Donne accès, entre autres, aux formations sur les produits, aux ressources de vente et marketing, et à l'enregistrement des opportunités à nos revendeurs à valeur ajoutée, nos intégrateurs, nos revendeurs et nos autres partenaires de distribution.
Préparer l’infrastructure de données d’entreprise pour l’IA à grande échelle
Les charges de travail d’IA génèrent des volumes massifs de données structurées et non structurées. Pour prendre en charge les cycles d’entraînement, d’inférence et de réentraînement, les entreprises ont besoin d’un stockage évolutif et de grande capacité capable de gérer la croissance continue des données.
L’IA avance au rythme des données.
Et sans stockage massif et performant, elle n’ira pas loin. Les charges de travail d’IA génèrent des flux de données continus : ensembles de données d’entraînement, journaux d’inférence, métadonnées, embeddings et résultats de modèles. À mesure que l’IA générative et les grands modèles de langage (LLM) se développent, le volume et la variété des données d’entreprise augmentent de façon exponentielle. Cette croissance rapide exige des architectures de stockage capables de gérer une ingestion constante, un accès à haut débit et une conservation fiable dans le temps.
L’IA repose sur les données. Et les données reposent sur des disques durs à capacité élevée.
Ce sont les conclusions qui ressortent d’une enquête réalisée en 2025 par le cabinet d’études Recon Analytics.
L’enquête mondiale met en lumière la façon dont des entreprises issues de nombreux secteurs font évoluer leur infrastructure pour s’adapter aux charges d’IA. Les participants représentent des organisations qui utilisent déjà l’IA ou prévoient de l’adopter, offrant un éclairage concret sur les besoins en stockage, les défis d’évolutivité et l’avenir des infrastructures de données d’entreprise.
Cette enquête mondiale sollicitée par Seagate a mobilisé 1 062 participants. Ces derniers, des acheteurs de solutions de stockage informatique et des décisionnaires, occupent des postes en lien avec l’infrastructure de stockage au sein d’entreprises qui présentent un chiffre d’affaires annuel supérieur à 10 millions de dollars, utilisent plus de 50 To de stockage, ont adopté l’IA ou prévoient de le faire dans les trois années à venir, et sont situées aux États-Unis, en Chine, au Royaume-Uni, en Corée du Sud, à Singapour, en France, en Inde, au Japon, à Taïwan et en Allemagne.
L’enquête abordait principalement l’impact de l’adoption de l’IA sur les priorités d’infrastructure, ainsi que sur les stratégies de conservation et de gestion des données. Les conclusions mettent en lumière l’impact de l’IA sur les besoins en infrastructure des trois prochaines années.
Perspectives issues de l’enquête mondiale : Comment l’adoption de l’IA transforme l’infrastructure des données
La dernière enquête de Recon Analytics met en lumière un tournant majeur dans la manière dont les entreprises conçoivent leurs écosystèmes de données à l’ère de l’IA. L’IA n’est plus perçue comme un projet isolé. Les organisations revoient désormais en profondeur leurs stratégies de stockage, l’allocation de leurs ressources et la conception à long terme de leurs infrastructures pour accélérer son adoption. L’enquête révèle comment les responsables informatiques du monde entier se préparent à un avenir où la croissance des données, les exigences de conservation et les impératifs de performance progresseront à un rythme sans précédent.
Croissance des données d’IA jusqu’en 2028 : Pourquoi la demande de stockage pour l’IA explose-t-elle ?
Pour commencer, l’enquête a démontré que l’adoption de l’IA va engendrer une croissance exponentielle de la demande en stockage des données jusqu’en 2028.
