Principaux éléments à retenir :
- Les performances et le coût des inférences sont de plus en plus influencés par la mémoire et les déplacements de données.
- L'IA agentique nécessite un contexte persistant et de longue durée, ce qui requiert un stockage sur disque dur de grande capacité.
- Les architectures multi-niveaux (disques durs + mémoire GPU + SSD NVMe) permettent de faire évoluer le contexte sans engendrer de coûts exorbitants.
L'IA agentique est apparue comme la prochaine frontière opérationnelle de la valeur.
Les dirigeants d'organisations ont besoin de systèmes d'IA capables de planifier, d'agir et de s'améliorer au fil du temps — des agents qui exécutent des flux de travail en plusieurs étapes et produisent des résultats commerciaux essentiels.
Mais à mesure que la complexité et le volume des requêtes augmentent, les limites de la conservation du contexte sur lesquelles s'appuient ces agents deviennent difficiles à ignorer.
Les agents peuvent devenir oublieux, non pas parce que le modèle en est incapable, mais parce que sa mémoire contextuelle utilisable et persistante est limitée.
L'écosystème de l'IA a un nom pour cela : le mur de contexte.
Le mur de contexte est le point où un agent se retrouve à court de contexte de travail et doit résumer, abandonner des informations ou récupérer et revérifier à plusieurs reprises des faits précédemment consultés. Cela ralentit le raisonnement, augmente les coûts et dégrade souvent la qualité. Résultat : des réponses incohérentes et des pistes de réflexion perdues.
Le mur de contexte devient rapidement un problème commercial. Cela apparaît comme :
- Des coûts de calcul plus élevés (plus de retouches, plus de cycles de récupération, plus de jetons)
- Réponses plus lentes (latence due au recalcul ou au rechargement du contexte)
- Faible confiance (comportement incohérent d'une session à l'autre)
- Limites de capacité (les agents ne peuvent pas prendre en charge des tâches à long terme)
La mise à l'échelle du mur de contexte ne concerne que partiellement l'amélioration des modèles. Il s'agit principalement de la manière dont vous stockez et fournissez le contexte.
La solution conjointe pour l'IA agentive
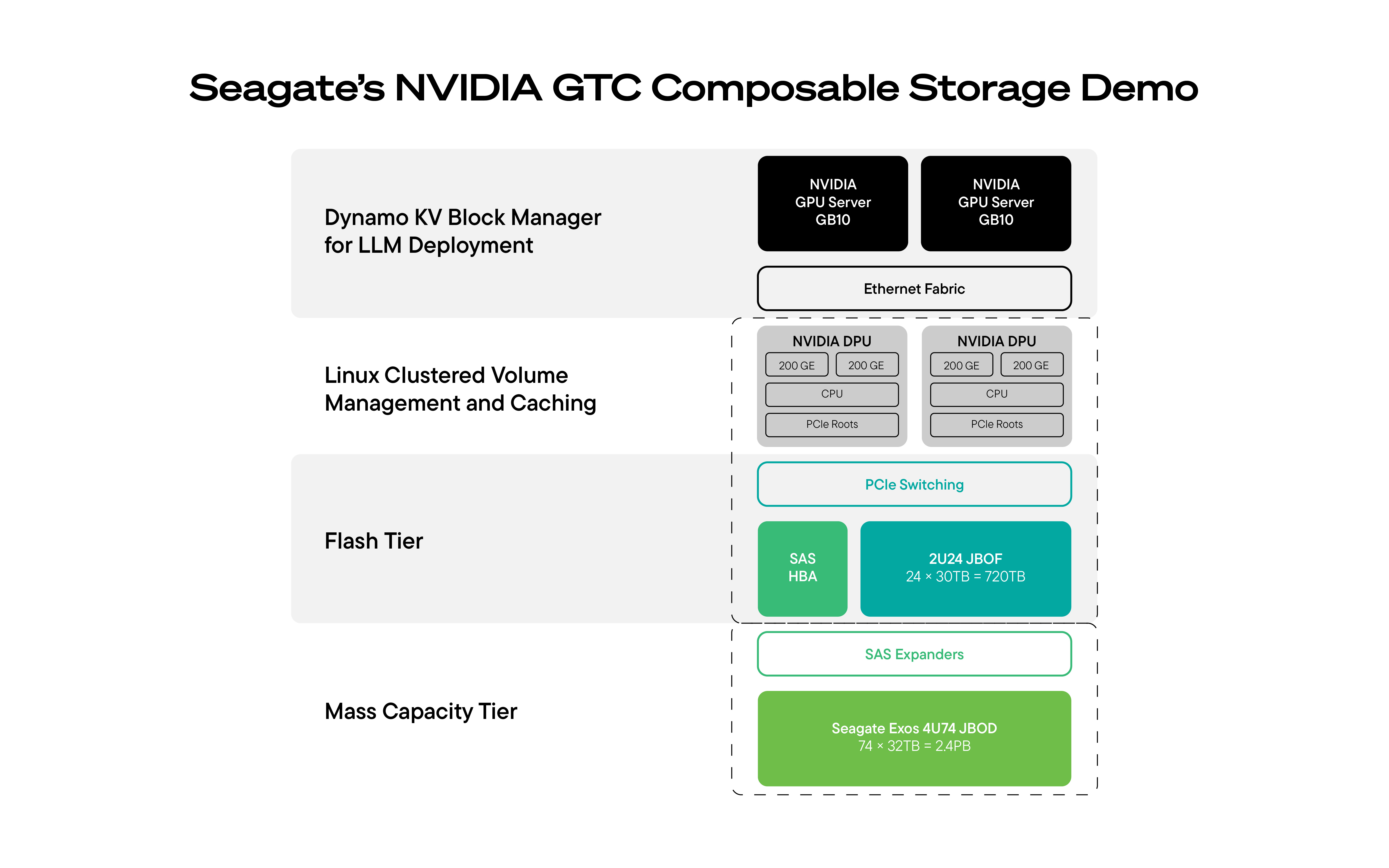
Pour relever ce défi, Seagate et ses partenaires ont présenté lors de la NVIDIA GTC une solution de stockage IA multi-niveaux disponible sur le marché et prête pour la production, conçue pour étendre le contexte des charges de travail d'IA.
La solution présentée au GTC combinait :
- Nœud de calcul du cluster GPU NVIDIA DGX Spark exécutant l'inférence à grande échelle
