Belangrijkste voordelen
- De prestaties en kosten van inferentie worden in toenemende mate bepaald door geheugen en gegevensverplaatsing
- Agentische AI vereist een blijvende, langdurige context, waarvoor opslagruimte op harde schijven met een enorme capaciteit nodig is
- Meerlaagse architecturen (harde schijven + GPU-geheugen + NVMe SSD) maken het mogelijk om de capaciteit uit te breiden zonder dat de kosten de pan uit rijzen
Agentische AI is uitgegroeid tot de volgende operationele grens op het gebied van toegevoegde waarde.
Leidinggevenden hebben behoefte aan AI-systemen die kunnen plannen, handelen en zich in de loop van de tijd kunnen verbeteren — systemen die meerstapsworkflows uitvoeren en cruciale bedrijfsresultaten opleveren.
Maar naarmate de complexiteit en het aantal zoekopdrachten toenemen, worden de beperkingen van het contextbehoud waarop deze agents vertrouwen, steeds moeilijker te negeren.
Agenten kunnen dingen vergeten — niet omdat het model niet capabel is, maar omdat het beschikbare, permanente contextgeheugen beperkt is.
In het AI-ecosysteem heeft dit een eigen naam: de contextmuur.
De contextmuur is het punt waarop een agent geen werkcontext meer heeft en gedwongen wordt om samen te vatten, informatie weg te laten of eerder geraadpleegde feiten herhaaldelijk opnieuw op te halen en te controleren. Dat vertraagt de analyse, verhoogt de kosten en leidt vaak tot een lagere kwaliteit. Het resultaat: tegenstrijdige antwoorden en verloren draad.
De contextmuur wordt al snel een zakelijk probleem. Het wordt weergegeven als:
- Hogere rekenkosten (meer herstelwerk, meer opvraagcycli, meer tokens)
- Tragere reacties (vertraging door het opnieuw berekenen of laden van de context)
- Minder vertrouwen (inconsistent gedrag tussen sessies)
- Beperkingen in de capaciteit (agenten kunnen taken met een lange looptijd niet volhouden)
Het overbruggen van de contextkloof gaat slechts gedeeltelijk over het verbeteren van modellen. Het gaat vooral om de manier waarop u context opslaat en weergeeft.
De gezamenlijke oplossing voor agentgebaseerde AI
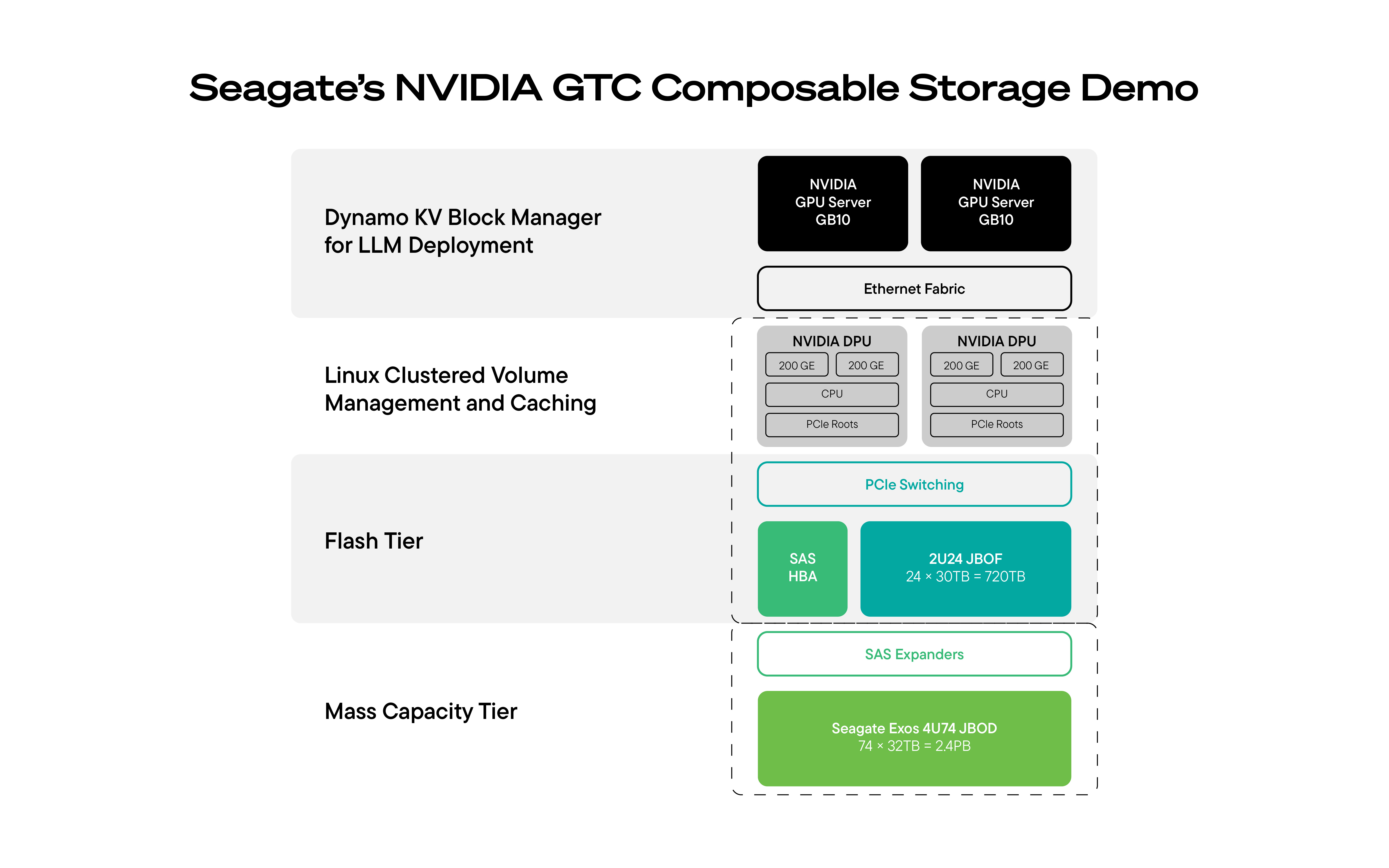
Om deze uitdaging aan te gaan, hebben Seagate en zijn partners tijdens de NVIDIA GTC een commercieel verkrijgbare, productieklaar AI-opslagoplossing met meerdere lagen geïntroduceerd, die is ontworpen om de context voor AI-workloads uit te breiden.
De oplossing die op de GTC werd gedemonstreerd, combineerde:
- Een NVIDIA DGX Spark GPU-cluster-rekenknooppunt waarop inferentie op grote schaal wordt uitgevoerd
