為大規模人工智慧部署準備企業資料基礎設施
人工智慧工作負載會產生大量的結構化和非結構化資料。為了支援訓練、推理和再訓練週期,企業需要可擴展的高容量存儲,以應對持續的資料成長。
沒有數據——海量數據——人工智慧就不會成功。
沒有充足、有效率的資料存儲,就沒有海量資料集。AI 工作負載會建立連續的資料流—從訓練資料集和推理日誌到元資料、嵌入和模型輸出。隨著生成式人工智慧和大型語言模型(LLM)的擴展,企業資料的數量和種類呈指數級增長。這種快速擴展要求儲存架構能夠處理持續的資料攝取、高速存取和長期可靠的資料保存。
數據支撐著人工智慧,大容量硬碟支撐著數據。
研究公司 Recon Analytics 的一項 2025 年調查清晰地揭示了這些觀點。
這項全球調查詳細介紹了多個行業的企業如何調整其基礎設施以支援人工智慧。受訪者代表了已經使用或計劃使用人工智慧的組織,他們就儲存需求、擴展挑戰和企業資料基礎設施的未來提供了見解。
這項由 Seagate 委託進行的全球調查共有 1,062 名受訪者參與。 他們是 IT 儲存採購員和決策者,在年收入超過 1000 萬美元、當前儲存使用量超過 50 TB、已採用人工智慧或計劃在未來三年內採用人工智慧的公司中擔任儲存基礎設施職務,並且位於美國、中國、英國、韓國、新加坡、法國、印度、日本、台灣和德國。
