重點摘要
- 推理效能和成本越來越受到記憶體和資料移動的影響
- 智能體人工智慧需要持久的、長期存在的上下文訊息,這需要大容量硬碟儲存空間。
- 多層架構(硬碟 + GPU 記憶體 + NVMe SSD)有助於在不造成成本失控的情況下擴展上下文。
智能體人工智慧已成為下一個具有價值的營運前沿領域。
組織領導者需要能夠規劃、行動並隨著時間推移而改進的人工智慧系統——能夠執行多步驟工作流程並交付關鍵業務成果的代理。
但隨著複雜性和查詢量的增加,這些代理人所依賴的上下文保留能力的限制變得越來越不容忽視。
智能體可能會變得健忘——不是因為模型本身能力不足,而是因為其可用的、持久的上下文記憶有限。
人工智慧生態系統對此有一個專門的名稱:上下文牆。
上下文牆是指代理缺乏工作上下文,必須總結、丟棄信息,或反覆檢索和重新檢查先前訪問過的事實。這會減慢推理速度,增加成本,而且往往會降低品質。結果:答案前後矛盾,討論線索遺失。
上下文牆很快就會變成一個業務問題。它顯示為:
- 更高的計算成本(更多重工、更多檢索週期、更多代幣)
- 反應速度較慢(重新計算或重新載入上下文造成的延遲)
- 信任度較低(不同會話間行為不一致)
- 能力限制(智能體無法維持長期任務)
擴展上下文範圍只是部分地為了改進模型。這主要關乎你如何儲存和提供上下文資訊。
智能體人工智慧的聯合解決方案
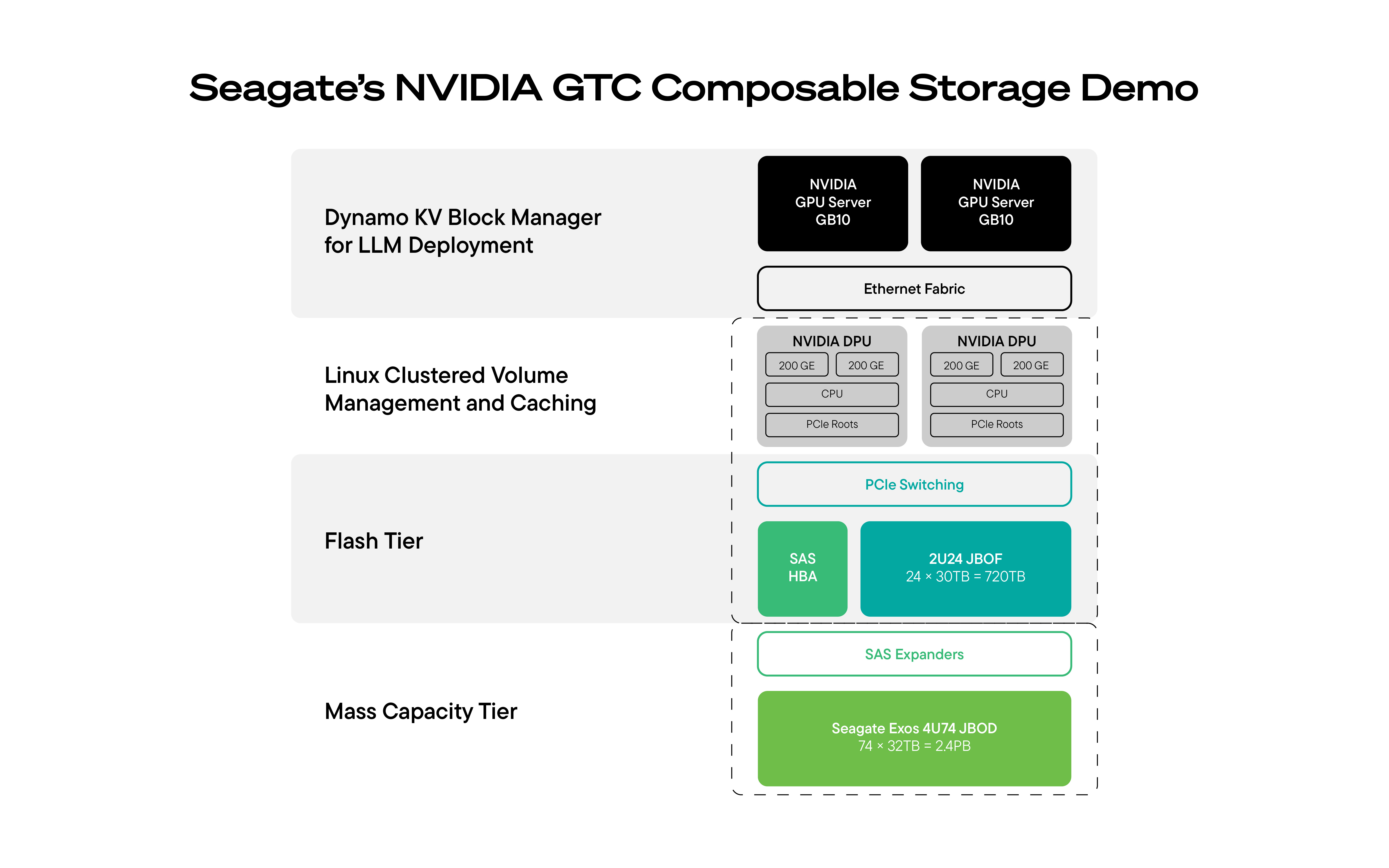
為了應對這項挑戰,Seagate 與其合作夥伴在 NVIDIA GTC 推出了一款可商用、可直接投入生產的多層級 AI 儲存解決方案,旨在為 AI 工作負載延伸上下文能力。
GTC 上展示的解決方案結合了:
這種架構之所以重要,不僅是因為它擴展了上下文,還因為它重新定義了組織應該如何看待人工智慧推理經濟學。一旦代理工作負載進入生產環境,記憶體和資料移動就成為效能、成本和可靠性的核心,而不僅僅是模型品質的核心。
Supermicro EMEA 總裁兼總經理、技術和人工智慧高級副總裁 Vik Malyala 表示:“將 Supermicro 的 JBOF 快閃記憶體層與 Seagate 的硬碟層相結合,可以大幅降低推理成本,同時提供高效能。”“隨著智能體人工智慧的廣泛應用和推理工作負載的指數級增長,這一點尤其重要。”
將記憶轉化為競爭優勢
這裡有一個很容易被忽視的轉變:推理正變得越來越像一個記憶體問題,而不僅僅是一個計算問題。GPU 功能強大,但要發揮其應有的效用,就需要以適當的速度、在適當的時間以適當的成本提供合適的資料。
代理程式渴望獲得更多上下文資訊儲存。除了提示訊息外,他們還需要追蹤以下內容:
- 漫長的對話與決策過程
- 政策和程序
- 產品和故障排除知識
- 日誌、工單和遙測數據
試圖將所有這些都保留在即時訪問層(GPU 內存或全閃存)就像堅持讓整個公司都使用高級當日送達服務一樣:對於少量包裹來說很好;但規模化後在經濟上是荒謬的。
成功的方案依賴多層永久儲存架構。
為什麼多層儲存是切實可行的解決方案
智慧AI堆疊將短期記憶和長期記憶分開,並讓每一層發揮最擅長的作用:
