Biedt onze VAR's, integrators, wederverkopers en andere kanaalpartners toegang tot producttrainingen, sales- en marketingmateriaal, dealregistratie en nog meer.
De bedrijfsgegevensinfrastructuur voorbereiden op AI op grote schaal
AI-workloads genereren enorme hoeveelheden gestructureerde en ongestructureerde gegevens. Om trainings-, inferentie- en hertrainingscycli te ondersteunen, hebben ondernemingen behoefte aan schaalbare opslag met een hoge capaciteit die de voortdurende groei van gegevens kan verwerken.
Zonder data – en dan vooral heel veel data – is succes met AI onmogelijk.
En enorme datasets bestaan niet zonder voldoende en efficiënte dataopslag. AI-workloads genereren continue datastromen — van trainingsdatasets en inferentielogboeken tot metadata, embeddings en modeloutputs. Naarmate generatieve AI en grote taalmodellen (LLM's) zich verder ontwikkelen, nemen de omvang en diversiteit van bedrijfsgegevens exponentieel toe. Deze snelle schaalvergroting vereist opslagarchitecturen die constante invoer, snelle toegang en betrouwbare bewaring op lange termijn aankunnen.
Data vormt de basis van AI en harde schijven met grote capaciteit dragen bij aan de opslag van data.
Deze inzichten worden duidelijk in beeld gebracht door een onderzoek uit 2025 van onderzoeksbureau Recon Analytics.
Het wereldwijde onderzoek biedt details over hoe ondernemingen in verschillende sectoren hun infrastructuur aanpassen om AI te ondersteunen. De respondenten vertegenwoordigen organisaties die al gebruikmaken van AI of van plan zijn dit te gaan doen, en bieden inzicht in opslagbehoeften, schaalbaarheidsuitdagingen en de toekomst van de gegevensinfrastructuur van ondernemingen.
Voor het wereldwijde onderzoek dat in opdracht van Seagate werd uitgevoerd, werden 1.062 respondenten ondervraagd. Het betreft IT-opslaginkopers en besluitvormers die werkzaam zijn in opslaginfrastructuurfuncties bij bedrijven met een jaaromzet van meer dan $10 miljoen, een huidig opslaggebruik van meer dan 50 terabyte (TB), die AI hebben geïmplementeerd of van plan zijn dit binnen de komende drie jaar te doen, en die gevestigd zijn in de Verenigde Staten, China, het Verenigd Koninkrijk, Zuid-Korea, Singapore, Frankrijk, India, Japan, Taiwan en Duitsland.
Het onderzoek richtte zich op de effecten van de invoering van AI op infrastructuurprioriteiten, gegevensbewaring en gegevensbeheer. De resultaten werpen licht op de manier waarop AI de komende drie jaar van invloed zal zijn op de infrastructuurbehoeften.
Wereldwijde enquête-inzichten: Hoe de invoering van AI de data-infrastructuur zal transformeren
Het meest recente onderzoek van Recon Analytics onthult een cruciale verschuiving in de manier waarop ondernemingen hun data-ecosystemen plannen voor het AI-tijdperk. In plaats van AI als een op zichzelf staand initiatief te beschouwen, herzien organisaties nu hun opslagstrategieën, toewijzing van middelen en ontwerp van langetermijninfrastructuur in reactie op de versnelde acceptatie van AI. Het onderzoek geeft weer hoe wereldwijde IT-leiders zich voorbereiden op een toekomst waarin de groei van gegevens, de vereisten voor gegevensbewaring en de prestatieverwachtingen sneller dan ooit tevoren zullen toenemen.
Groei van AI-gegevens tot 2028: Waarom de vraag naar AI-opslag sterk toeneemt
Allereerst toonde het onderzoek aan dat de adoptie van AI zorgt voor een exponentiële groei in de vraag naar dataopslag tot en met 2028.
