Chez Seagate, nos équipes d'ingénierie et moi-même nous réunissons régulièrement avec les plus grands constructeurs d'infrastructures cloud et d'IA au monde.
Outre la fourniture d'exaoctets de disques durs haute capacité, nous travaillons à leurs côtés pour les aider à façonner leurs architectures de stockage.
Grâce à ces partenariats, j'ai pu observer de près comment sont prises les décisions en matière de stockage hyperscale. Le point commun est clair : l'économie, l'orchestration logicielle et les capacités matérielles doivent s'aligner pour maximiser les performances, l'efficacité et la valeur des données.
Cet alignement est devenu encore plus important à mesure que les charges de travail de l'IA continuent d'augmenter la taille des ensembles de données, la fréquence d'accès, les fenêtres de contexte, le parallélisme, le temps de rétention et les exigences imposées aux systèmes de stockage partagés.
Ces changements d’échelle ont fondamentalement modifié la signification du terme « stockage primaire ».
Historiquement, le stockage primaire désignait des systèmes de fichiers ou de blocs étroitement couplés et situés à proximité des unités de calcul. Dans les environnements cloud et d'IA, cependant, le stockage primaire est de plus en plus défini par des architectures distribuées à l'échelle mondiale et définies par logiciel, qui traitent le stockage d'objets comme un système d'enregistrement persistant qui conserve et sert des volumes massifs de données à travers les charges de travail.
Pour mieux comprendre comment cette redéfinition s'est déroulée, examinons les principes de conception qui ont initialement façonné le stockage d'entreprise.
Comment la mise à l'échelle a changé le paradigme du stockage
Pendant des décennies, l'écosystème a fonctionné selon une norme commune : l'interface du système d'exploitation portable (POSIX). Conçu à une époque où les infrastructures étaient plus localisées, POSIX offrait aux développeurs un modèle prévisible d'interaction avec les données.
Elle mettait l'accent sur une forte cohérence de lecture après écriture, le verrouillage synchrone des fichiers et les structures de répertoires hiérarchiques. Pour une machine unique ou un cluster localisé, cette solution s'est avérée très efficace et reste aujourd'hui essentielle pour de nombreux environnements d'entreprise et d'applications.
Cependant, l'avènement du modèle cloud a bouleversé les compromis fondamentaux. Les systèmes à l'échelle du cloud ont été conçus pour une échelle, un modèle de distribution et une structure de coûts fondamentalement différents de ceux pour lesquels les systèmes POSIX-first ont été initialement conçus.
Dans un environnement distribué, les implémentations de type POSIX peuvent nécessiter une orchestration importante entre les nœuds pour préserver la sémantique des répertoires, le verrouillage des fichiers et les mises à jour sur place.
Les plateformes cloud nécessitaient une capacité massive — s'étendant finalement pour prendre en charge des dizaines, voire des centaines d'exaoctets — et dans cet environnement, la surcharge de coordination des conceptions étroitement couplées a commencé à introduire de la latence et à imposer des limites pratiques à la croissance.
Dans les charges de travail d'IA modernes nécessitant des ensembles de données encore plus volumineux, la création de points de contrôle, le traitement des jetons, l'inférence et des pipelines de données hautement parallèles, ces pressions n'ont fait que s'intensifier.
Dans l'ensemble du secteur, de Google Cloud Storage (GCS) et Colossus à Microsoft Azure Blob, Amazon S3 et Tectonic de Meta, les plateformes cloud ont adopté des architectures définies par logiciel conçues spécifiquement pour les données distribuées à l'échelle mondiale et les charges de travail hyperscale, et les ont perfectionnées au fil du temps à mesure que l'échelle et les exigences évoluaient.
Dans ce nouveau paradigme, le logiciel assume une plus grande responsabilité en matière d'orchestration, de résilience et de flux de données afin que les supports de stockage sous-jacents puissent être utilisés aussi efficacement que possible.
Les disques durs constituent le pilier du stockage à grande échelle
Dans les architectures cloud comme celles que j'ai mentionnées ci-dessus, les disques durs constituent la base du stockage de données à grande échelle.
Cela reflète la persistance des enjeux économiques liés à la capacité et les principes physiques de l'enregistrement haute densité. Les disques durs modernes de grande capacité intègrent des technologies telles que l'enregistrement magnétique à chevauchement (SMR) et l'enregistrement magnétique assisté par la chaleur (HAMR) pour continuer à augmenter la densité surfacique et rendre possible le stockage à l'échelle de l'exaoctet.
À cette échelle, les parcs de disques durs constituent le système d'enregistrement, offrant une durabilité, une rentabilité et une densité volumétrique que les autres technologies de stockage ne peuvent tout simplement pas égaler.