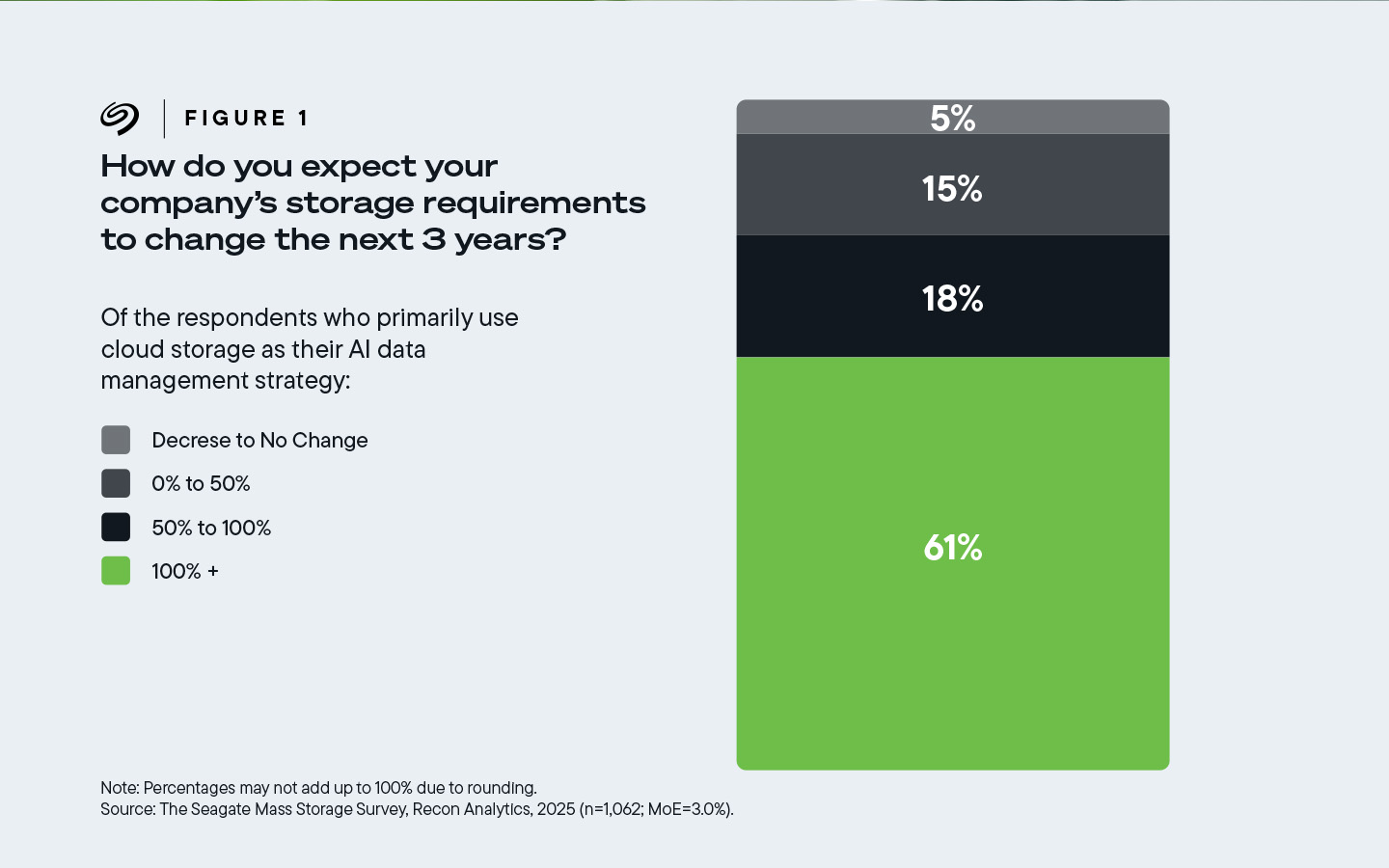
Pas moins de 61 % des participants dont l’entreprise utilise principalement le stockage dans le cloud, ont déclaré que celui-ci devra augmenter de plus de 100 %, autrement dit doubler, au cours des trois prochaines années.
Figure 1. 61 % des participants dont l’entreprise utilise principalement le stockage dans le cloud pour gérer ses données d’IA anticipent une augmentation d’au moins 100 % de leurs besoins de stockage.
Pourquoi la conservation des données à long terme améliore-t-elle la précision et la fiabilité de l’IA ?
