Aquí en Seagate, nuestros equipos de ingeniería y yo nos reunimos periódicamente con los mayores constructores de infraestructuras de nube e inteligencia artificial del mundo.
Además de suministrarles exabytes de discos duros de alta capacidad, trabajamos codo con codo con ellos para ayudarles a definir sus arquitecturas de almacenamiento.
Gracias a estas colaboraciones, he podido observar de primera mano cómo se toman las decisiones sobre el almacenamiento a hiperescala. El denominador común es claro: la economía, la orquestación de software y las capacidades del hardware deben estar alineadas para maximizar el rendimiento, la eficiencia y el valor de los datos.
Esa alineación se ha vuelto aún más importante a medida que las cargas de trabajo de IA continúan aumentando el tamaño de los conjuntos de datos, la frecuencia de acceso, las ventanas de contexto, el paralelismo, el tiempo de retención y las exigencias impuestas a los sistemas de almacenamiento compartido.
Estos cambios de escala han transformado radicalmente el significado de "almacenamiento primario".
Históricamente, el almacenamiento primario se refería a sistemas de archivos o de bloques estrechamente acoplados y ubicados cerca de los centros de procesamiento. Sin embargo, en entornos de nube e inteligencia artificial, el almacenamiento primario se define cada vez más mediante arquitecturas distribuidas globalmente y definidas por software que tratan el almacenamiento de objetos como un sistema de registro persistente que retiene y sirve volúmenes masivos de datos en diferentes cargas de trabajo.
Para comprender mejor cómo se desarrolló esta redefinición, analicemos los principios de diseño que originalmente dieron forma al almacenamiento empresarial.
Cómo la escala cambió el paradigma del almacenamiento
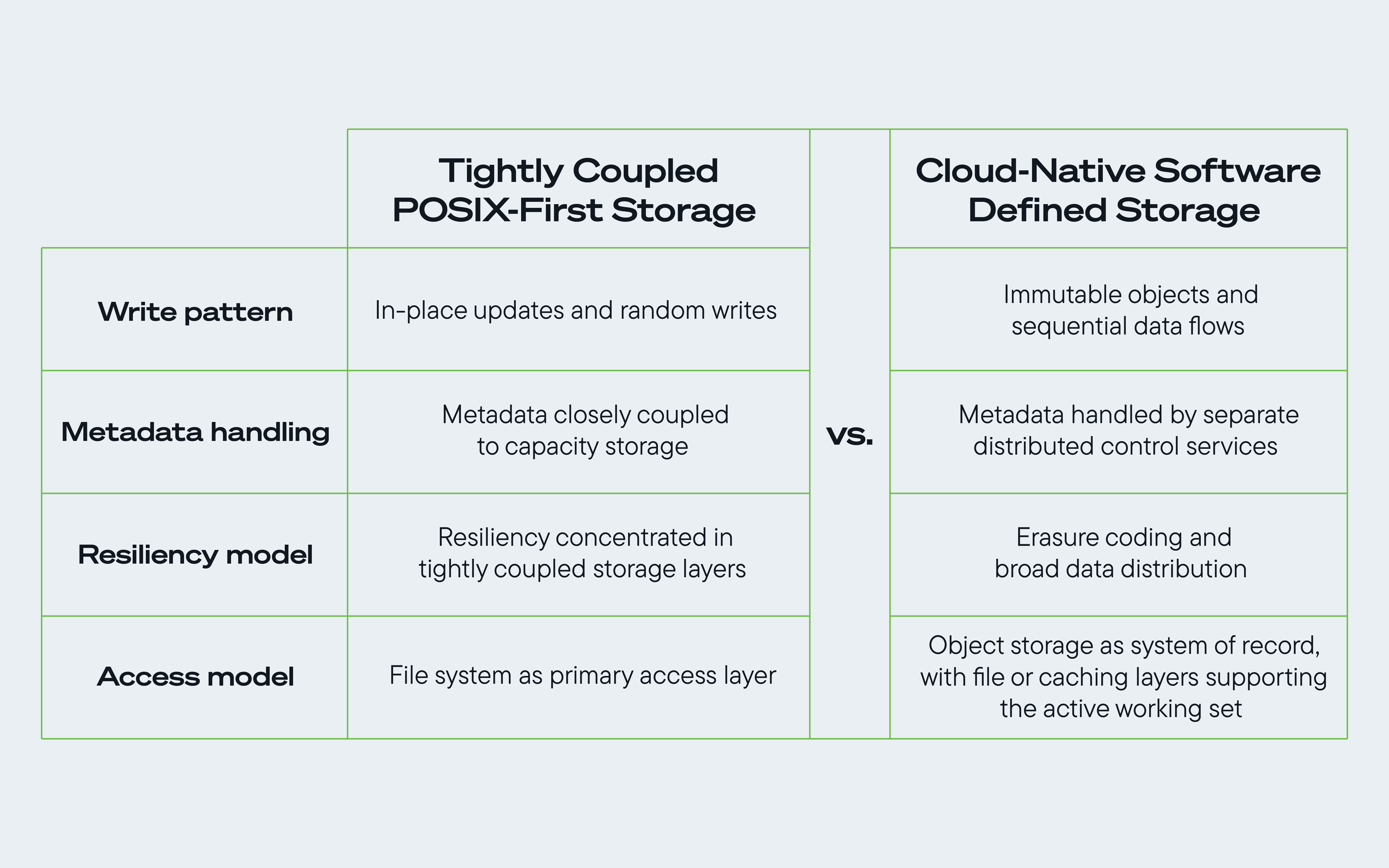
Durante décadas, el ecosistema funcionó bajo un estándar común: la Interfaz de Sistema Operativo Portátil (POSIX). Concebido en una época de infraestructuras más localizadas, POSIX proporcionó a los desarrolladores un modelo predecible para interactuar con los datos.