Il y a une raison pour laquelle 87 % des exaoctets des grands centres de données sont stockés sur des disques durs1!
À mesure que les infrastructures cloud continuent de s'étendre et que les charges de travail d'IA consomment, génèrent, conservent et réutilisent des volumes de données plus importants, ces avantages deviennent encore plus significatifs.
Mais elles ne peuvent être pleinement réalisées que si l'architecture logicielle est conçue pour tirer parti des atouts des disques haute capacité.
Les modèles d'accès POSIX traditionnels, en particulier dans les modèles de systèmes de fichiers distribués étroitement couplés qui mettent l'accent sur les mises à jour fragmentées, aléatoires et sur place, ne sont pas toujours bien adaptés à ces atouts à très grande échelle.
Les plateformes cloud modernes définies par logiciel ont résolu ce problème en concevant leurs infrastructures de stockage autour des disques durs, ce qui leur permet de privilégier les flux de données séquentiels à haut débit tout en assurant une rentabilité opérationnelle évolutive.
Dans le cas d'Amazon S3, un service stockant 500 billions d'objets et traitant 200 millions de requêtes par seconde—une récente keynote AWS re:Invent2 a souligné que le secret des performances du stockage cloud réside dans l'écriture de logiciels optimisés pour les capacités du disque dur, décrit dans la présentation comme une « merveille d'ingénierie ».
Plutôt que de contraindre le disque à se conformer à des abstractions logicielles conçues pour une autre époque, les architectures cloud modernes sont conçues pour compléter les atouts des disques durs haute densité modernes.
Comment les architectures cloud optimisent l'efficacité des disques durs
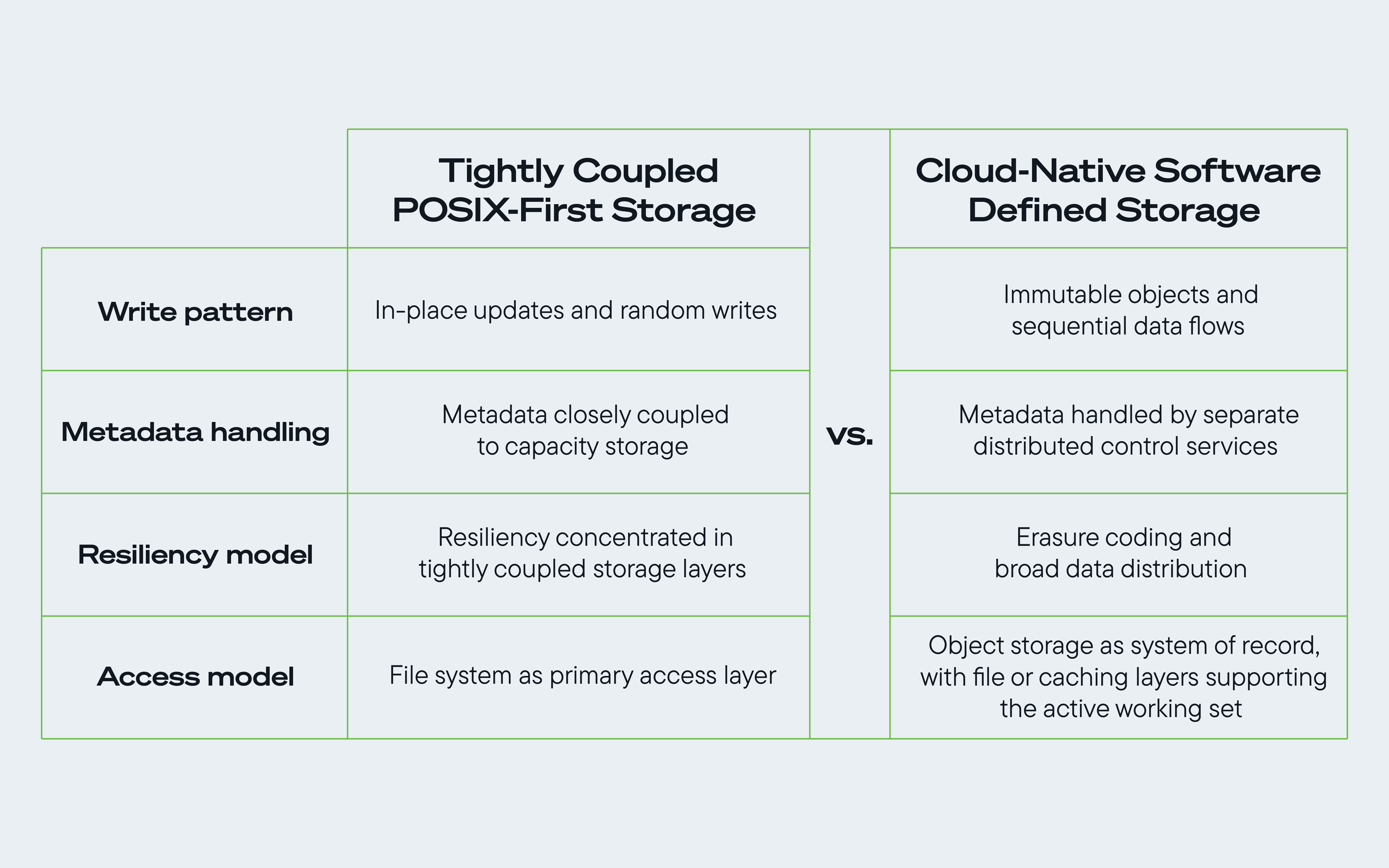
Cette conception technique a pris plusieurs formes, mais sur les principales plateformes cloud, elle reflète généralement quatre principes architecturaux. Ensemble, ils montrent comment le stockage en nuage est devenu de plus en plus défini par logiciel dans sa façon de gérer le flux de données, les métadonnées, la résilience et le comportement d'ingestion.