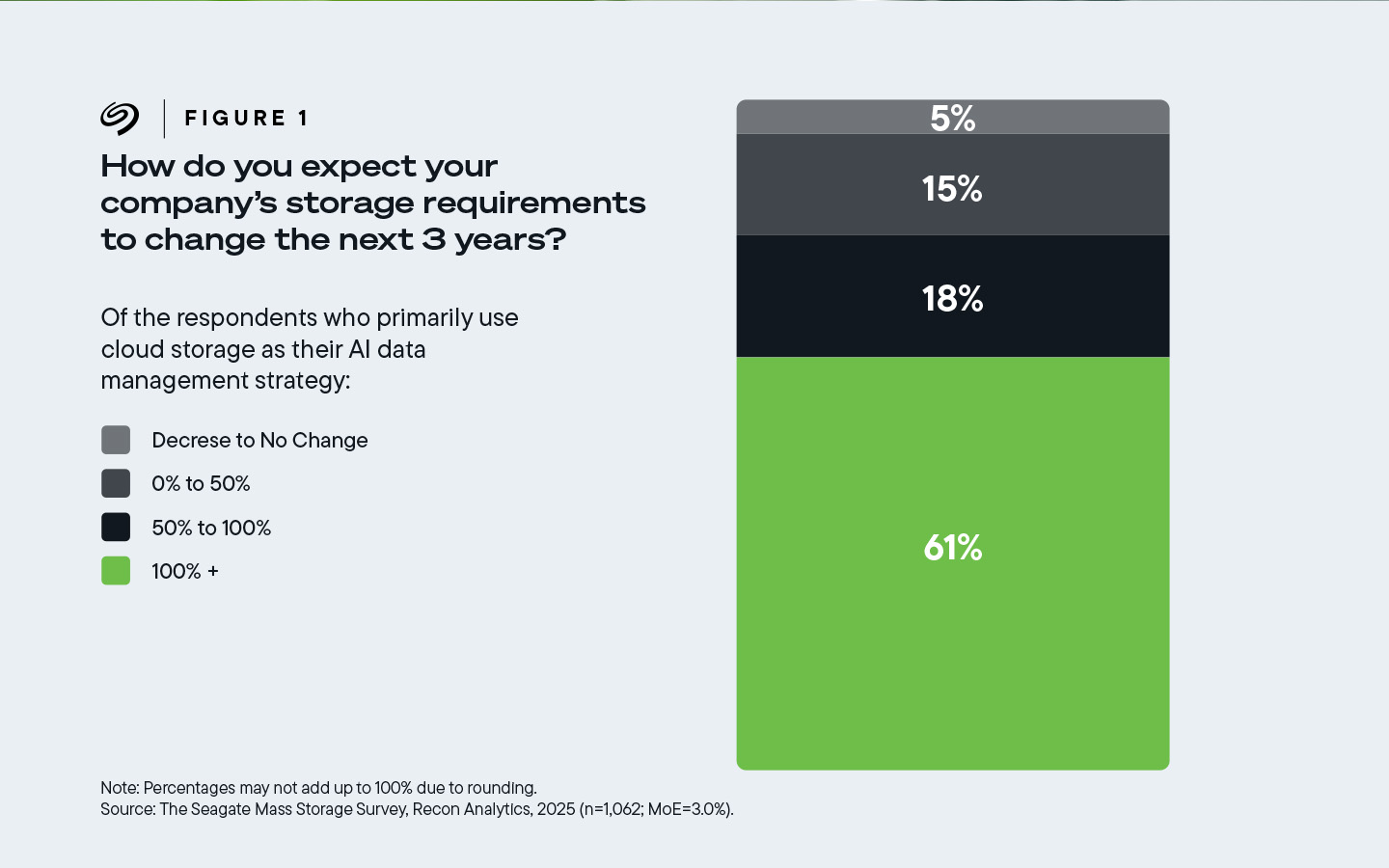
Maar liefst 61% van de respondenten van bedrijven die voornamelijk gebruikmaken van cloudopslag, gaf aan dat de cloudopslag van hun bedrijven de komende drie jaar met meer dan 100% zou moeten toenemen, oftewel zou moeten verdubbelen.
Afbeelding 1. 61% van de respondenten, wier bedrijven voornamelijk cloudopslag gebruiken voor het beheer van hun AI-gegevens, verwacht dat hun opslagbehoeften met 100% of meer zullen toenemen.