該調查重點關注人工智慧應用對基礎設施優先順序、資料保留和資料管理的影響。調查結果顯示 AI 將如何影響未來三年的基礎架構需求。
全球調查洞察:人工智慧的應用將如何改變數據基礎設施
Recon Analytics 的最新調查顯示,企業在規劃其資料生態系統以迎接人工智慧時代時,正在發生重大轉變。與其將人工智慧視為一項孤立的舉措,不如讓各組織重新評估儲存策略、資源分配和長期基礎設施設計,以因應人工智慧的加速普及。該調查反映了全球 IT 領導者如何為未來做好準備,未來數據成長、資料保留要求和效能期望將比以往任何時候都增長得更快。
到 2028 年人工智慧資料成長:人工智慧儲存需求為何激增?
首先,調查顯示,到 2028 年,人工智慧的普及將推動資料儲存需求呈指數級增長。
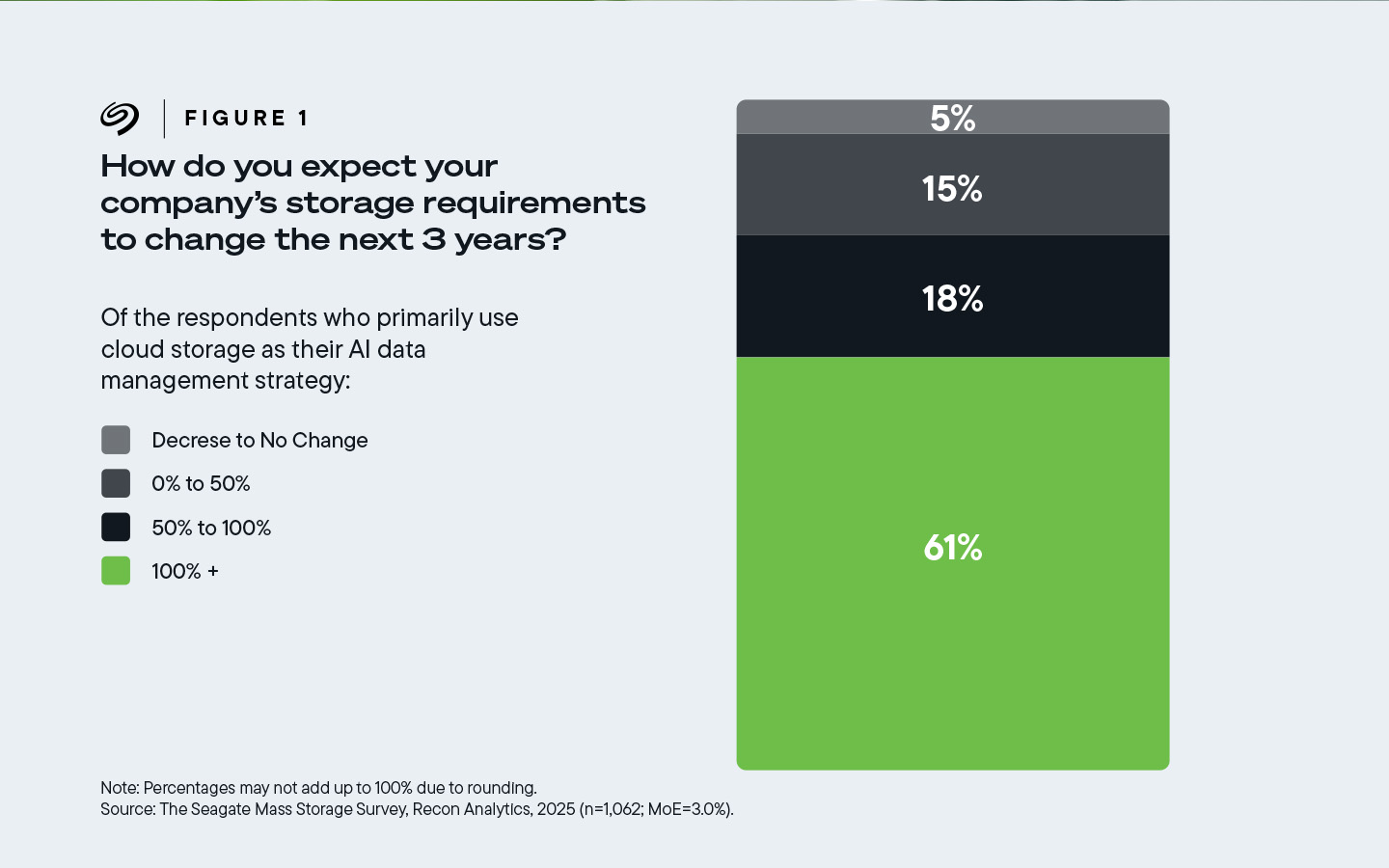
多達 61% 的受訪者來自主要使用 雲端儲存的公司,他們表示,未來三年內,他們公司的雲端儲存必須增加 100% 以上 ,也就是說,必須翻倍。
圖 1:在主要使用雲端儲存進行 AI 資料管理的受訪公司中,61% 的人預計其儲存需求將增加 100% 或更多。
為什麼長期資料保留能夠提高人工智慧的準確性和可信度
隨著人工智慧應用帶來前所未有的資料創造,企業保存的資料越多,就越能驗證人工智慧是否如預期運作。透過獲取行為資料(如訓練資料集、模型檢查點、提示和答案),企業可以審查演算法,以更好地理解和改進人工智慧決策。如果沒有資料中心的規模和效率,AI 的潛力就會受到限制,因為儲存和擷取大量資料集的能力是 AI 成功的關鍵。