Les applications d’IA génèrent des quantités de données à des niveaux inégalés. Or, plus ces données seront nombreuses, et plus les organisations pourront valider le bon fonctionnement de l’IA. Grâce aux données comportementales, telles que les ensembles de données d’entraînement, les points de contrôle des modèles, les invites et les réponses, il est possible d’analyser les algorithmes et de mieux comprendre la prise de décision liée à l’IA. Sans l’évolutivité et l’efficacité des centres de données, le potentiel de l’IA resterait limité, car la capacité à stocker et à récupérer des ensembles de données volumineux est indispensable à la réussite de l’IA.
Cette réussite ne repose pas uniquement sur la capacité de stockage. La durée de ce dernier importe également.
Des secteurs comme la finance, la santé, la fabrication et les services publics s’appuient sur l’archivage à long terme pour répondre aux exigences de conformité et d’audit. La conservation des données historiques renforce les dispositifs de gouvernance, facilite la création des rapports réglementaires et améliore la précision des résultats de l’IA au fil du temps.
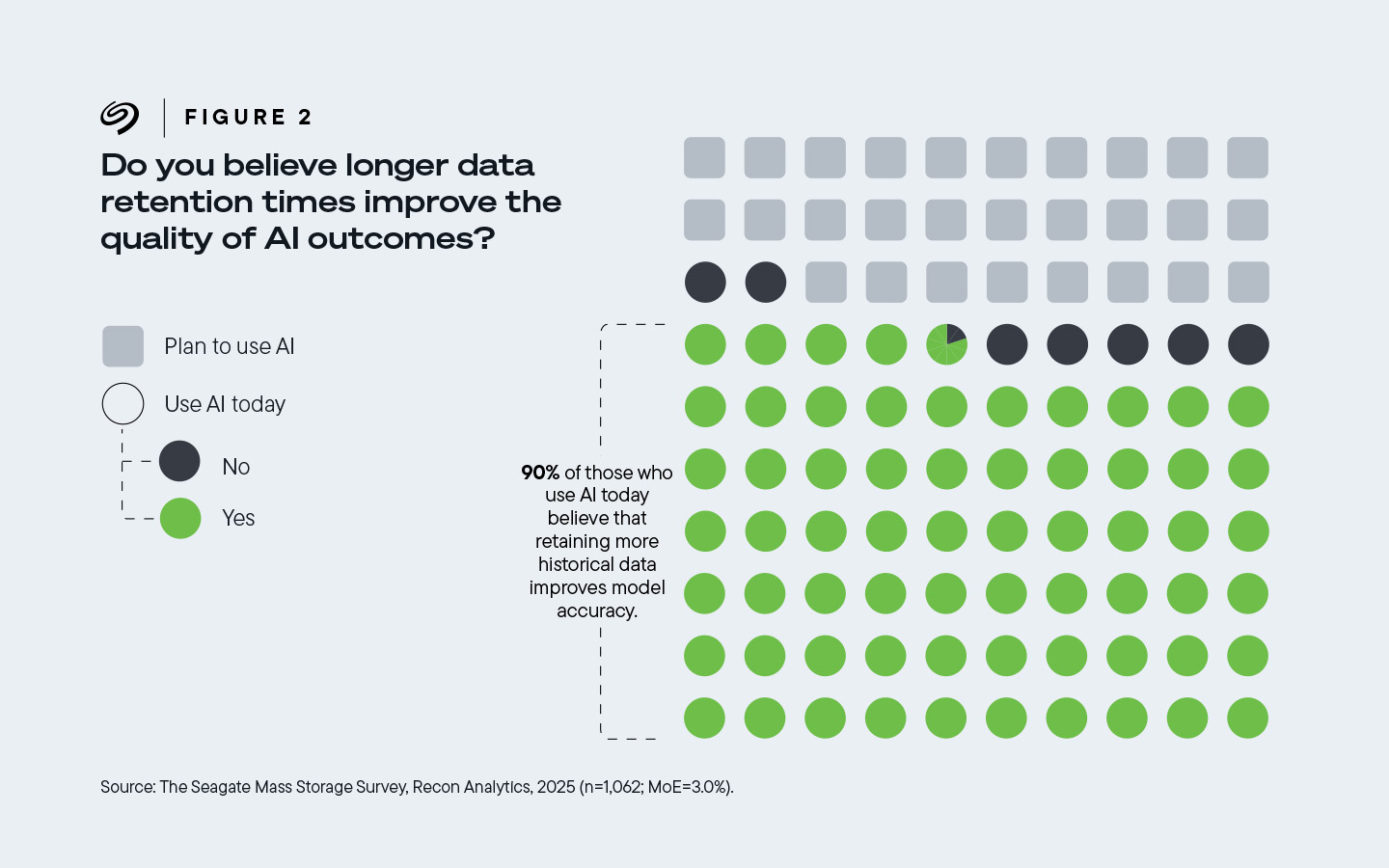
Parmi les personnes interrogées travaillant dans des entreprises qui ont adopté des technologies d’intelligence artificielle, 90 % estiment qu’une rétention plus longue des données améliore la qualité des résultats de l’IA.