Waarom langdurige gegevensopslag de nauwkeurigheid en betrouwbaarheid van AI verbetert
Naarmate AI-toepassingen een ongekende hoeveelheid data genereren, geldt: hoe meer data organisaties opslaan, hoe beter ze kunnen controleren of de AI zich gedraagt zoals verwacht. Met toegang tot gedragsgegevens – zoals trainingsdatasets, modelcontrolepunten, prompts en antwoorden – kunnen bedrijven algoritmen nauwkeurig analyseren en de besluitvorming van AI beter begrijpen en verfijnen. Zonder de schaal en efficiëntie van datacenters zou het potentieel van AI beperkt zijn, omdat het vermogen om enorme gegevenssets op te slaan en op te vragen essentieel is voor het succes van AI.
Het is niet alleen de hoeveelheid opslagruimte die het succes van AI bepaalt. Ook de bewaartijd van de gegevens is van belang.
Sectoren zoals de financiële sector, de gezondheidszorg, de productiesector en overheidsinstanties zijn afhankelijk van langdurige opslag om te voldoen aan nalevingsvereisten en auditbehoeften. Het bewaren van historische gegevens versterkt governancekaders, ondersteunt wettelijke rapportage en maakt AI-outputs in de loop van de tijd nauwkeuriger.
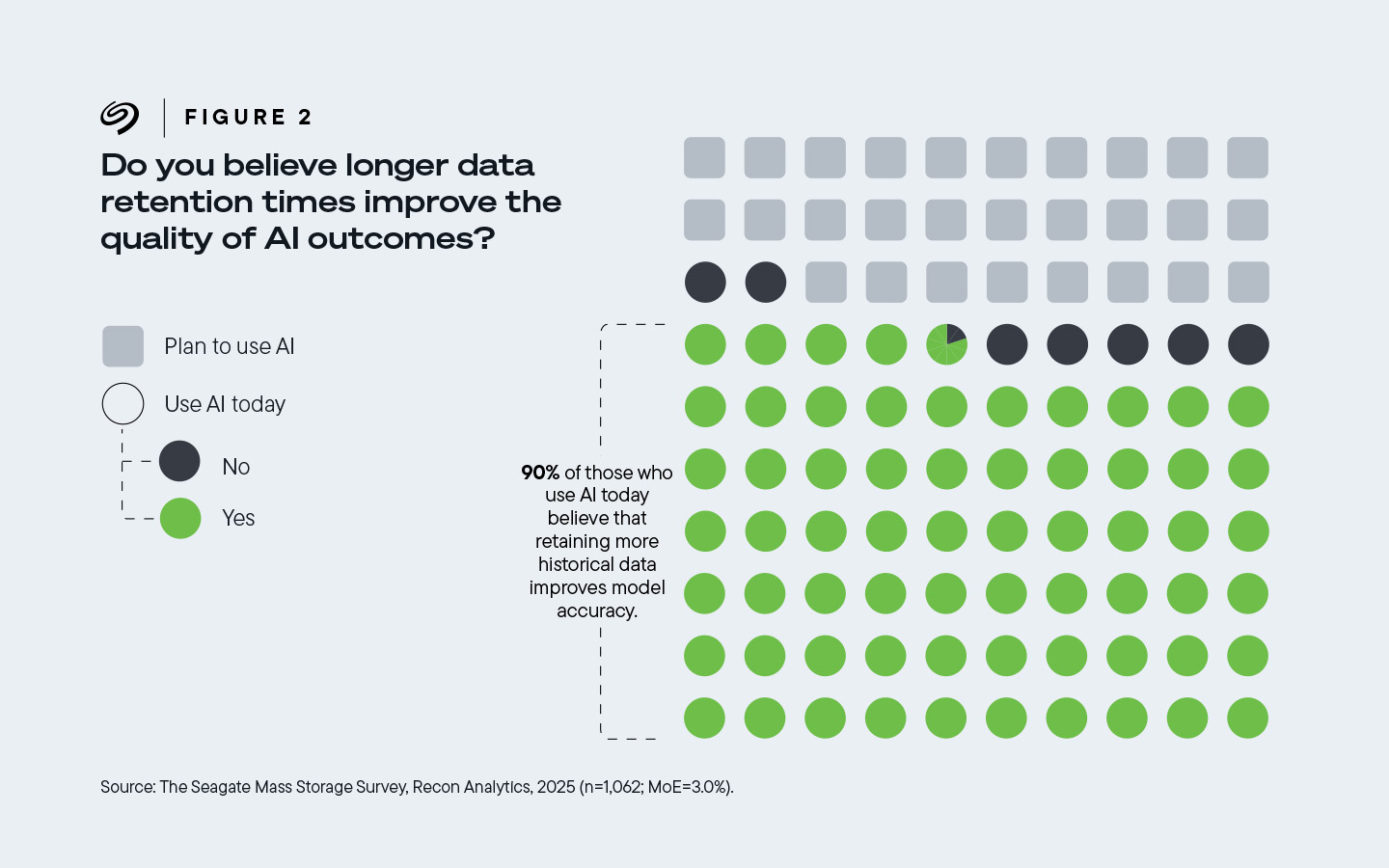
Van de ondervraagden die werkzaam zijn bij bedrijven die AI‑technologie hebben geïmplementeerd, gelooft 90% dat een langere gegevensbewaring de kwaliteit van AI‑resultaten verbetert.
