L’adoption généralisée de l’intelligence artificielle (IA) et des technologies Big Data a entraîné des changements transformateurs dans pratiquement tous les secteurs, modifiant la manière dont les organisations génèrent des informations stratégiques et pilotent la prise de décision basée sur les données.
Ce rythme rapide d’adoption ne devrait pas ralentir de sitôt. Selon Grand View Research, le marché mondial de la technologie de l'IA devrait croître à un taux annuel de 36,6 %, pour atteindre une valeur marchande mondiale totale de plus de 1,8 billion de dollars d'ici 2030.
Des petites entreprises aux grandes entreprises, l’IA et le Big Data apportent de nouvelles efficacités et capacités au développement de stratégies et aux opérations quotidiennes. En tant que leader mondial du stockage, Seagate joue un rôle central dans la fourniture de systèmes de stockage de données évolutifs, fiables et hautes performances dont les entreprises ont besoin pour prendre en charge l'IA et le Big Data dans leurs flux de travail.
Qu'est-ce que l'IA ?
L’intelligence artificielle est une technologie innovante capable d’effectuer du raisonnement, de l’apprentissage et de la résolution de problèmes avec des capacités logiques qui simulent la cognition et l’intelligence humaines.
L’IA est un terme générique englobant de nombreuses formes d’intelligence virtuelle, notamment l’apprentissage automatique, l’IA générative et le traitement du langage naturel. Grâce à des algorithmes avancés, au big data et à une ingénierie rapide, l’IA est un outil révolutionnaire qui offre de nouvelles capacités en matière de personnalisation et d’automatisation.
Qu'est-ce que le Big Data ?
Le Big Data fait référence à des ensembles de données à volume élevé qui sont si vastes et complexes qu’ils nécessitent des systèmes spécialisés pour traiter, gérer et analyser leurs informations. Le Big Data représente généralement des ensembles de données provenant d’un large éventail de sources, et les données sont unifiées par leur propriété ou leur pertinence par rapport à une organisation ou une entité spécifique.
L’IA, l’apprentissage automatique et l’analyse avancée sont généralement nécessaires pour traiter et analyser efficacement les mégadonnées afin de générer des informations précieuses à partir de ces informations.
Types de données utilisées dans l'IA
L’IA peut utiliser plusieurs types de données pour générer des informations précieuses qui offrent une valeur stratégique aux entreprises cherchant à améliorer leurs performances, à optimiser leur productivité et à permettre une amélioration continue au sein de leurs équipes et de leurs opérations.
Voici les trois types de données que tout le monde devrait connaître lorsqu’il utilise l’IA pour l’analyse de données :
1. Données structurées
Les données structurées sont des données traitées et organisées qui sont facilement consultables dans une base de données. Les sources courantes de données structurées comprennent les informations sur les clients, les données d’inventaire, les transactions et les journaux de maintenance.
Ce type de données est le plus adapté pour fournir des informations stratégiques qui guident les optimisations et autres changements au sein d’une organisation.
2. Données non structurées
Les données non structurées sont des informations qui doivent être traitées avant que l’on puisse en tirer du sens et des informations. Les images, les vidéos et certains types de fichiers texte sont des formes courantes de données non structurées.
Les technologies d’IA sont devenues un outil efficace pour analyser ces données à grande échelle, permettant aux entreprises d’extraire des informations puissantes à partir d’ensembles de données non structurés. Par exemple, l’IA peut surveiller les images de sécurité et identifier les anomalies indiquant un comportement spécifique. Il peut également aider à évaluer les commentaires des clients pour contextualiser et catégoriser automatiquement chaque réponse individuelle.
3. Big Data
Le Big Data comprend généralement des ensembles de données structurés et non structurés, qui doivent tous être traités et gérés à grande échelle. L’IA peut parcourir des données structurées et non structurées pour identifier des modèles de comportement des clients. Il peut également coordonner les relations entre les tendances des données structurées et les événements de données non structurées pour aider à contextualiser les informations sur les changements dans les opérations, les habitudes d'achat, la logistique de la chaîne d'approvisionnement et de nombreuses autres applications.