Figure 2. 90 % des entreprises qui recourent aujourd’hui à l’IA estiment que la rétention d’un plus grand nombre de données historiques améliore la précision des modèles.
Ce résultat met en évidence un lien entre la durée de rétention des données et la fiabilité des analyses d'IA : plus cette durée est longue, plus les analyses sont fiables. Plusieurs facteurs peuvent expliquer ce phénomène. Tout d'abord, le traitement itératif constant est intrinsèque au fonctionnement des algorithmes d'IA. Les résultats sont réinjectés dans le modèle, ce qui améliore sa précision et permet d'en générer de nouveaux. Les ensembles de données bruts et les résultats sont utilisés en tant que sources pour d'autres développements et de nouveaux flux.
Rôle de la traçabilité des données, de la conformité et de la protection de la propriété intellectuelle dans une IA digne de confiance
L’allongement de la durée de rétention des ensembles de données profite aussi à d’autres fonctions critiques de l’entreprise, notamment la protection de la propriété intellectuelle. Il permet de conserver de véritables « preuves » des ensembles de données et des processus à l’origine des modèles, fournissant ainsi une explication des résultats lorsque cela est nécessaire (par exemple, dans le cadre d’une procédure judiciaire).
Ces éléments constituent la lignée des données : un enregistrement clair du parcours des données, de leur ingestion à leur exploitation. Grâce à cette traçabilité, les organisations peuvent retracer l’origine des ensembles de données et leur usage, afin de s’assurer que les modèles d’IA reposent sur des données exactes. Les systèmes d’IA deviennent ainsi entièrement vérifiables, ce qui renforce à la fois la conformité réglementaire et la responsabilité interne.
Les entreprises prennent également conscience qu’il est impossible de prévoir aujourd’hui quelles nouvelles informations exploitables les algorithmes de demain pourraient extraire des données d’hier. Elles choisissent donc de conserver davantage de données, et plus longtemps. Une rétention plus longue permet de traiter d’anciennes données avec des modèles d’IA encore à venir. Pour toutes ces raisons, prolonger la conservation des données accroît directement la valeur commerciale de l’IA.
De la même façon, les responsables de l’infrastructure considèrent l’allongement des périodes de rétention comme une condition essentielle pour instaurer la confiance : un socle indispensable sans lequel les analyses d’IA perdent une grande partie de leur valeur.