人工智慧的成功不僅取決於儲存容量。資料儲存時長也很重要。
金融、醫療保健、製造業和政府運營等行業依賴長期留住人才來滿足合規要求和審計需求。保留歷史數據可以加強治理框架,支援監管報告,並使人工智慧輸出隨著時間的推移更加準確。
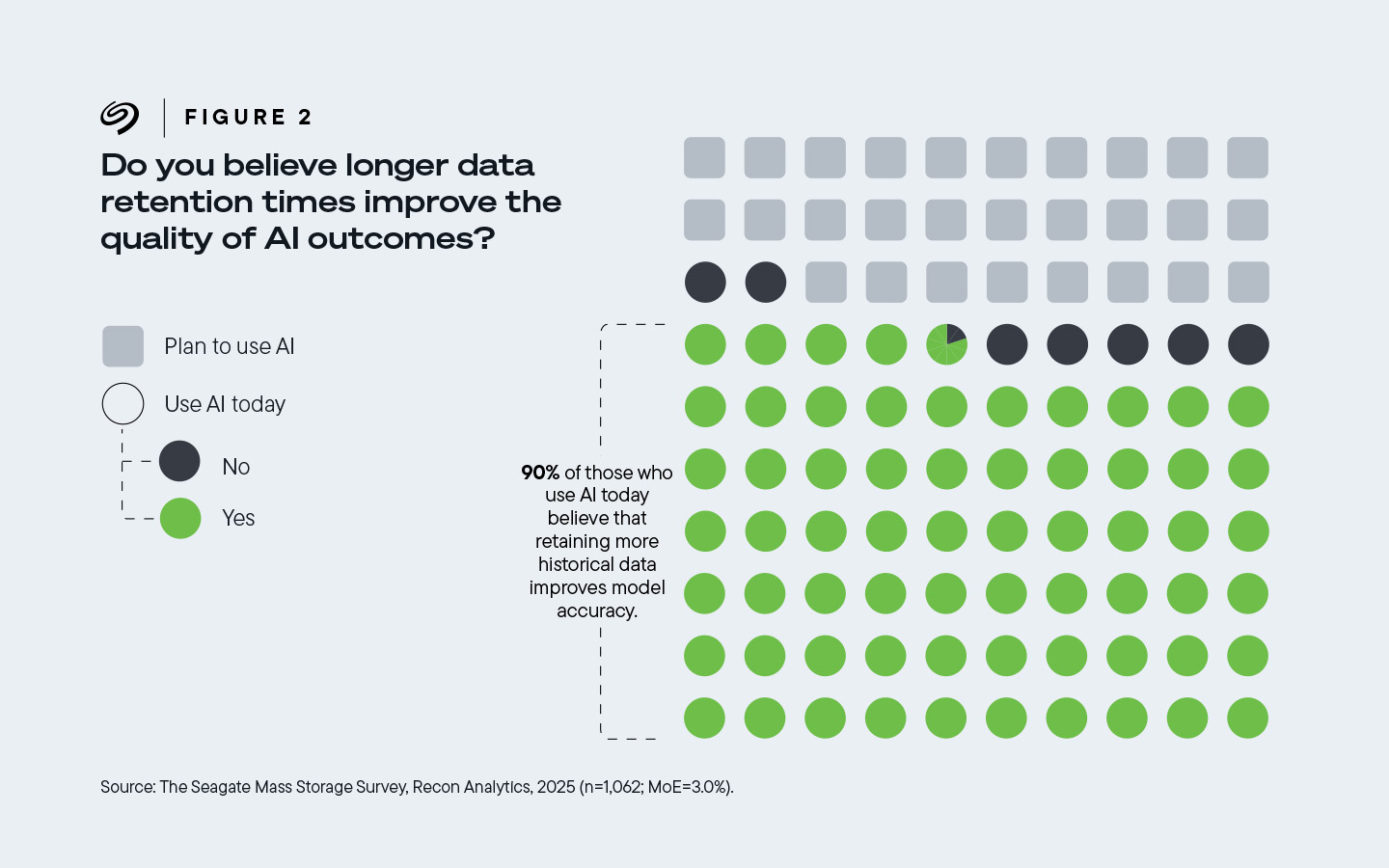
在受訪的、受僱於已採用人工智慧技術的企業的受訪者中,90%的人認為更長的資料保留期可以提高人工智慧結果的品質 。
圖 2:如今,90% 使用人工智慧的公司認為,保留更多歷史資料可以提高模型準確性。
這項發現指出資料保存時間更長與 AI 深度分析更可靠之間存在關聯。 有幾個因素能支持這樣的論點。首先持續的迭代處理是 AI 演算法運作方式的本質。 內容輸出的成果會輸回模型之中,改善模型的準確度,並能藉此建立新模型。原始資料集和成果成為進一步開發和新工作流程的來源。
資料沿襲、合規性和智慧財產權保護在可信賴人工智慧中的作用
但長期保存資料集還有其他重要的業務功能,因為它可以保護公司的智慧財產權。它會保留模型原始資料集和過程的“收據”,並在需要時(例如,作為法律程序的一部分)提供結果解釋。