Hizo hincapié en una sólida consistencia de lectura después de escritura, el bloqueo síncrono de archivos y las estructuras de directorios jerárquicas. Para una sola máquina o un clúster localizado, resultó muy eficaz y sigue siendo fundamental para muchos entornos empresariales y de aplicaciones en la actualidad.
Sin embargo, con la llegada del modelo de la nube, las disyuntivas que regían el sistema cambiaron. Los sistemas a escala de nube se construyeron para una escala, un modelo de distribución y una estructura de costos fundamentalmente diferentes a los que los sistemas basados en POSIX fueron diseñados originalmente para atender.
En un entorno distribuido, las implementaciones de estilo POSIX pueden requerir una orquestación significativa entre los nodos para preservar la semántica de los directorios, el bloqueo de archivos y las actualizaciones in situ.
Las plataformas en la nube necesitaban una escala masiva —que con el tiempo se expandió para admitir decenas o cientos de exabytes— y, en este entorno, la sobrecarga de coordinación de los diseños estrechamente acoplados comenzó a introducir latencia y a imponer límites prácticos al crecimiento.
En las cargas de trabajo de IA modernas, que requieren conjuntos de datos aún mayores, puntos de control, procesamiento de tokens, inferencia y canalizaciones de datos altamente paralelas, esas presiones no han hecho más que intensificarse.
En todo el sector, desde Google Cloud Storage (GCS) y Colossus hasta Microsoft Azure Blob, Amazon S3 y Tectonic de Meta, las plataformas en la nube adoptaron arquitecturas definidas por software diseñadas específicamente para datos distribuidos globalmente y cargas de trabajo a hiperescala, y las perfeccionaron con el tiempo a medida que evolucionaban la escala y los requisitos.
En este nuevo paradigma, el software asume una mayor responsabilidad en la orquestación, la resiliencia y el flujo de datos, de modo que los medios de almacenamiento subyacentes puedan utilizarse de la forma más eficiente posible.
Los discos duros constituyen la base del almacenamiento a gran escala.
En arquitecturas en la nube como las que mencioné anteriormente, los discos duros son la base para almacenar datos a gran escala.
Esto refleja la economía perdurable de la capacidad y la física de la grabación de alta densidad. Los discos duros modernos de alta capacidad incorporan tecnologías como la grabación magnética superpuesta (SMR) y la grabación magnética asistida por calor (HAMR) para seguir aumentando la densidad de área y hacer posible el almacenamiento a escala de exabytes.
A esta escala, las flotas de discos duros sirven como sistema de registro, ofreciendo durabilidad, rentabilidad y densidad volumétrica que las tecnologías de almacenamiento alternativas simplemente no pueden igualar.
¡Hay una razón por la que el 87% de los exabytes de los grandes centros de datos se almacenan en discos duros1!
A medida que las infraestructuras en la nube continúan expandiéndose y las cargas de trabajo de IA consumen, generan, retienen y reutilizan mayores volúmenes de datos, estas ventajas se vuelven aún más importantes.
Pero solo podrán aprovecharse plenamente si la arquitectura del software se diseña para que se ajuste a las ventajas de los discos de alta capacidad.
Los patrones de acceso POSIX tradicionales, especialmente dentro de los modelos de sistemas de archivos distribuidos estrechamente acoplados que enfatizan las actualizaciones fragmentadas, aleatorias e in situ, no siempre se ajustan bien a esas ventajas a gran escala.
Las plataformas modernas de nube definidas por software abordaron este problema diseñando sus pilas de almacenamiento en torno a discos duros, lo que les permite priorizar los flujos de datos secuenciales de alto rendimiento al tiempo que admiten una economía operativa escalable.