1. L'immuabilité des objets favorise les flux de données séquentiels.
Les services comme GCS et Amazon S3 sont conçus pour prendre en charge l'immuabilité des objets et les mises à jour versionnées. Une fois les données écrites dans un système de stockage d'objets, les mises à jour sont généralement gérées en écrivant une nouvelle version de l'objet plutôt qu'en modifiant la version existante.
En réduisant le besoin d'écritures binaires aléatoires et sur place, les architectures à l'échelle du cloud déplacent une plus grande partie de la charge de travail du disque vers des flux de données séquentiels importants. Cela correspond mieux à la façon dont les disques haute capacité offrent débit et efficacité à grande échelle. Cet avantage devient encore plus important dans le cadre des charges de travail d'IA, où la création de points de contrôle, le déplacement d'ensembles de données et les pipelines parallèles peuvent générer une pression soutenue sur les systèmes de stockage partagés.
2. Les métadonnées sont de plus en plus gérées par des services de contrôle distincts ou distribués.
Dans un environnement POSIX traditionnel, les systèmes de stockage gèrent souvent les métadonnées et les données utiles des fichiers de manière étroitement couplée. Les plateformes cloud hyperscale ont changé la donne en séparant les services de métadonnées du stockage de capacité, déplaçant ainsi une grande partie du suivi et de la coordination vers des couches de contrôle plus rapides et plus évolutives plutôt que de laisser cette charge reposer sur les disques eux-mêmes.
Colossus de Google Cloud transfère une grande partie de ce travail vers des services résidant en mémoire, tandis que Tectonic de Meta sépare les métadonnées — au sein d'un modèle de système de fichiers distribué — en microservices sans état exécutés sur un magasin de clés-valeurs à évolutivité horizontale. Il en résulte une réduction des contraintes structurelles sur les disques durs sous-jacents et une plus grande possibilité pour ces derniers de fournir une capacité dense et efficace à grande échelle.
3. Le codage par effacement renforce la résilience distribuée
Un troisième principe consiste à utiliser le codage d'effacement et une large distribution des données pour rendre les systèmes de stockage à grande échelle plus résilients et plus efficaces.
Les architectures cloud réduisent cette sensibilité grâce au codage d'effacement et à une large distribution des données. En répartissant les objets sur plusieurs disques, ces systèmes peuvent isoler les points chauds localisés, continuer à fournir des données malgré de brèves pointes de latence et se reconstruire au besoin. Cela rend la couche de stockage plus résiliente et contribue à maintenir le débit dans des conditions de charges de travail mixtes combinant cloud et IA.
4. Le chemin de données à plusieurs niveaux
Un quatrième principe concerne la manière dont les données sont préparées avant d'atteindre les supports de stockage de grande capacité.
Pour combler le fossé entre le trafic applicatif imprévisible et l'environnement structuré que les disques durs haute densité gèrent le mieux, les architectures modernes utilisent un chemin de données à plusieurs niveaux, intégrant de la mémoire flash ou de la mémoire vive pour mettre en mémoire tampon l'ingestion et optimiser le placement des données.
Une couche flash absorbe les débits d'arrivée variables du trafic API et des écritures d'applications. Il prépare et organise les données entrantes avant leur transfert vers les supports de stockage, permettant ainsi aux processus en arrière-plan de les transférer vers les baies de disques durs par longues passes séquentielles.
Dans le cadre des charges de travail d'IA, où l'ingestion, la création de points de contrôle et le déplacement d'ensembles de données peuvent être particulièrement irréguliers, ce rôle de mise en mémoire tampon devient encore plus important car il contribue à préserver à la fois une ingestion à faible latence et une utilisation efficace du disque dur.