這些收據建立了資料沿襲,清楚地記錄了資料從輸入到輸出的路徑。資料沿襲使組織能夠追蹤資料集的來源和使用情況,從而確保人工智慧模型建立在準確的資料之上。它使人工智慧系統完全可審計,並支援監管合規性和內部問責制。
此外,公司可能會選擇儲存更多資料更長時間,因為他們意識到,他們今天無法知道明天的演算法可能會從昨天的資料中發現哪些新的、有價值的見解。更長的資料保留期使得尚未開發的 AI 模型能夠處理舊資料。基於這些原因,更長的資料保留時間可以提升人工智慧所能提供的商業價值。
相關研究發現,基礎設施決策者認為延長資料保留時間對於建立信任至關重要——沒有信任,人工智慧洞察幾乎沒有價值。
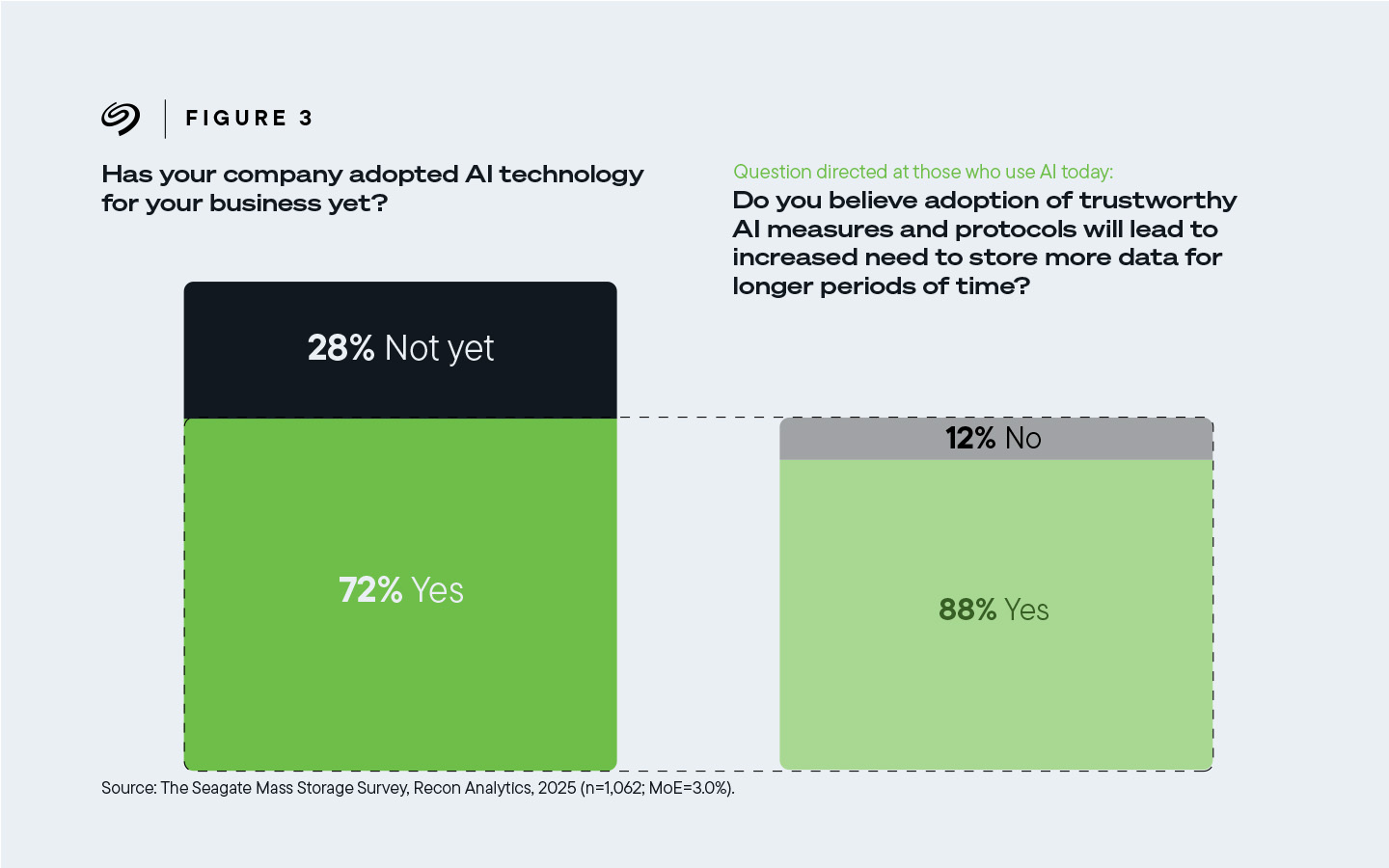
88% 的受訪者認為,如今使用人工智慧的公司採用可信賴的人工智慧會增加儲存更多資料並延長儲存時間的需求 。
圖 3:88% 的受訪者表示,他們的公司目前使用人工智慧,而採用可信賴的人工智慧需要儲存更多資料並延長儲存時間。
Seagate 將 值得信賴的 AI 定義為使用可靠輸入並產生可靠見解的 AI 資料工作流程和模型。值得信賴的 AI 是以符合下列條件的資料為基礎所建立的:
高品質和高精度
明確的合法性、所有權和來源
安全儲存和保護
演算法實現可解釋和可追溯的轉換
數據處理輸出結果一致且可靠。
可擴展的儲存基礎設施能夠支援可信賴的人工智慧,因為它能夠妥善管理、儲存和保護人工智慧系統使用的大量資料。