- Supermicro JBOF comme couche de cache SSD NVMe réseau haute vitesse pour maintenir le contexte immédiat à proximité du calcul
- Disque dur Seagate JBOD pour une couche de stockage de données évolutive et haute capacité, offrant un contexte durable à un prix abordable.
- NVIDIA BlueField-3 ou NVIDIA BlueField-4 DPU pour décharger et accélérer le déplacement et la mise en cache des données entre le stockage et le placement direct des données dans la mémoire GPU
- Composants open source orchestrés par le DPU (NVIDIA Dynamo) pour mettre en cache intelligemment les ensembles de données résidant sur le disque dur via des SSD
Cette architecture est importante non seulement parce qu'elle élargit le contexte, mais aussi parce qu'elle redéfinit la manière dont les organisations devraient envisager l'économie de l'inférence en IA. Une fois les charges de travail des agents déployées en production, la mémoire et le déplacement des données deviennent essentiels pour les performances, les coûts et la fiabilité, et non plus seulement pour la qualité du modèle.
« L’association de la couche flash JBOF de Supermicro et de la couche disque dur de Seagate permet de réduire considérablement les coûts d’inférence tout en offrant des performances élevées », a déclaré Vik Malyala, président et directeur général pour la zone EMEA, et vice-président senior en charge de la technologie et de l’IA chez Supermicro. « Ceci est particulièrement important à mesure que l'IA agentielle se généralise et que les charges de travail d'inférence augmentent de façon exponentielle. »
Transformer la mémoire en avantage concurrentiel
Voici le changement qu'il est facile de manquer : l'inférence devient autant un problème de mémoire qu'un problème de calcul. Les GPU sont puissants, mais pour être productifs, ils ont besoin des bonnes données, livrées au bon moment, à la bonne vitesse et au bon prix.
Les agents ont besoin de davantage de stockage de contexte. En plus des messages d'avertissement, ils doivent également assurer le suivi des éléments suivants :
- Longue conversation et historique des décisions
- Politiques et procédures
- Connaissance des produits et du dépannage
- Journaux, tickets et télémétrie
Tenter de tout conserver dans la couche d'accès immédiat (mémoire GPU ou mémoire flash intégrale) revient à exiger d'une entreprise entière qu'elle fonctionne avec un service de livraison express premium : idéal pour quelques colis, mais financièrement absurde à grande échelle.
L'approche gagnante repose sur des architectures de stockage permanent à plusieurs niveaux.