En el caso de Amazon S3, un servicio que almacena 500 billones de objetos y atiende 200 millones de solicitudes por segundo, una reciente presentación magistral de AWS re:Invent2 enfatizó que el secreto del rendimiento del almacenamiento en la nube es escribir software que optimice las capacidades del disco duro, descrito en la presentación como una "maravilla de la ingeniería".
En lugar de obligar a la unidad a adaptarse a abstracciones de software diseñadas para una época diferente, las arquitecturas modernas en la nube están diseñadas para complementar las ventajas de los discos duros modernos de alta densidad.
Cómo las arquitecturas en la nube optimizan la eficiencia de los discos duros
Este diseño de ingeniería adoptó diversas formas, pero en las principales plataformas en la nube generalmente refleja cuatro principios arquitectónicos. En conjunto, demuestran cómo el almacenamiento en la nube se ha vuelto cada vez más dependiente del software en la forma en que gestiona el flujo de datos, los metadatos, la resiliencia y el comportamiento de ingesta.
1. La inmutabilidad de los objetos favorece los flujos de datos secuenciales.
Servicios como GCS y Amazon S3 están diseñados para admitir la inmutabilidad de los objetos y las actualizaciones versionadas. Una vez que los datos se escriben en un almacén de objetos, las actualizaciones generalmente se gestionan escribiendo una nueva versión del objeto en lugar de modificar la existente.
Al reducir la necesidad de escrituras binarias aleatorias in situ, las arquitecturas a escala de la nube desplazan una mayor parte de la carga de trabajo del disco hacia flujos de datos secuenciales de gran tamaño. Eso se ajusta mejor a la forma en que las unidades de alta capacidad ofrecen rendimiento y eficiencia a gran escala. El beneficio se vuelve aún más importante en cargas de trabajo de IA, donde los puntos de control, el movimiento de conjuntos de datos y las canalizaciones paralelas pueden generar una presión constante sobre los sistemas de almacenamiento compartido.
2. Los metadatos son gestionados cada vez más por servicios de control separados o distribuidos.
En un entorno POSIX tradicional, los sistemas de almacenamiento suelen gestionar tanto los metadatos de los archivos como el contenido de los mismos de forma estrechamente vinculada. Las plataformas de nube a hiperescala cambiaron esto al separar los servicios de metadatos del almacenamiento de capacidad, trasladando gran parte del seguimiento y la coordinación a capas de control más rápidas y escalables, en lugar de dejar esa carga en los propios discos.
Colossus de Google Cloud traslada gran parte de este trabajo a servicios residentes en memoria, mientras que Tectonic de Meta separa los metadatos —dentro de un modelo de sistema de archivos distribuido— en microservicios sin estado que se ejecutan en un almacén de clave-valor escalable horizontalmente. El resultado es una menor carga estructural en los discos duros subyacentes y una mayor oportunidad para que estos ofrezcan una capacidad densa y eficiente a gran escala.
3. La codificación de borrado fortalece la resiliencia distribuida.
Un tercer principio es el uso de la codificación de borrado y la distribución amplia de datos para hacer que los sistemas de almacenamiento a gran escala sean más resistentes y eficientes.
Las arquitecturas en la nube reducen esa sensibilidad mediante la codificación de borrado y la distribución amplia de datos. Al distribuir los objetos entre varios discos, estos sistemas pueden aislar los puntos críticos localizados, seguir sirviendo datos a través de breves picos de latencia y reconstruirlos según sea necesario. Esto hace que la capa de almacenamiento sea más resistente y ayuda a mantener el rendimiento bajo cargas de trabajo mixtas de nube e IA.
4. La ruta de datos de múltiples niveles
Un cuarto principio es cómo se organizan los datos antes de que lleguen a los medios de almacenamiento.
Para salvar la brecha entre el tráfico impredecible de las aplicaciones y el entorno estructurado que mejor manejan los discos duros de alta densidad, las arquitecturas modernas utilizan una ruta de datos de varios niveles, que incorpora memoria flash o memoria RAM para almacenar en búfer la ingesta y optimizar la ubicación de los datos.
Una capa flash absorbe las tasas de llegada variables del tráfico de la API y las escrituras de la aplicación. Este proceso organiza y procesa los datos entrantes antes de que se transfieran a los medios de almacenamiento, lo que permite que los procesos en segundo plano los transfieran a las matrices de discos duros en largas pasadas secuenciales.
En cargas de trabajo de IA, donde la ingesta, el establecimiento de puntos de control y el movimiento de conjuntos de datos pueden ser especialmente intermitentes, esta función de almacenamiento en búfer se vuelve aún más importante, ya que ayuda a preservar tanto la ingesta de baja latencia como la utilización eficiente del disco duro.