Lien entre l'IA et le big data
Les technologies d’IA étant utilisées pour traiter et analyser le Big Data, ces deux entités distinctes bénéficient mutuellement de cette relation continue.
L’analyse des Big Data fournit aux modèles d’IA davantage d’informations pour apprendre et affiner leurs modèles, améliorant ainsi les performances de l’IA au fil du temps. Parallèlement, de meilleures capacités d’analyse de l’IA augmentent l’impact commercial potentiel des informations recueillies à partir du Big Data, offrant ainsi plus de valeur à votre organisation.
Cette relation symbiotique permet à de nombreux secteurs d’atteindre un traitement rapide des informations qui prend en charge les interventions basées sur les données et les solutions d’IA personnalisées.
Comment l'IA stimule la croissance exponentielle des données
Grâce à la consommation et à l’analyse des données, l’IA elle-même est devenue une source importante de croissance des données grâce à l’apprentissage automatique, à l’automatisation et à l’automatisation du contenu. Les appareils IoT et autres technologies améliorées par l’IA contribuent tous à des volumes sans précédent de données en temps réel qui doivent être gérées, analysées et stockées.
La gestion des données à cette échelle nécessite une infrastructure de stockage robuste et hautes performances, capable de répondre à vos besoins de stockage actuels et futurs.
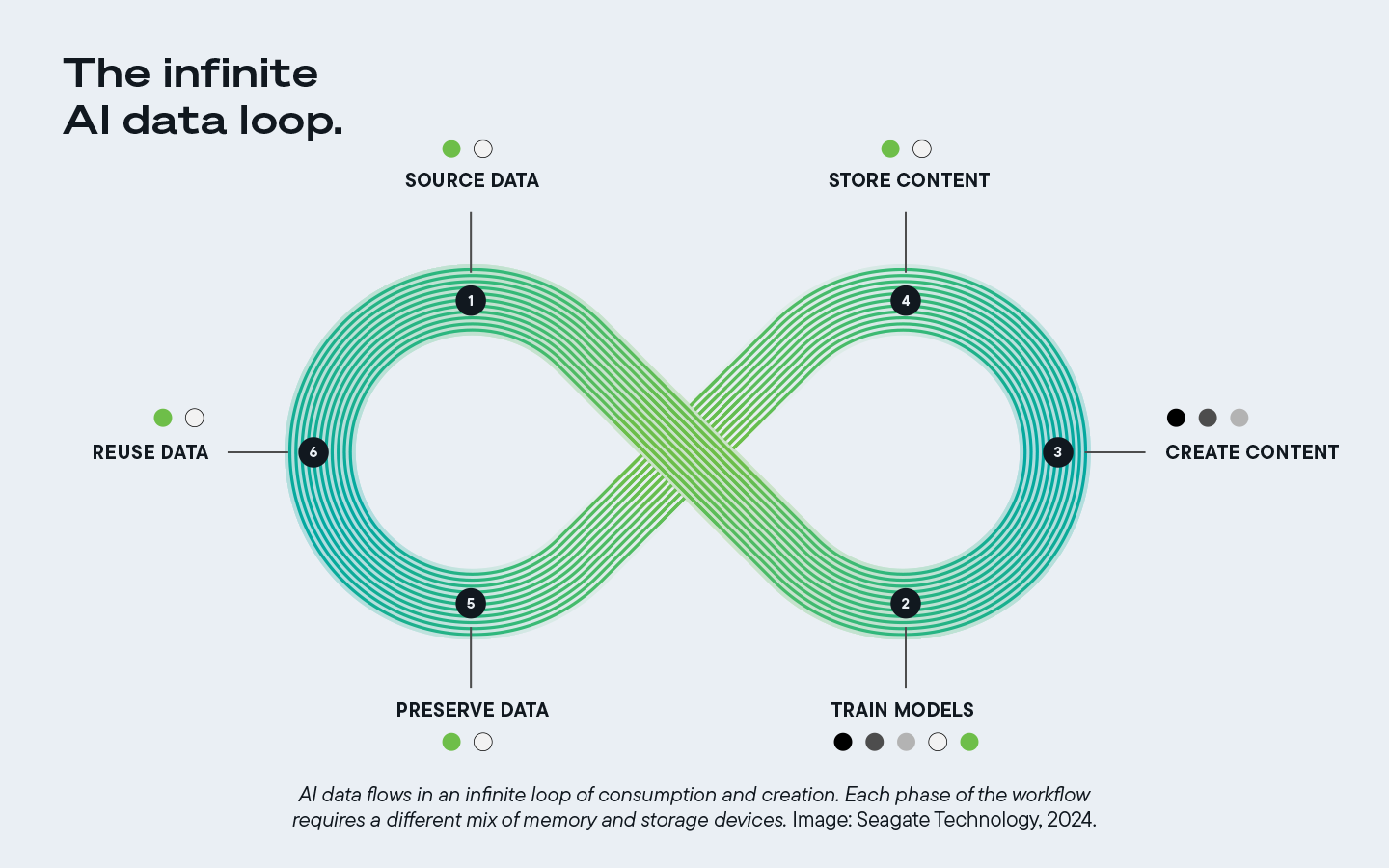
Comprendre le flux de données dans le processus d'IA
L’analyse des données d’IA repose sur un cycle de vie continu qui prend en charge l’apprentissage et le perfectionnement continus de vos modèles d’IA. Voici comment l’IA et le Big Data fonctionnent ensemble pour soutenir la création et l’itération continues :
1. Collecte de données
L’IA doit avoir accès à des sources de données diverses et de haute qualité, notamment des capteurs IoT, des intégrations de logiciels d’entreprise, des interactions directes avec les clients et une base de connaissances propriétaire. Ces informations et leur accès doivent être gérés efficacement pour garantir que les données sont complètes et exactes et que le processus de collecte de données respecte les exigences de confidentialité et autres exigences de conformité.