- Supermicro JBOF als snelle, in een netwerk opgenomen NVMe SSD-cachelaag om de directe context dicht bij de rekenkracht te houden
- Seagate-harde schijf JBOD voor een schaalbare gegevensopslaglaag met hoge capaciteit, waarmee u op betaalbare wijze langdurige opslag kunt realiseren
- NVIDIA BlueField-3 of NVIDIA BlueField-4 DPU’s voor het overnemen en versnellen van gegevensverplaatsing en caching tussen de opslag en het rechtstreeks plaatsen van gegevens in het GPU-geheugen
- Door DPU gecoördineerde open-sourcecomponenten (NVIDIA Dynamo) om datasets die op de harde schijf staan op intelligente wijze via SSD’s in de cache op te slaan
Deze architectuur is niet alleen van belang omdat zij de context verbreedt, maar ook omdat zij een nieuw kader biedt voor de manier waarop organisaties moeten denken over de economische aspecten van AI-inferentie. Zodra de taken van de agents in productie worden genomen, spelen geheugengebruik en gegevensverplaatsing een cruciale rol voor de prestaties, de kosten en de betrouwbaarheid — en niet alleen voor de kwaliteit van de modellen.
„Door de JBOF-flashlaag van Supermicro te combineren met de harde-schijflaag van Seagate kunnen de kosten voor inferentie aanzienlijk worden verlaagd, terwijl tegelijkertijd hoge prestaties worden geboden,” aldus Vik Malyala, president en algemeen directeur voor EMEA en senior vicepresident Technologie en AI bij Supermicro. „Dit is met name van belang nu agentische AI op grote schaal wordt toegepast en de inferentiewerkbelasting exponentieel toeneemt.“
Maak van uw kennis een concurrentievoordeel
Hier is de verschuiving die gemakkelijk over het hoofd wordt gezien: inferentie wordt net zozeer een geheugenprobleem als een rekenprobleem. GPU’s zijn krachtig, maar om productief te zijn, moeten ze over de juiste gegevens beschikken die op het juiste moment, met de juiste snelheid en tegen de juiste kosten worden aangeleverd.
Agenten hebben behoefte aan meer opslagruimte voor contextgegevens. Naast de aanwijzingen moeten zij ook het volgende bijhouden:
- Uitgebreide gespreks- en beslissingsgeschiedenis
- Beleid en procedures
- Kennis van producten en probleemoplossing
- Logbestanden, tickets en telemetrie
Proberen om dat alles in de direct toegankelijke laag (GPU-geheugen of all-flash) te houden, is alsof u erop staat dat een heel bedrijf uitsluitend gebruikmaakt van premium verzending met levering op dezelfde dag: prima voor een paar pakketjes, maar financieel gezien onzinnig op grote schaal.
De succesvolle aanpak is gebaseerd op meerlaagse, permanente opslagarchitecturen.