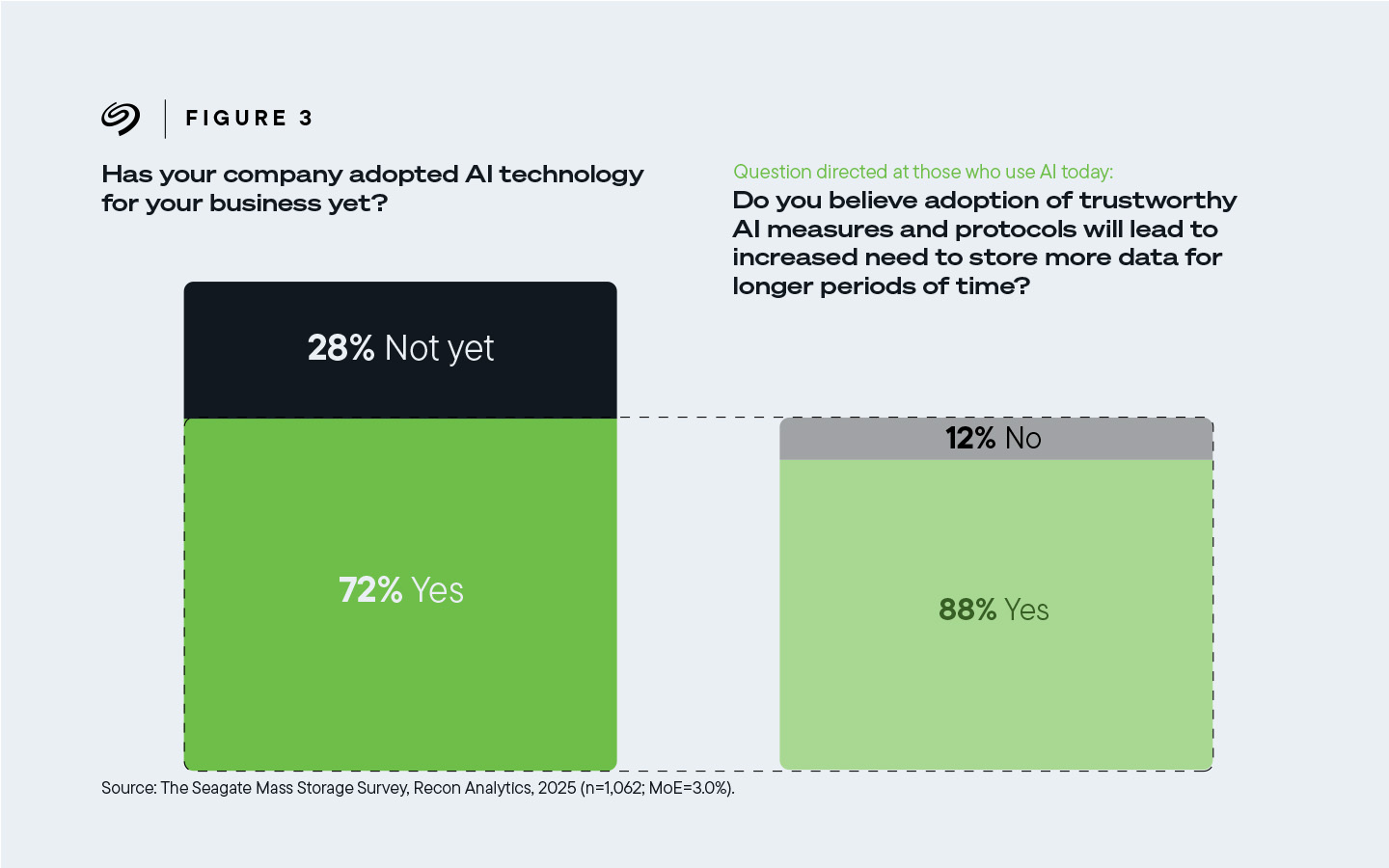
88 % des participants utilisant l’IA aujourd’hui considèrent que l’adoption d’une IA digne de confiance implique de devoir stocker davantage de données sur une plus longue durée.
Figure 3. 88 % des participants estiment que l’adoption d’une IA digne de confiance suppose de stocker davantage de données sur une plus longue période.
Pour Seagate, une IA digne de confiance est composée de flux de données et de modèles d’IA qui utilisent des entrées fiables pour générer des informations fiables. Une IA de confiance repose sur des données conformes aux critères suivants :
Une qualité et une précision optimales
Une légalité, une propriété et une provenance claires
Un stockage sécurisé et une protection
Des transformations explicables et traçables par l'algorithme
Des résultats cohérents et fiables du traitement des données
Une infrastructure de stockage évolutive permet de garantir la fiabilité de l’IA, car elle gère, stocke et sécurise correctement les vastes quantités de données utilisées par les systèmes d’IA.