Figura Comparación entre el software de almacenamiento POSIX tradicional y el software de almacenamiento nativo en la nube para maximizar los beneficios de una arquitectura de almacenamiento centrada en discos duros.
Un nuevo modelo para el almacenamiento primario
En conjunto, estos cambios arquitectónicos han transformado la forma en que se define el almacenamiento primario. Históricamente, el término "almacenamiento primario" solía referirse a sistemas de archivos o bloques costosos y de alta disponibilidad, conectados directamente a la infraestructura informática. El almacenamiento de objetos se consideraba más comúnmente un destino de nivel inferior para el archivo, la copia de seguridad o los datos secundarios.
Actualmente, muchas arquitecturas nativas de la nube definen el almacenamiento primario de forma más amplia: computación sin estado combinada con un almacén de objetos global. Los lagos de datos construidos sobre plataformas como S3, Azure y GCS sirven cada vez más como sistema de registro para análisis a gran escala, aplicaciones en la nube y flujos de trabajo de IA.
En este modelo, el almacenamiento principal se define cada vez más por software, con servicios de objetos, capas de metadatos, almacenamiento en búfer flash y discos duros de alta capacidad que trabajan juntos como un sistema coordinado.
Las instancias de computación suelen considerarse más elásticas y sin estado, ya que extraen datos de la capa de objetos, los procesan y escriben los resultados de vuelta en el mismo entorno compartido.
La convergencia del almacenamiento de objetos y la semántica de archivos
A medida que el almacenamiento de objetos se ha vuelto más fundamental para las arquitecturas en la nube durante la última década y, más recientemente, para los flujos de trabajo de IA, ha surgido otra tendencia importante: los sistemas de archivos paralelos de alto rendimiento.
Sistemas como Lustre, Weka y VAST están diseñados para maximizar el rendimiento en cargas de trabajo estrechamente acopladas, y a menudo exponen interfaces compatibles con POSIX para admitir puntos de control, coordinación y acceso a datos de alto rendimiento.
Al mismo tiempo, las plataformas de almacenamiento de objetos han seguido evolucionando, optimizándose para la escalabilidad global a la vez que mejoran el rendimiento para dar soporte a un conjunto cada vez mayor de cargas de trabajo de IA y con uso intensivo de datos.
En entornos de nube e inteligencia artificial a gran escala, estos enfoques están convergiendo. Los sistemas de archivos de alto rendimiento suelen superponerse o integrarse en los sistemas de almacenamiento de objetos, combinando el rendimiento para el conjunto de trabajo activo con la escalabilidad y la economía del almacenamiento de objetos como sistema de registro.
Esta convergencia refleja un cambio arquitectónico más amplio: en lugar de elegir entre archivo y objeto, los sistemas modernos los combinan. Conserva la comodidad de las carpetas, los espacios de nombres y los comportamientos de archivo habituales sin sacrificar las ventajas de escalabilidad del almacenamiento de objetos.
Implicaciones para los desarrolladores de infraestructura en la nube y la IA
En conjunto, estos cambios apuntan a una conclusión más amplia: las arquitecturas de nube e IA requieren compromisos de software y sistema diferentes a los que los modelos POSIX-first fueron diseñados originalmente para optimizar.
Estas compensaciones aumentaron la importancia de diseñar software para optimizar el uso de las flotas de discos duros subyacentes sobre las que se basan los sistemas. En ese sentido, las cargas de trabajo en la nube y de IA no solo han alterado la arquitectura de almacenamiento, sino que han redefinido el almacenamiento primario en sí mismo.
Para los constructores de infraestructuras, la conclusión es clara: diseñar para sistemas modernos significa ir más allá de la suposición de que el almacenamiento principal debe asignarse de forma precisa a un árbol de archivos del sistema operativo local. Significa elegir software y modelos de acceso que se ajusten a las realidades económicas, físicas y de carga de trabajo de la IA a gran escala.
Las organizaciones que lo hagan bien estarán mejor posicionadas para ejecutar estrategias de IA de manera eficiente, con una mayor utilización de la GPU, una mejor economía de inferencia y menos cuellos de botella en el rendimiento.
Descubra más sobre la innovación en discos duros que impulsa el almacenamiento principal de los mayores desarrolladores de infraestructura en la nube y de IA del mundo.
Fuentes
1. IDC Datasphere e IDC Storagesphere
2. AWS re:Invent 2025, Conferencia magistral de Andy Warfield: S3 almacena más de 500 billones de objetos, atiende 200 millones de solicitudes por segundo y procesa más de 1 cuatrillón de solicitudes al año.