Waarom opslagsystemen met meerdere lagen de praktische oplossing zijn
Een slimme AI-stack maakt een onderscheid tussen het kortetermijngeheugen en het langetermijngeheugen en zet elke laag in voor datgene waar deze het beste in is:
- Realtime toegangsniveaus (GPU HBM-geheugen, CPU DRAM, lokale en netwerk-NVMe-SSD’s): verwerken de huidige context — actieve tokens, hot embeddings en veel geraadpleegde gegevens
- Capaciteitsniveaus (gebaseerd op harde schijven): bewaren context op lange termijn — grote datasets, langdurige geschiedenis en uitgebreid agentgeheugen
De zakelijke meerwaarde vloeit voort uit een eenvoudig principe: het automatisch toewijzen van gegevens over alle lagen heen. U houdt de GPU’s aan het werk, de kosten onder controle en de context gedetailleerd.
Hoe DPU’s het dataplane optimaliseren
In het verleden was het combineren van prestatieniveaus en capaciteitsniveaus voor AI een rommelige aangelegenheid. Dit vereiste vaak complexe, propriëtaire bestandssystemen, een hoge CPU-belasting en kwetsbare afstemming — vooral naarmate de gegevensvolumes explosief toenamen.
Dat verandert dankzij data processing units (DPU’s).
DPU’s kunnen gegevensverwerking overnemen en versnellen, zodat het systeem geen CPU-cycli van de host hoeft te verbruiken alleen maar om bytes te verplaatsen. Ze maken snelle netwerk- en opslagtoegangspatronen mogelijk en kunnen standaard Linux-gebaseerde diensten uitvoeren voor caching, tiering, uitvalbestendigheid en beveiliging. Kortom, DPU’s maken het mogelijk om AI-opslag met meerdere lagen te implementeren en schaalbaar te maken.
Dat is wat een meerlaags ontwerp op productieschaal haalbaar maakt.
Wat de meerlaagse architectuur mogelijk maakt
De architectuur van Seagate, Supermicro en NVIDIA brengt de kerncomponenten samen die nodig zijn om AI op grote schaal en op kosteneffectieve wijze uit te breiden: GPU-rekenkracht voor inferentie, harde schijven voor contextgegevens met een grote opslagcapaciteit en een lange levensduur, NVMe-SSD’s voor directe toegang, en DPU’s om gegevensverplaatsing en caching tussen de verschillende lagen te coördineren.
Die combinatie draagt bij aan de bedrijfsresultaten die voor klanten het belangrijkst zijn.
Een diepere context op het gebied van agenticiteit leidt tot meer bedrijfswaarde
Wat betekent deze aanpak voor klanten?
1. Een beter geheugen bij de agent — en betere resultaten
Agenten hebben toegang tot veel meer historische gegevens dan er in de opslag naast de GPU past. Dat draagt bij aan een langetermijnvisie, een betere personalisatie en minder fouten als gevolg van een ontbrekende context.
2. Lagere schaalkosten
Harde schijven bieden aanzienlijk lagere kosten per TB voor langetermijnopslag. Dat is van belang omdat datasets en de geschiedenis van agents voortdurend groeien.
3. Efficiëntie als de volgende uitdaging op het gebied van optimalisatie
Organisaties houden zowel de prestaties (tokens per seconde) als de efficiëntie bij, met inbegrip van statistieken zoals het stroomverbruik per token en het continue GPU-gebruik. Ontwerpen met meerdere lagen helpen verspilde inspanningen (opnieuw laden, opnieuw verwerken, opnieuw ophalen) te verminderen en zorgen ervoor dat GPU’s productief blijven.
4. Afstemming op de toekomstige ontwikkeling van AI-infrastructuur
Door DPU aangestuurde datavlakken spelen een steeds centralere rol in het ontwerp van moderne AI-systemen. Deze aanpak sluit aan bij die visie: bouwen met het oog op schaalbare gegevenslevering, en niet alleen op ruwe rekenkracht.
Bewijs, geen beloftes: De GTC-demo en wat er daarna komt
Tijdens de GTC werd deze architectuur gedemonstreerd in een werkend systeem — met GPU’s voor inferentie, harde schijven voor omvangrijke, diepgaande context, SSD’s voor directe toegang en DPU’s die zorgen voor een efficiënte gegevensverplaatsing en caching.
AI bevindt zich nog in een vroeg ontwikkelingsstadium. Het zal enorme hoeveelheden gegevens blijven verwerken en genereren. Samen maken Seagate, Supermicro en NVIDIA die toekomst mogelijk met architecturen die duurzamer en efficiënter zijn en zijn ontworpen voor schaalbaarheid.
De organisaties die agents met succes opschalen, zijn de organisaties die context als een strategisch voordeel beschouwen — en een infrastructuur opzetten waarmee die context efficiënt kan worden opgeslagen en aangeboden.
Neem contact op met een expert om te bespreken hoe Seagate uw organisatie kan helpen de agentische contextmuur te overwinnen.






-v4.png/_jcr_content/renditions/4-3-small-416x312.png)