Dans le cadre de la création d’une IA digne de confiance, 80 % des participants soulignent l’importance des points de contrôle.
Création de points de contrôle : Pourquoi les instantanés fréquents des modèles dépendent-ils d’un stockage sur disque dur fiable et de grande capacité ?
La création de points de contrôle consiste à sauvegarder l’état d’un modèle d’IA à de courts intervalles spécifiques au cours de son entraînement. Les modèles d’IA sont entraînés à traiter de vastes ensembles de données par le biais de processus itératifs qui peuvent durer de quelques minutes à plusieurs mois. La durée de l’entraînement d’un modèle dépend de sa complexité, de la taille de l’ensemble de données et de la puissance de calcul disponible. Pendant cette période, les modèles reçoivent des données, les paramètres sont ajustés et le système apprend à prédire des résultats à partir des informations qu’il traite.
Les points de contrôle agissent principalement comme des instantanés de l’état actuel du modèle (données, paramètres et réglages) à de nombreux moments de l’entraînement. Des instantanés effectués à intervalles réguliers documentent l’évolution du modèle et prémunissent contre toute perte de données en cas d’interruption imprévue.
D’après l’enquête, les entreprises qui stockent plus de 100 Po de données enregistrent et sauvegardent des points de contrôle quotidiens ou hebdomadaires, et 87 % d’entre elles les conservent dans le cloud ou sur une combinaison de disques durs et de SSD.
Pour créer des points de contrôle à cette échelle, elles ont besoin de systèmes de stockage capables d’absorber des écritures continues sans ralentir l’entraînement des modèles. Les disques durs haute capacité et les architectures cloud hybrides offrent la fiabilité et la rentabilité nécessaires pour maintenir ces cycles d’instantanés rapides. En capturant et en protégeant systématiquement les points de contrôle, les organisations préservent la progression de l’entraînement, accélèrent la reprise après les interruptions et garantissent des flux de travail de développement d’IA stables et prévisibles.
