Principais lições
- O desempenho e o custo da inferência são cada vez mais influenciados pela memória e pela movimentação de dados.
- A IA agética requer um contexto persistente e de longa duração, o que exige armazenamento em disco rígido de grande capacidade.
- Arquiteturas de múltiplas camadas (discos rígidos + memória da GPU + SSD NVMe) ajudam a escalar o contexto sem custos exorbitantes.
A IA agente emergiu como a próxima fronteira operacional de valor.
Os líderes organizacionais precisam de sistemas de IA que possam planejar, agir e melhorar ao longo do tempo — agentes que executem fluxos de trabalho com várias etapas e gerem resultados comerciais críticos.
Mas, à medida que a complexidade e o volume de consultas aumentam, as limitações de retenção de contexto das quais esses agentes dependem tornam-se difíceis de ignorar.
Os agentes podem se tornar esquecidos — não porque o modelo seja incapaz, mas porque sua memória de contexto utilizável e persistente é limitada.
O ecossistema de IA tem um nome para isto: a barreira de contexto.
A barreira do contexto é o ponto em que um agente fica sem contexto de trabalho e precisa resumir, descartar informações ou recuperar e verificar repetidamente fatos acessados anteriormente. Isso torna as inferências mais lentas, aumenta os custos e, muitas vezes, degrada a qualidade. O resultado: respostas inconsistentes e tópicos perdidos.
A barreira do contexto rapidamente se torna um problema para os negócios. Aparece da seguinte forma:
- Custos computacionais mais elevados (mais retrabalho, mais ciclos de recuperação, mais tokens)
- Respostas mais lentas (latência devido ao recálculo ou recarregamento do contexto)
- Baixa confiança (comportamento inconsistente entre as sessões)
- Limitações de capacidade (os agentes não conseguem manter tarefas de longo prazo)
A ampliação da barreira contextual visa apenas, em parte, aprimorar os modelos. Trata-se principalmente de como você armazena e disponibiliza o contexto.
A solução conjunta para IA agente
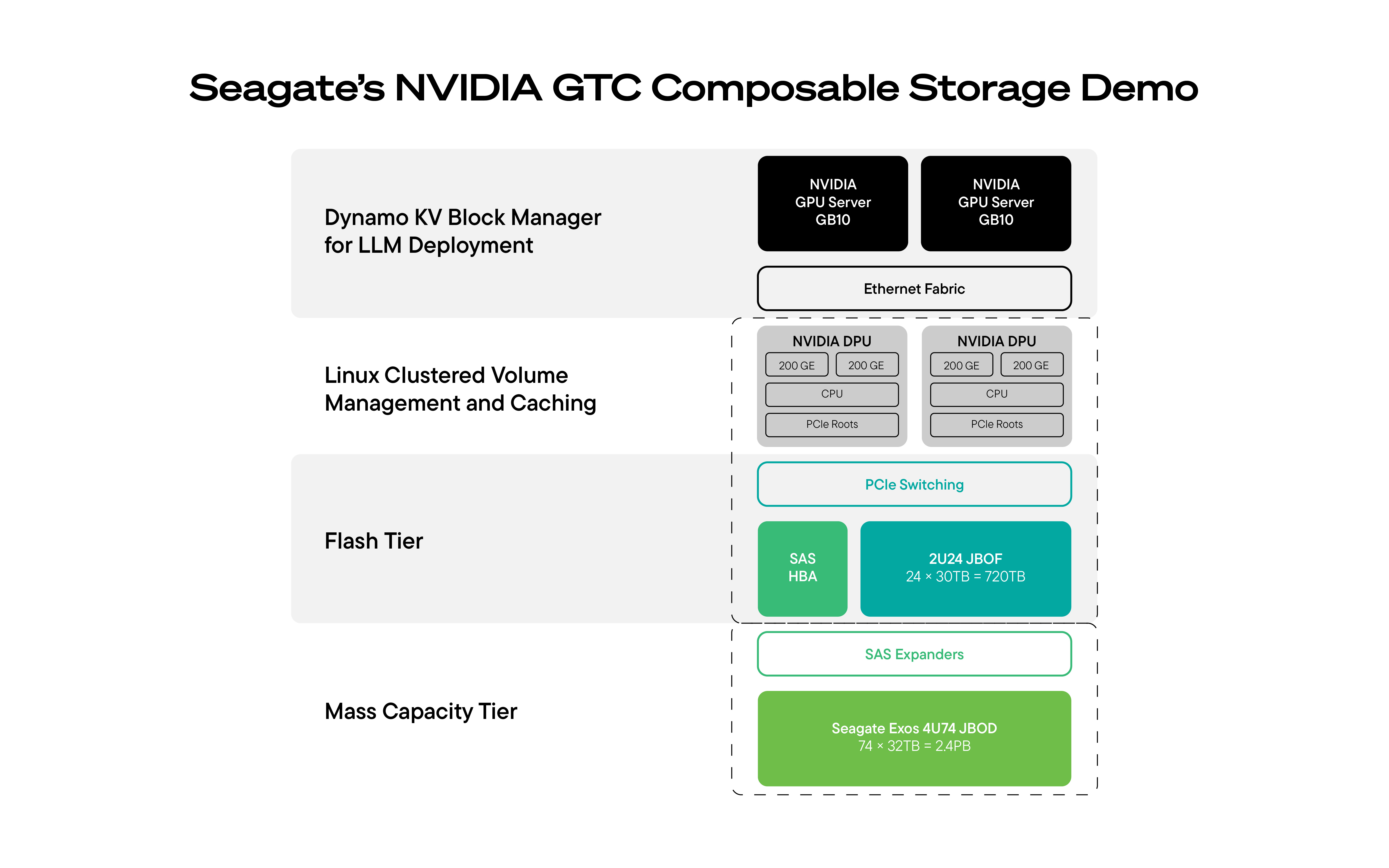
Para enfrentar esse desafio, a Seagate e seus parceiros apresentaram na NVIDIA GTC uma solução de armazenamento de IA de várias camadas, disponível comercialmente e pronta para produção, projetada para ampliar o contexto das cargas de trabalho de IA.
A solução demonstrada na GTC combinou:
- Cluster de GPUs NVIDIA DGX Spark executando inferência em escala