Afbeelding 2. 90% van de bedrijven die tegenwoordig AI gebruiken, geloven dat het bewaren van meer historische gegevens de nauwkeurigheid van modellen verbetert.
Deze bevinding wijst op een verband tussen het langere behoud van gegevens en betrouwbaardere AI-inzichten. Verschillende factoren kunnen hieraan ten grondslag liggen. Ten eerste is constante iteratieve verwerking inherent aan hoe AI-algoritmen werken. De output van de content wordt teruggekoppeld naar het model, waardoor de nauwkeurigheid ervan verbetert en nieuwe modellen mogelijk worden. Sets van onbewerkte gegevens en resultaten worden bronnen voor verdere ontwikkeling en nieuwe workflows.
De rol van gegevensherkomst, naleving en bescherming van intellectueel eigendom in betrouwbare AI
Het langer bewaren van datasets dient echter ook andere bedrijfskritische functies, omdat het het intellectuele eigendom van een bedrijf beschermt. Het bewaart 'bonnen' van de oorspronkelijke datasets en processen van het model en geeft, indien nodig (bijvoorbeeld in het kader van een juridische procedure), een toelichting op de resultaten.
Deze ontvangstbewijzen tonen de herkomst van gegevens aan en schetsen een duidelijk overzicht van het traject dat gegevens afleggen van invoer tot uitvoer. Data lineage stelt organisaties in staat de oorsprong en het gebruik van datasets te traceren, zodat AI-modellen op accurate data worden gebouwd. Het maakt AI-systemen volledig traceerbaar en ondersteunt zowel naleving van regelgeving als interne verantwoording.
Daarnaast kiezen bedrijven er mogelijk voor om meer data langer op te slaan, omdat ze beseffen dat ze vandaag niet kunnen weten welke nieuwe, waardevolle inzichten de algoritmes van morgen uit de data van gisteren zullen halen. Langere dataretentie maakt het mogelijk om oude data te verwerken met behulp van nog te ontwikkelen AI-modellen. Om deze redenen verhoogt een langere dataretentie de zakelijke waarde die AI kan bieden.
Een verwante bevinding is dat besluitvormers op het gebied van infrastructuur het langdurig bewaren van gegevens essentieel achten voor het opbouwen van vertrouwen – een cruciale basis zonder welke inzichten uit AI weinig waarde hebben.