- 即時存取層級(GPU HBM 記憶體、CPU DRAM、本地和網路 NVMe SSD):處理當前情境-活動令牌、熱嵌入和頻繁存取的數據
- 容量層級(由硬碟建構):保存長期情境資訊-大型資料集、長期歷史記錄和擴展的代理內存
商業價值源自於一個簡單的原則:自動化所有層級的資料放置。讓 GPU 保持高負載運行,控製成本,並深入理解上下文。
DPU如何最佳化資料平面
從歷史上看,將人工智慧的性能等級和容量等級結合起來一直很混亂。它通常需要複雜的專有檔案系統、大量的 CPU 開銷和脆弱的調優——尤其是在資料量激增的情況下。
由於資料處理單元(DPU)的出現,這種情況正在改變。
DPU 可以卸載並加速資料傳輸,因此系統不會僅僅為了移動位元組而消耗主機 CPU 週期。它們能夠實現高速網路和儲存存取模式,並且可以運行基於 Linux 的標準服務,用於快取、分層、彈性和安全性。簡而言之,DPU 有助於實現多層 AI 儲存的部署和可擴充性。
這就是為什麼多層設計能夠在生產規模上行得通的原因。
多層架構的優勢
Seagate、Supermicro 和 NVIDIA 的架構將擴展 AI 環境所需的核心元件整合在一起,從而能夠以經濟高效的方式大規模擴展 AI 環境:GPU 運算用於推理,硬碟用於儲存大容量、長壽命的上下文訊息,NVMe SSD 用於即時訪問,DPU 用於協調跨層的資料移動和快取。
這種組合能夠促進客戶最關心的業務成果。
更深層的代理上下文意味著更好的商業價值
這種方法對客戶意味著什麼?
1.更好的代理存儲記憶——以及更好的結果
代理程式可以存取比 GPU 鄰近儲存空間所能容納的更多的歷史資料。這樣可以支持更長遠的推理、更豐富的個人化以及減少因遺忘上下文而導致的失敗。
2.降低規模化成本
硬碟為長期儲存提供了每TB極低的成本。這一點很重要,因為資料集和代理程式歷史記錄會不斷增長。
3.效率是下一個優化前沿
組織會追蹤效能(每秒令牌數)以及效率,包括每個令牌的功耗和持續 GPU 利用率等指標。多層設計有助於減少浪費的工作(重新載入、重新處理、重新檢索),並維持 GPU 的高效運作。
4.與人工智慧基礎設施的發展方向保持一致
DPU驅動的資料平面正成為現代人工智慧系統設計的核心。這種方法與這個方向一致:建立可擴展的資料交付體系,而不僅僅是原始運算能力。
拿出證據,而不是做出承諾:GTC示範及後續內容
在 GTC 大會上,該架構在一個運行的系統中得到了演示——GPU 用於推理,硬碟用於海量、深度上下文信息,SSD 用於即時訪問,DPU 用於協調高效的數據移動和緩存。
人工智慧仍處於發展初期。它將繼續消耗和產生大量數據。Seagate、Supermicro 與 NVIDIA 正攜手以更具永續性、更高效率、並可大規模擴展的架構來實現這樣的未來。
能夠成功擴展代理規模的組織,將會把上下文視為戰略資產,並建構能夠有效地儲存和提供上下文的基礎設施。
與專家洽談,了解 Seagate 如何協助您的組織突破自主式 AI 的上下文擴展瓶頸。






-v4.png/_jcr_content/renditions/4-3-small-416x312.png)