Pourquoi le stockage multiniveau est la solution pratique
Une architecture d'IA intelligente sépare la mémoire à court terme de la mémoire à long terme et utilise chaque niveau pour ce qu'il fait le mieux :
- Niveaux d'accès en temps réel (mémoire HBM du GPU, DRAM du CPU, SSD NVMe locaux et réseau) : gèrent le contexte immédiat — jetons actifs, intégrations fréquemment utilisées et données fréquemment consultées
- Niveaux de capacité (construits à partir de disques durs) : stockent le contexte à long terme — grands ensembles de données, historiques de longue durée et mémoire étendue des agents
La valeur commerciale repose sur un principe simple : automatiser le placement des données sur tous les niveaux. Vous assurez une utilisation optimale des GPU, des coûts maîtrisés et un contexte approfondi.
Comment les DPU optimisent le plan de données
Historiquement, la combinaison des niveaux de performance et des niveaux de capacité pour l'IA a été complexe. Cela nécessitait souvent des systèmes de fichiers propriétaires complexes, une charge CPU importante et un réglage délicat, surtout lorsque les volumes de données augmentaient considérablement.
Cela est en train de changer grâce aux unités de traitement de données (DPU).
Les DPU peuvent décharger et accélérer le déplacement des données, de sorte que le système ne consomme pas de cycles CPU hôte uniquement pour déplacer des octets. Ils permettent des modèles d'accès réseau et de stockage à haut débit, et ils peuvent exécuter des services Linux standard pour la mise en cache, la hiérarchisation, la résilience et la sécurité. En bref, les DPU contribuent à rendre le stockage IA multiniveau déployable et évolutif.
C’est ce qui rend une conception à plusieurs niveaux viable à l’échelle de la production.
Ce que permet l'architecture multi-niveaux
L'architecture Seagate, Supermicro et NVIDIA réunit les composants essentiels nécessaires pour étendre le contexte de l'IA à grande échelle et de manière rentable : Calcul GPU pour l'inférence, disques durs pour un contexte de grande capacité et de longue durée, SSD NVMe pour un accès immédiat et DPU pour coordonner le déplacement et la mise en cache des données entre les différents niveaux.
Cette combinaison favorise les résultats commerciaux qui importent le plus aux clients.
Un contexte agentiel plus approfondi signifie une meilleure valeur commerciale
Que signifie cette approche pour les clients ?
1. Une meilleure mémoire stockée par l'agent — et de meilleurs résultats
Les agents peuvent accéder à beaucoup plus de données historiques que ne peut en contenir le stockage adjacent au GPU. Cela favorise un raisonnement à plus long terme, une personnalisation plus riche et réduit les erreurs dues à un contexte oublié.
2. Contexte de réduction des coûts
Les disques durs offrent un coût par téraoctet nettement inférieur pour la mémoire à long terme. C'est important car les ensembles de données et les historiques des agents s'accroissent continuellement.
3. L'efficacité comme prochaine frontière de l'optimisation
Les organisations suivent les performances (jetons par seconde) ainsi que l'efficacité, notamment grâce à des indicateurs tels que la consommation d'énergie par jeton et l'utilisation soutenue du GPU. Les architectures multi-niveaux permettent de réduire le travail inutile (rechargement, retraitement, récupération) et de maintenir la productivité des GPU.
4. Alignement avec l'évolution de l'infrastructure d'IA
Les plans de données pilotés par DPU deviennent un élément central de la conception des systèmes d'IA modernes. Cette approche s'inscrit dans cette direction : concevoir une solution permettant une diffusion de données à grande échelle, et non pas seulement une puissance de calcul brute.
Des preuves, pas des promesses : La démo GTC et la suite
Lors de la GTC, cette architecture a été présentée dans un système en fonctionnement : des GPU pour l’inférence, des disques durs pour un contexte massif et approfondi, des SSD pour un accès immédiat et des DPU orchestrant le déplacement et la mise en cache efficaces des données.
L'IA n'en est encore qu'à ses débuts. Il continuera à consommer et à générer des volumes massifs de données. Ensemble, Seagate, Supermicro et NVIDIA rendent possible cet avenir grâce à des architectures plus durables, plus efficaces et conçues pour une mise à l'échelle optimale.
Les organisations qui réussiront à déployer leurs agents à grande échelle seront celles qui considèrent le contexte comme un atout stratégique et qui mettent en place une infrastructure capable de stocker et de diffuser efficacement ce contexte.
Discutez avec un expert de la façon dont Seagate peut permettre à votre organisation de faire évoluer le mur de contexte agentique.






-v4.png/_jcr_content/renditions/4-3-small-416x312.png)