2. Préparation et nettoyage des données
La préparation et le nettoyage des données éliminent les anomalies et les inexactitudes qui réduisent la valeur de ces ensembles de données. Les techniques courantes utilisées dans cette phase du flux de données incluent la déduplication et la normalisation, entre autres tactiques.
3. Annotation et étiquetage des données
L’annotation et l’étiquetage sont essentiels lors de la formation des modèles d’IA. Les balises d'annotation ajoutent des informations de contextualisation pertinentes aux données, telles que l'étiquetage d'objets dans des vidéos et des images, ou l'application d'étiquettes de sentiment pour aider l'IA à mieux comprendre les commentaires des clients. Au fil du temps, une annotation et un étiquetage cohérents favoriseront une meilleure formation et des résultats d’IA plus efficaces.
4. le stockage et la gestion des données
Un stockage efficace et hautement évolutif est nécessaire pour prendre en charge une gestion efficace des données et un stockage des données pour les flux de travail d'IA. Les entreprises doivent créer une infrastructure de soutien en utilisant des solutions telles que Seagate Mozaic 3+™, conçue spécifiquement pour répondre aux défis de stockage uniques des implémentations d'IA.
5. Boucle de rétroaction des données de l'IA
La valeur à long terme de l’IA repose sur des améliorations itératives. Une boucle de rétroaction de données d’IA durable implique un cycle continu de consommation de données, de génération de contenu et d’amélioration des performances qui contribuent tous à ces améliorations itératives. Les organisations doivent disposer d’un accès transparent aux données pour les technologies d’IA afin de faciliter ce cercle vertueux de développement.
Besoins de stockage de l'IA
Les flux de travail d'IA exigeants nécessitent une infrastructure de stockage conçue pour équilibrer les exigences suivantes :
● Hautes performances pour un traitement rapide des données. Les flux de travail d’IA nécessitent des performances de stockage rapides qui offrent une faible latence à grande échelle, en particulier lors de l’utilisation de l’IA pour générer des informations en temps réel.