作為建立可信任 AI 的一部分,80% 的受訪者強調了檢查點(checkpointing)的重要性。
檢查點:為什麼頻繁的模型快照依賴可靠的大容量硬碟存儲
所謂的檢查點設定,是指在訓練期間以短時間的特定間隔儲存 AI 模型狀態的程序。 人工智慧模型透過迭代過程在大數據集上進行訓練,這個過程可能需要幾分鐘到幾個月的時間。模型訓練所需時間取決於模型的複雜程度、資料集的大小以及可用的運算能力。在此期間,模型會接收數據,參數會進行調整,系統會根據處理的資訊學習如何預測結果。
檢查點本質上就像是模型在訓練過程中多個階段的當前狀態(資料、參數和設定)的快照。定期保存快照可以保留模型進度的記錄,並防止因意外中斷而導致的資料遺失。
根據調查,使用 100PB 以上儲存空間的公司每天或每週都會保存和備份檢查點,其中 87% 的公司將這些檢查點儲存在雲端或硬碟和 SSD 的混合儲存中。
為了支援這種規模的檢查點,企業需要能夠持續進行寫入活動而不中斷模型進度的儲存系統。大容量硬碟和混合雲架構提供了維持這些快速快照週期所需的可靠性和成本效益。透過持續捕捉和保護檢查點,組織可以保障訓練進度,加快從中斷中恢復的速度,並維持穩定、可預測的 AI 開發工作流程。
儲存:可擴展、低成本人工智慧系統背後的秘密驅動因素
在採用 AI 的討論中,運算和能源是熱門主題。但 Recon Analytics 的調查顯示,儲存是關鍵驅動因素。