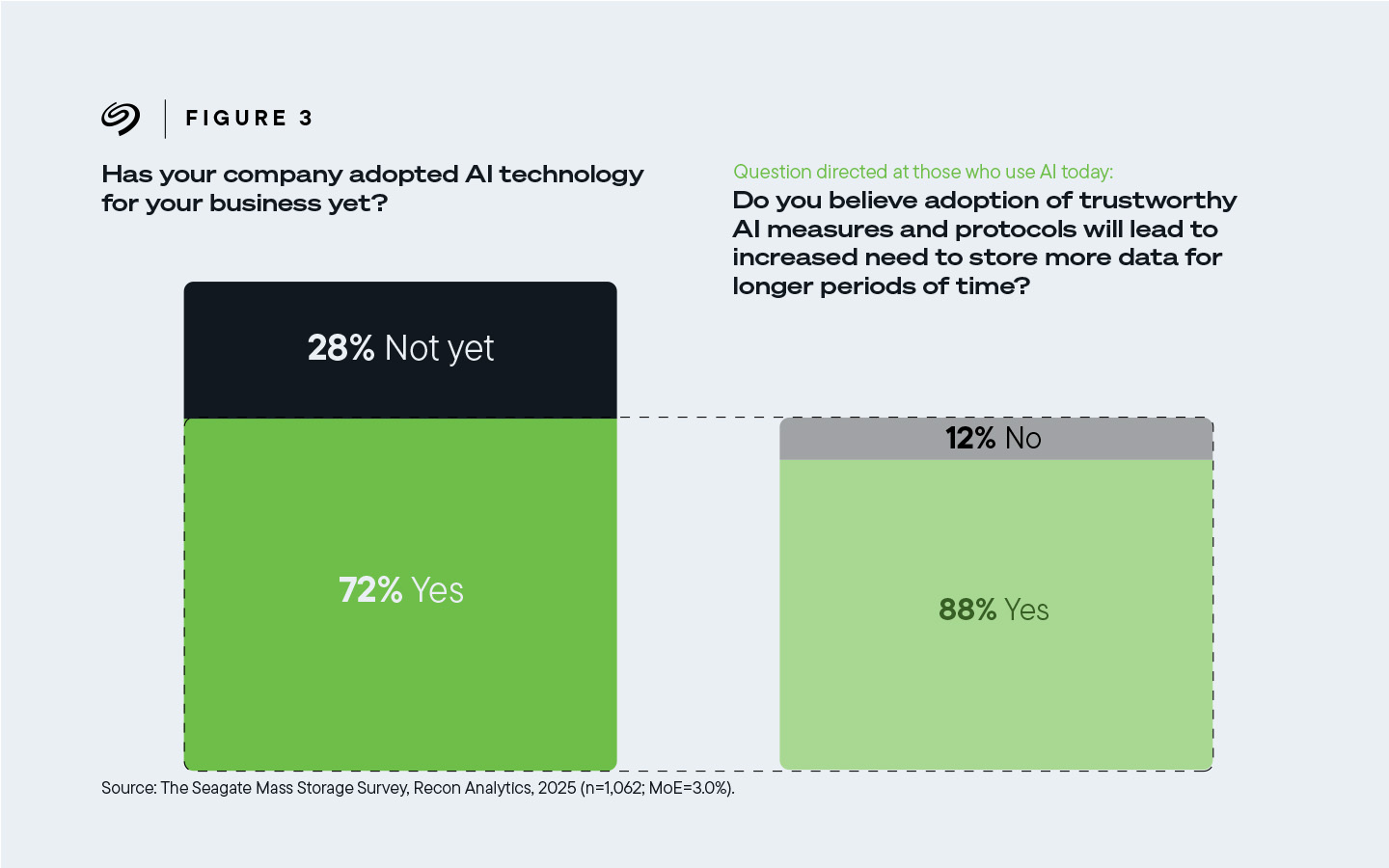
88% van de respondenten wier bedrijven vandaag AI gebruiken, gelooft dat om AI echt betrouwbaar te maken meer gegevens voor langere tijd moeten worden opgeslagen.
Afbeelding 3. 88% van de respondenten wiens bedrijven momenteel AI gebruiken, gaf aan dat de implementatie van betrouwbare AI een grotere behoefte met zich meebrengt om meer data gedurende langere perioden op te slaan.
Seagate definieert betrouwbare AI als AI-dataworkflows en -modellen die gebruikmaken van betrouwbare inputs en betrouwbare inzichten genereren. Betrouwbare AI is gebaseerd op gegevens die aan de volgende criteria voldoen:
Hoge kwaliteit en nauwkeurigheid
Duidelijke legaliteit, eigendom en herkomst.