- Supermicro JBOF como camada de cache SSD NVMe de alta velocidade em rede para manter o contexto imediato próximo ao computador.
- JBOD de disco rígido Seagate para camada de armazenamento de dados escalável e de alta capacidade, proporcionando contexto de longa duração a um preço acessível
- DPUs NVIDIA BlueField-3 ou NVIDIA BlueField-4 para descarregar e acelerar a movimentação e o armazenamento em cache de dados entre o armazenamento e a colocação direta de dados na memória da GPU
- Componentes de código aberto orquestrados por DPU (NVIDIA Dynamo) para armazenar em cache de forma inteligente conjuntos de dados residentes em discos rígidos por meio de SSDs
Essa arquitetura é importante não apenas porque amplia o contexto, mas também porque reformula a maneira como as organizações devem pensar sobre a economia da inferência de IA. Quando as cargas de trabalho dos agentes entram em produção, a movimentação de memória e dados torna-se fundamental para o desempenho, o custo e a confiabilidade — e não apenas para a qualidade do modelo.
“A combinação da camada de flash JBOF da Supermicro com a camada de discos rígidos da Seagate pode reduzir drasticamente os custos de inferência, ao mesmo tempo que oferece alto desempenho”, disse Vik Malyala, presidente e diretor administrativo da EMEA e vice-presidente sênior de tecnologia e IA da Supermicro. “Isto é especialmente importante à medida que a IA orientada a agentes se torna amplamente adotada e as cargas de trabalho de inferência crescem exponencialmente.”
Transforme a memória em uma vantagem competitiva.
Eis a mudança que é fácil de passar despercebida: a inferência está se tornando um problema de memória tanto quanto um problema de computação. As GPUs são poderosas, mas para serem produtivas, precisam receber os dados certos, no momento certo, na velocidade certa e ao custo certo.
Os agentes precisam de mais espaço para armazenar contexto. Além das instruções, eles precisam ficar atentos a:
- Longo histórico de conversas e decisões
- Políticas e procedimentos
- Conhecimento sobre produtos e resolução de problemas
- Registros, tickets e telemetria
Tentar manter tudo isso na camada de acesso imediato (memória da GPU ou totalmente em flash) é como insistir que uma empresa inteira funcione com entrega premium no mesmo dia: ótimo para alguns pacotes; financeiramente absurdo em grande escala.
A abordagem vencedora baseia-se em arquiteturas de armazenamento permanente de múltiplas camadas.