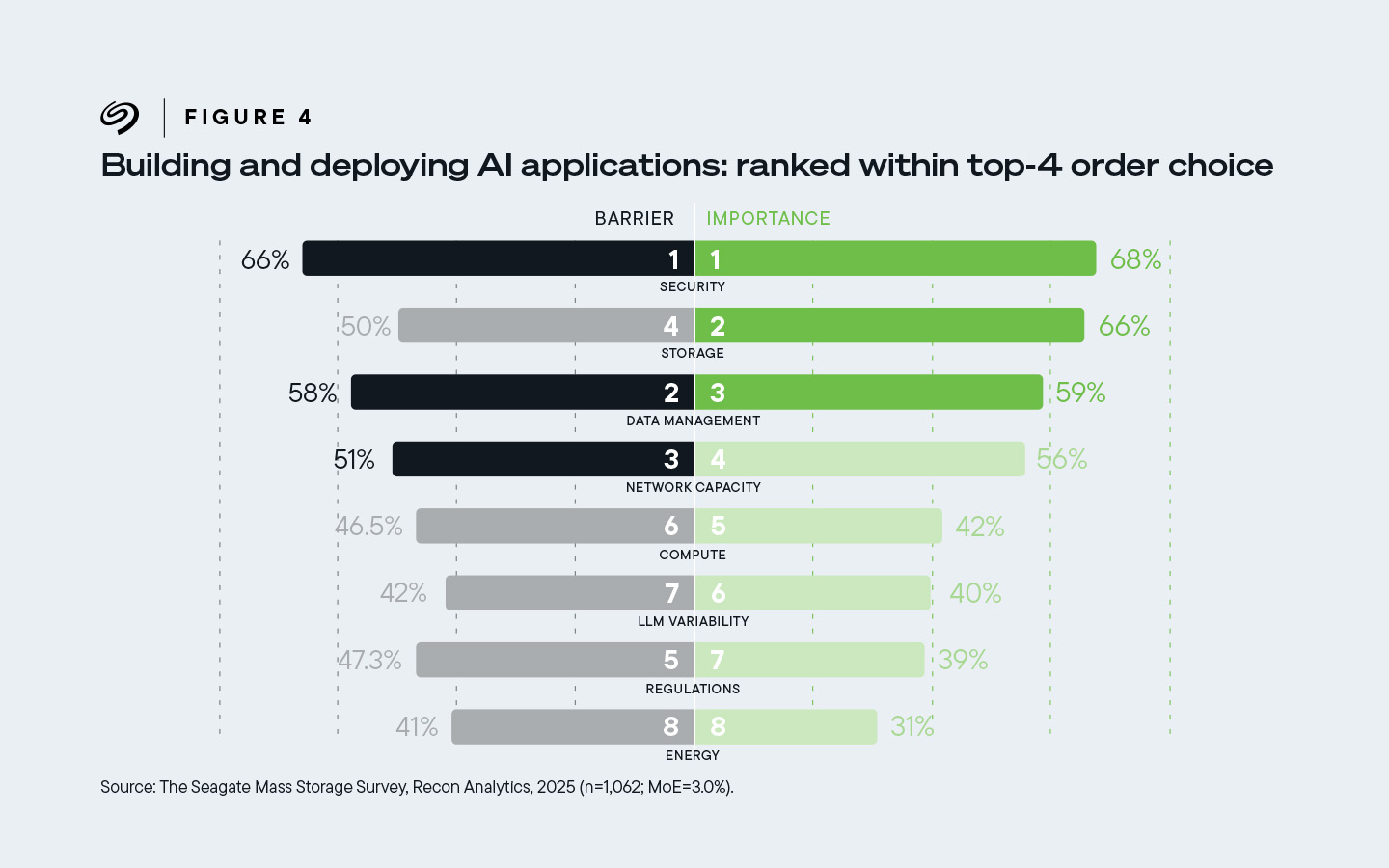
從基礎架構買家的角度來看,資料儲存對 AI 基礎架構的重要性僅次於安全性,排名第二。依重要性排序,安全和儲存之後依序是資料管理、網路容量、運算、法規、LLM 可行性和能源。
三分之二 (66%) 的受訪者將儲存列為他們認為最重要的四項人工智慧推動因素中的第二項,也是採用人工智慧的第四大障礙。
圖 4:66% 的基礎架構決策者將儲存列為他們認為最重要的四大人工智慧賦能因素中的第二重要組成部分。他們也將儲存列為 AI 部署的第四大障礙。
「調查結果普遍指出資料儲存需求即將激增,硬碟機顯然是贏家。考慮到我們調查的商業領袖們打算將越來越多的人工智慧驅動資料儲存在雲端,雲端服務已做好充分準備,迎接第二波成長。
Recon創辦人兼首席分析師Roger Entner將主要結論概括如下:
為了發揮人工智慧的最大價值,企業必須準備好易於擴充、效率良好的資料儲存裝置。無論是直接還是透過雲端服務,人工智慧對資料的依賴都依賴硬碟——硬碟提供無與倫比的容量、成本效益和永續性——作為值得信賴的人工智慧的支柱 。
硬碟為大規模人工智慧儲存提供了無可比擬的每TB成本優勢。大容量硬碟在可擴展性、能源效率和永續性方面實現了最佳平衡,使企業能夠在不超出預算或電力限制的情況下擴展儲存規模。