Veilige opslag en bescherming
Verklaarbare en traceerbare transformaties door het algoritme
Consistente en betrouwbare resultaten van de gegevensverwerking.
Een schaalbare opslaginfrastructuur ondersteunt betrouwbare AI omdat deze grote hoeveelheden gegevens die door AI-systemen worden gebruikt, op de juiste wijze beheert, opslaat en beveiligt.
Als onderdeel van het bouwen aan betrouwbare AI benadrukte 80% van de ondervraagden het belang van checkpointing.
Controlepunten: Waarom frequente modelsnapshots afhankelijk zijn van betrouwbare harde schijven met een hoge capaciteit
Checkpoints fungeren in feite als momentopnamen van de huidige toestand van het model – de gegevens, parameters en instellingen – op verschillende momenten tijdens de training. Op regelmatige tijdstippen opgeslagen momentopnames zorgen ervoor dat de voortgang van het model wordt vastgelegd en dat gegevensverlies als gevolg van onverwachte onderbrekingen wordt voorkomen.
Volgens het onderzoek slaan bedrijven met meer dan 100 PB aan opslagruimte dagelijks tot wekelijks back-ups van checkpoints op, waarbij 87% van hen deze checkpoints in de cloud of in een combinatie van harde schijven en SSD's opslaat.
Om checkpointing op deze schaal te ondersteunen, hebben ondernemingen opslagsystemen nodig die constante schrijfactiviteiten kunnen ondersteunen zonder de voortgang van het model te verstoren. Harde schijven met hoge capaciteit en hybride cloudarchitecturen bieden de betrouwbaarheid en kostenefficiëntie die nodig zijn om deze snelle snapshotcycli te handhaven. Door consequent controlepunten vast te leggen en te beschermen, kunnen organisaties de voortgang van trainingen waarborgen, het herstel na onderbrekingen versnellen en stabiele, voorspelbare AI-ontwikkelingsworkflows handhaven.
Opslag: De drijvende kracht achter schaalbare, kostenefficiënte AI-systemen
Rekenkracht en energieverbruik komen vaak aan bod in gesprekken over de ingebruikname van AI. Maar uit het onderzoek van Recon Analytics blijkt dat opslag de cruciale factor is.