● Évolutivité pour s'adapter à des ensembles de données croissants. À mesure que le volume de données augmente et que les implémentations d’IA se multiplient, l’infrastructure de stockage doit évoluer de manière transparente parallèlement à ces services.
● Fiabilité pour sécuriser les flux de travail ininterrompus. Les performances de stockage doivent être maintenues même pendant les périodes de pointe d’utilisation et sous la pression des ensembles de données croissants.
Pour répondre à ces besoins multiformes, les entreprises ont besoin d'un écosystème diversifié de solutions de mémoire et de stockage, utilisant des disques SSD locaux et réseau, une mémoire à large bande passante (HBM), une mémoire vive dynamique (DRAM) et des disques durs réseau.
Synergie entre stockage et calcul dans l'IA
Dans un flux de travail d'IA, les clusters de stockage et de calcul n'existent pas en tant qu'entités distinctes. Ils jouent un rôle synergique dans les performances globales et l'optimisation des flux de travail de l'IA. Les GPU, les CPU, les HBM, la DRAM, les SSD d'entreprise et les disques durs d'entreprise offrent chacun des capacités spécifiques en matière de puissance de traitement et de gestion des données. L’intégration transparente de ces solutions est essentielle pour maximiser les performances de l’IA.
Le rôle de Seagate dans la mise en œuvre de l'IA et de la gestion des données à grande échelle
Seagate propose une suite de solutions de stockage d'entreprise qui optimisent la capacité et l'efficacité de votre centre de données, en prenant en charge le développement tout en préparant votre infrastructure à l'évolution des demandes d'IA et à un volume croissant de flux de travail d'IA. Avec Mozaic 3+, votre entreprise peut équiper son centre de données d'un stockage de grande capacité à des densités surfaciques sans précédent.
Stockage et calcul : des besoins en tandem pour les flux de travail d'IA
La solution Seagate Mozaic 3+ prend en charge sans effort les technologies complémentaires qui composent votre flux de travail IA, augmentant ainsi les performances, l'évolutivité et la fiabilité.
Une approche synergique de la gestion des ressources informatiques et du stockage optimise en fin de compte la vitesse, l’efficacité, la consommation d’énergie et la disponibilité de vos capacités d’IA. Lorsqu'elles sont correctement mises en œuvre, ces solutions couvrent l'ensemble du spectre entre performances et évolutivité pour maximiser la réalisation de la valeur à long terme de vos investissements en IA.
Découvrez comment Mozaic 3+ aide l'IA à atteindre son plein potentiel
Le pouvoir transformateur de l’IA nécessite une infrastructure de stockage qui brise les barrières et élève la densité et les performances de stockage vers de nouveaux sommets.
Les solutions Seagate Mozaic 3+, notamment les disques durs Exos® Mozaic 3+, y parviennent grâce à l'enregistrement magnétique assisté par la chaleur (HAMR), qui permet des gains de densité surfacique significatifs qui regroupent les données de manière plus compacte dans un espace plus petit et plus efficace, tout en conservant ces données magnétiquement et thermiquement stables.
Avec HAMR, Mozaic 3+ repousse les limites de la densité de stockage sans compromettre la fiabilité de ce stockage, tout en conservant le format pratique et familier de 3,5 pouces.
Les infrastructures de stockage conventionnelles ne sont pas équipées pour prendre en charge la croissance rapide des flux de travail d'IA et des initiatives de Big Data. Les entreprises qui souhaitent profiter de ces opportunités innovantes doivent d’abord s’assurer qu’elles ont construit une base de stockage capable de soutenir ces initiatives à grande échelle.
Découvrez par vous-même les solutions de stockage Seagate et découvrez comment Mozaic 3+ peut vous aider à répondre à vos besoins émergents en matière d'IA et de Big Data.







-v4.png/_jcr_content/renditions/4-3-small-416x312.png)