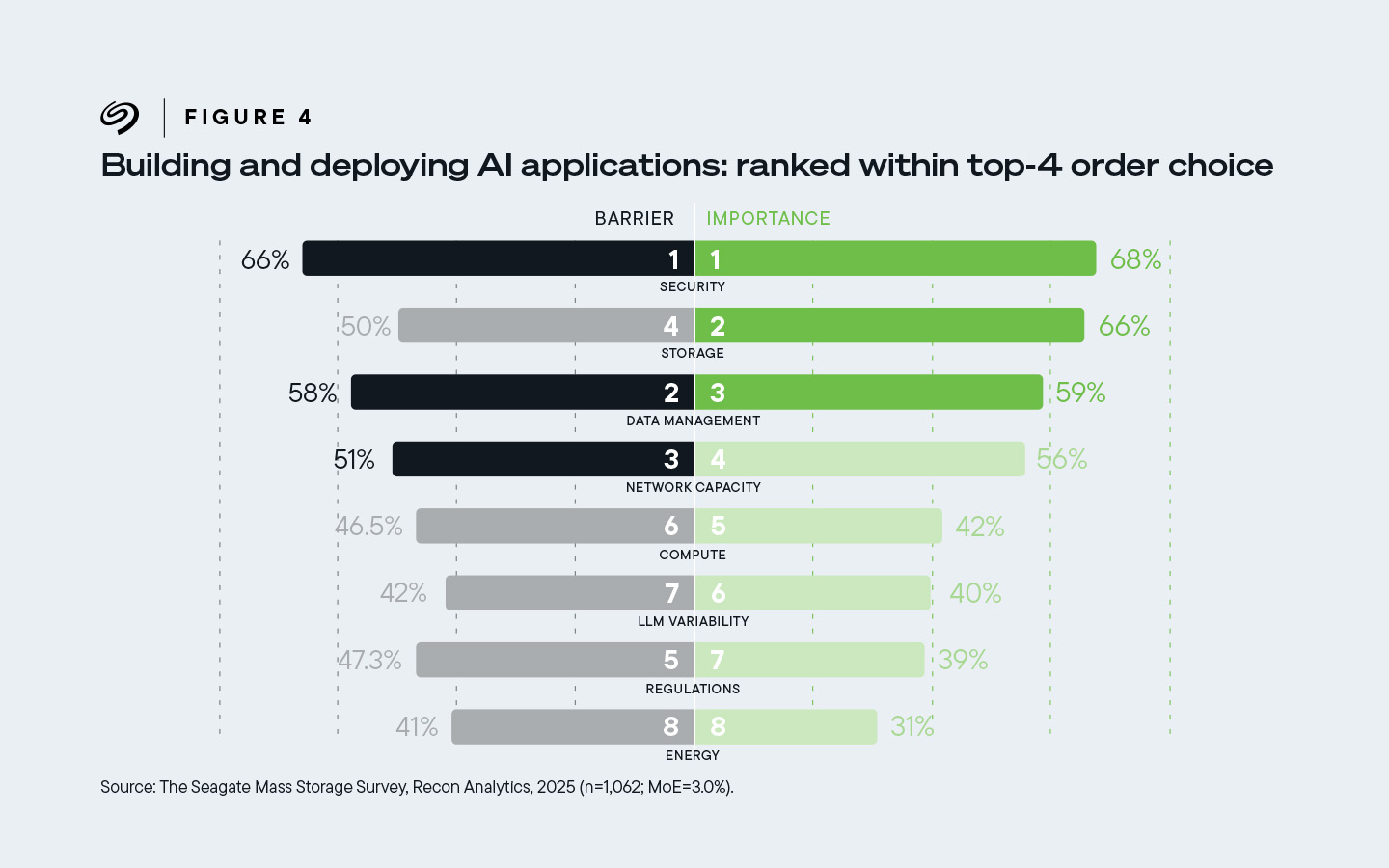
从基础架构采购者的角度来看,数据存储被认为是 AI 基础架构中仅次于安全性的第二大关键因素。按重要性排序,安全和存储之后依次是数据管理、网络容量、计算、法规、LLM 可行性和能源。
三分之二 (66%) 的受访者将存储列为他们认为最重要的四项人工智能推动因素中的第二项,也是采用人工智能的第四大障碍。
图 4:66% 的基础设施决策者将存储列为他们认为最重要的四大人工智能赋能因素中的第二重要组成部分。同时也将其视为 AI 部署的第四大挑战。
“调查结果普遍显示,数据存储需求即将迎来新一轮增长,而硬盘无疑是这一趋势的最大受益者。考虑到我们调查的商业领袖们打算将越来越多的人工智能驱动数据存储在云端,云服务已做好充分准备,迎接第二波增长浪潮。
Recon创始人兼首席分析师Roger Entner将主要结论概括如下:
要充分发挥 AI 的价值,企业必须提前规划,构建可扩展且高效的数据存储。无论是直接还是通过云服务,人工智能对数据的依赖都依赖于硬盘驱动器——硬盘驱动器提供无与伦比的容量、成本效益和可持续性——作为值得信赖的人工智能的支柱 。
硬盘驱动器为大规模人工智能存储提供了无可比拟的每TB成本优势。大容量硬盘在可扩展性、能源效率和可持续性方面实现了最佳平衡,使企业能够在不超出预算或电力限制的情况下扩展存储规模。