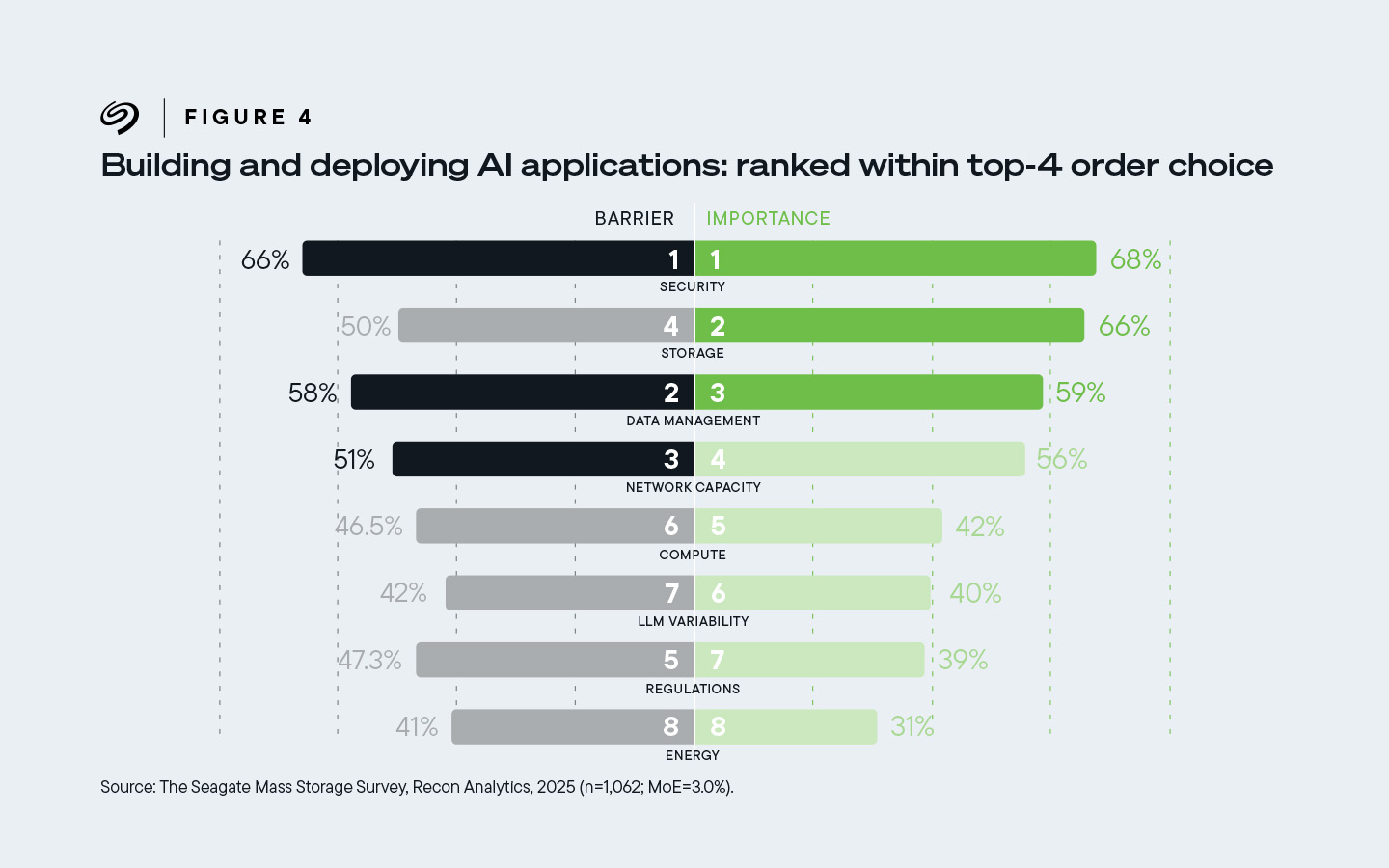
Vanuit het perspectief van de kopers van infrastructuur kwam gegevensopslag op de tweede plaats als belangrijkste aspect van de AI-infrastructuur, na beveiliging. Beveiliging en opslag werden gevolgd door gegevensbeheer, netwerkcapaciteit, rekenkracht, regelgeving, de haalbaarheid van LLM en energie, in volgorde van belangrijkheid.
Twee derde (66%) van de respondenten beschouwde opslag als de op één na belangrijkste factor van de vier belangrijkste factoren die AI mogelijk maken, en als de op vier na belangrijkste belemmering voor de implementatie ervan.
Afbeelding 4. 66% van de besluitvormers op het gebied van infrastructuur beschouwde opslag als de op één na belangrijkste component van hun top vier van AI-bevorderende factoren. Ze beschouwden opslag ook als de op drie na belangrijkste belemmering voor de ingebruikname van AI.
"De enquêteresultaten wijzen over het algemeen op een komende stijging in de vraag naar gegevensopslag, waarbij harde schijven als duidelijke winnaar uit de bus komen. Gezien het feit dat de door ons ondervraagde bedrijfsleiders steeds meer van deze door AI gegenereerde data in de cloud willen opslaan, zijn clouddiensten goed gepositioneerd om mee te liften op een tweede groeispurt.”
Roger Entner, oprichter en hoofdanalist van Recon, vat de belangrijkste conclusie als volgt samen:
Om de meeste waarde uit AI te halen, moeten bedrijven zich voorbereiden met schaalbare, efficiënte gegevensopslag. Of het nu direct is of via clouddiensten, de afhankelijkheid van AI van data hangt af van harde schijven – die een ongeëvenaarde capaciteit, kostenefficiëntie en duurzaamheid bieden – als de ruggengraat van betrouwbare AI.
Harde schijven bieden ongeëvenaarde voordelen op het gebied van kosten per TB voor grootschalige AI-opslag. Harde schijven met een grote capaciteit bieden de optimale balans tussen schaalbaarheid, energie-efficiëntie en duurzaamheid, waardoor ondernemingen hun opslagcapaciteit kunnen uitbreiden zonder hun budget of energiebeperkingen te overschrijden.