Figure 1. Comparaison des logiciels de stockage POSIX traditionnels et des logiciels de stockage natifs du cloud pour optimiser les avantages d'une architecture de stockage centrée sur le disque dur.
Un nouveau modèle pour le stockage primaire
Ensemble, ces changements architecturaux ont redéfini la manière dont le stockage primaire est conçu. Historiquement, le terme « stockage primaire » désignait souvent des systèmes de fichiers ou de blocs coûteux et à haute disponibilité, étroitement liés aux unités de calcul. Le stockage objet était plus souvent considéré comme une destination de niveau inférieur pour l'archivage, la sauvegarde ou les données secondaires.
Aujourd'hui, de nombreuses architectures natives du cloud définissent le stockage primaire de manière plus large : un calcul sans état associé à un stockage d'objets global. Les lacs de données construits sur des plateformes telles que S3, Azure et GCS servent de plus en plus de système d'enregistrement pour l'analyse à grande échelle, les applications cloud et les flux de travail d'IA.
Dans ce modèle, le stockage principal est de plus en plus défini par logiciel, avec des services d'objets, des couches de métadonnées, une mémoire tampon flash et des disques durs haute capacité fonctionnant ensemble comme un système coordonné.
Les instances de calcul sont souvent considérées comme plus élastiques et sans état, extrayant les données de la couche objet, les traitant et réécrivant les résultats dans le même environnement partagé.
La convergence du stockage objet et de la sémantique des fichiers
Au cours de la dernière décennie, le stockage d'objets est devenu un élément central des architectures cloud, et plus récemment des flux de travail d'IA. Une autre tendance importante a alors émergé : les systèmes de fichiers parallèles haute performance.
Les systèmes tels que Lustre, Weka et VAST sont conçus pour optimiser les performances des charges de travail étroitement couplées, exposant souvent des interfaces conformes à la norme POSIX pour prendre en charge la sauvegarde, la coordination et l'accès aux données à haut débit.
Dans le même temps, les plateformes de stockage d'objets ont continué d'évoluer, optimisant l'évolutivité globale tout en améliorant les performances pour prendre en charge un ensemble croissant de charges de travail d'IA et de données intensives.
Dans les environnements de cloud et d'IA à grande échelle, ces approches convergent. Les systèmes de fichiers haute performance s'appuient fréquemment sur des systèmes de stockage objet ou s'y intègrent, combinant ainsi les performances de l'ensemble de travail actif avec l'évolutivité et les avantages économiques du stockage objet en tant que système d'enregistrement.
Cette convergence reflète un changement architectural plus large : plutôt que de choisir entre fichier et objet, les systèmes modernes les combinent. Il préserve la commodité des dossiers, des espaces de noms et des comportements familiers des fichiers sans sacrifier les avantages d'échelle du stockage objet.
Implications pour les concepteurs d'infrastructures cloud et d'IA
Considérées ensemble, ces évolutions mènent à une conclusion plus générale : les architectures cloud et IA ont nécessité des compromis logiciels et systèmes différents de ceux pour lesquels les modèles POSIX-first avaient été initialement conçus.
Ces compromis ont accru l'importance de concevoir des logiciels permettant d'optimiser l'utilisation des parcs de disques durs sous-jacents sur lesquels les systèmes sont construits. En ce sens, les charges de travail liées au cloud et à l'IA n'ont pas seulement modifié l'architecture de stockage ; elles ont redéfini le stockage primaire lui-même.
Pour les concepteurs d'infrastructures, la leçon est claire : concevoir pour les systèmes modernes signifie dépasser l'hypothèse selon laquelle le stockage principal doit correspondre parfaitement à l'arborescence de fichiers du système d'exploitation local. Cela implique de choisir des logiciels et des modèles d'accès qui correspondent aux réalités économiques, physiques et de charge de travail de l'IA à grande échelle.
Les organisations qui réussiront à maîtriser cet aspect seront mieux placées pour exécuter efficacement leurs stratégies d'IA, avec une utilisation accrue des GPU, une meilleure rentabilité des inférences et moins de goulots d'étranglement en matière de performances.
Découvrez les innovations en matière de disques durs qui alimentent le stockage principal des plus grands constructeurs d'infrastructures d'IA et de cloud au monde.
Sources
1. IDC Datasphere et IDC Storagesphere
2. AWS re:Invent 2025, Discours d'ouverture d'Andy Warfield : S3 stocke plus de 500 000 milliards d'objets, traite 200 millions de requêtes par seconde et plus d'un quadrillion de requêtes par an.