Por que o armazenamento em várias camadas é a resposta prática
Uma arquitetura de IA inteligente separa a memória de curto prazo da memória de longo prazo e utiliza cada camada para o que ela faz de melhor:
- Camadas de acesso em tempo real (memória HBM da GPU, DRAM da CPU, SSDs NVMe locais e de rede): lidam com o contexto imediato — tokens ativos, embeddings frequentes e dados acessados com frequência
- Camadas de capacidade (construídas a partir de discos rígidos): armazenam contexto de longo prazo — grandes conjuntos de dados, históricos de longa duração e memória estendida do agente.
O valor comercial advém de um princípio simples: automatizar a colocação de dados em todas as camadas. Você mantém as GPUs ocupadas, os custos sob controle e o contexto em profundidade.
Como as DPUs otimizam o plano de dados
Historicamente, combinar níveis de desempenho e níveis de capacidade para IA tem sido complicado. Frequentemente, isso exigia sistemas de arquivos proprietários complexos, alta sobrecarga de CPU e ajustes delicados — especialmente à medida que os volumes de dados aumentavam exponencialmente.
Isso está mudando por causa das unidades de processamento de dados (DPUs).
As DPUs podem descarregar e acelerar a movimentação de dados, de modo que o sistema não consuma ciclos da CPU do host apenas para embaralhar bytes. Eles permitem padrões de acesso a redes e armazenamento de alta velocidade e podem executar serviços padrão baseados em Linux para cache, hierarquização, resiliência e segurança. Resumindo, as DPUs ajudam a tornar o armazenamento de IA em várias camadas implantável e escalável.
É isso que torna um design de múltiplos níveis viável em escala de produção.
O que a arquitetura de múltiplas camadas possibilita
A arquitetura da Seagate, Supermicro e NVIDIA reúne os componentes essenciais para expandir o contexto da IA de forma econômica e em grande escala: Computação em GPU para inferência, discos rígidos para contexto de alta capacidade e longa duração, SSDs NVMe para acesso imediato e DPUs para coordenar a movimentação e o armazenamento em cache de dados em todas as camadas.
Essa combinação promove os resultados de negócios que mais importam para os clientes.
Um contexto de agência mais profundo significa maior valor para o negócio.
O que essa abordagem significa para os clientes?
1. Melhor armazenamento de memória pelo agente — e melhores resultados.
Os agentes podem acessar muito mais dados históricos do que cabe no armazenamento adjacente à GPU. Isso favorece o raciocínio de longo prazo, uma personalização mais rica e menos falhas causadas por esquecimento de contexto.
2. Contexto de custo reduzido para escalabilidade
Os discos rígidos oferecem um custo por TB drasticamente menor para armazenamento de dados a longo prazo. Isso é importante porque os conjuntos de dados e os históricos dos agentes crescem continuamente.
3. Eficiência como a próxima fronteira da otimização
As organizações monitoram o desempenho (tokens por segundo), bem como a eficiência, incluindo métricas como consumo de energia por token e utilização sustentada da GPU. Projetos com múltiplas camadas ajudam a reduzir o trabalho desperdiçado (recarregamento, reprocessamento, recuperação repetida) e mantêm as GPUs produtivas.
4. Alinhamento com a direção para onde a infraestrutura de IA está caminhando.
Os planos de dados baseados em DPU estão se tornando essenciais para o design de sistemas de IA modernos. Essa abordagem está alinhada com essa direção: construir para entrega de dados escalável, e não apenas para computação bruta.
Provas, não promessas: A demonstração do GTC e o que vem a seguir
Na GTC, essa arquitetura foi demonstrada em um sistema em funcionamento — com GPUs para inferência, discos rígidos para contexto profundo e massivo, SSDs para acesso imediato e DPUs orquestrando a movimentação e o armazenamento em cache eficientes de dados.
A inteligência artificial ainda está em um estágio inicial de desenvolvimento. Continuará a consumir e a gerar volumes massivos de dados. Juntas, a Seagate, a Supermicro e a NVIDIA estão a viabilizar esse futuro com arquiteturas mais sustentáveis, mais eficientes e concebidas para serem escaláveis.
As organizações que conseguirem escalar agentes com sucesso serão aquelas que tratarem o contexto como um ativo estratégico — e construírem uma infraestrutura capaz de armazenar e fornecer esse contexto de forma eficiente.
Fale com um especialista sobre como a Seagate pode permitir que sua organização dimensione o muro de contexto agente.






-v4.png/_jcr_content/renditions/4-3-small-416x312.png)