Stockage : L’ingrédient décisif d’une IA évolutive et rentable
Le calcul et l’énergie sont des thèmes récurrents dans les discussions sur l’adoption de l’IA. Toutefois, l’enquête menée par Recon Analytics montre que le stockage joue un rôle déterminant.
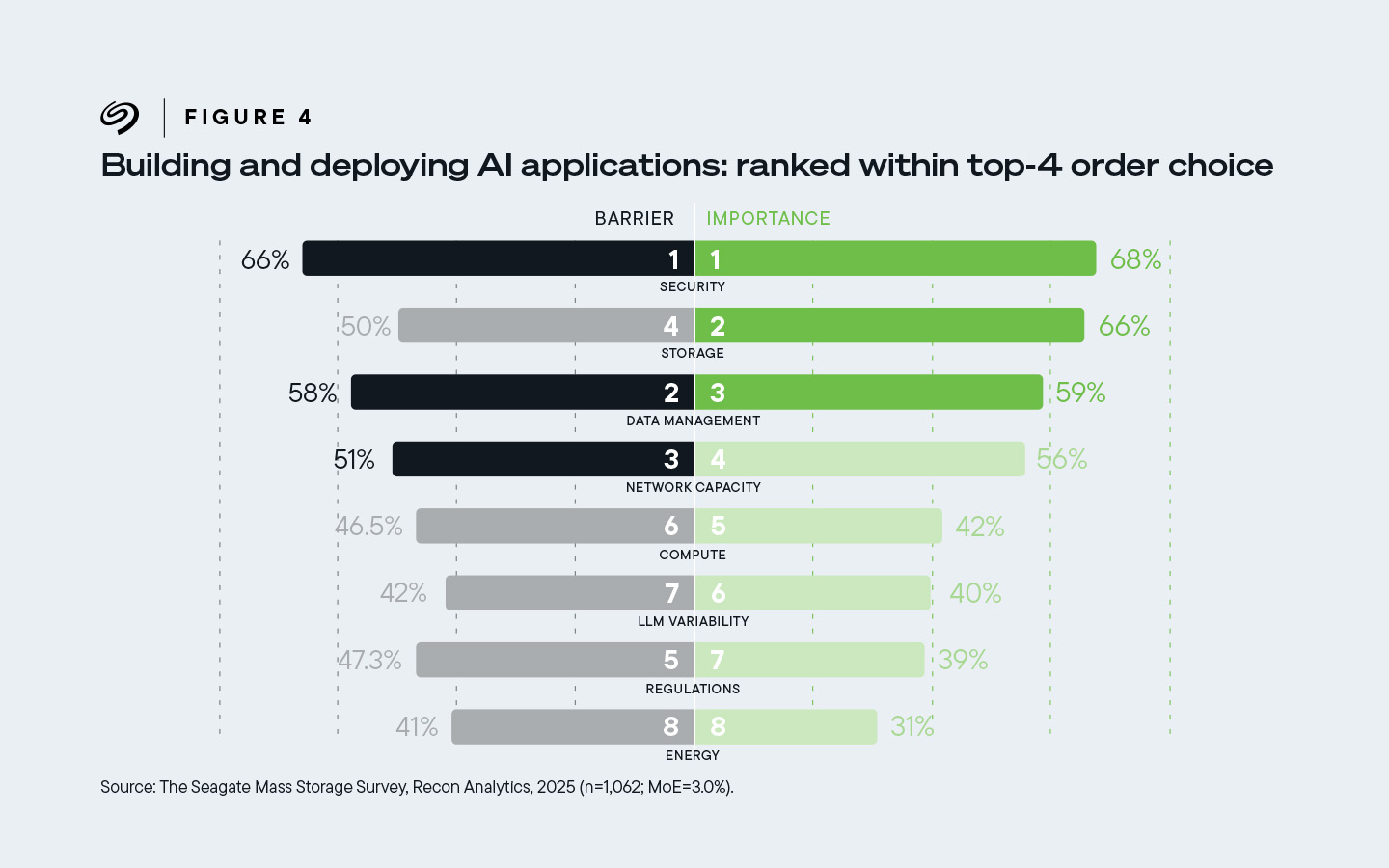
Du point de vue des acheteurs d’infrastructure, le stockage des données se classe en deuxième position, après la sécurité. Arrivent ensuite la gestion des données, la capacité du réseau, le calcul, les réglementations, la viabilité du LLM et l’énergie, par ordre d’importance.
Les deux tiers (66 %) des participants ont placé le stockage au deuxième rang des quatre principaux facteurs favorisant l’IA et au quatrième rang des principaux freins à son adoption.
Figure 4. 66 % des décisionnaires en matière d’infrastructure ont classé le stockage au deuxième rang des quatre principaux facteurs favorisant l’IA. Ils l'ont également classé au quatrième rang des principaux obstacles au déploiement de l'IA.
« Les résultats de l’enquête indiquent globalement une augmentation à venir de la demande de stockage de données, les disques durs étant les grands gagnants. Si l’on considère que les dirigeants d’entreprise interrogés ont l’intention de stocker de plus en plus de ces données basées sur l’IA dans le cloud, les services cloud sont bien placés pour surfer sur une deuxième vague de croissance. »
Roger Entner, fondateur et analyste principal de Recon, résume ainsi le principal enseignement :
Pour tirer le meilleur parti de l’IA, les entreprises doivent choisir un stockage de données évolutif et efficace. Que ce soit directement ou via les services cloud, la dépendance de l’IA aux données repose sur les disques durs. Offrant une capacité, une rentabilité et une durabilité inégalées, ils constituent la pierre angulaire d’une IA fiable.
Les disques durs offrent un coût par téraoctet inégalé pour le stockage IA à grande échelle. Les périphériques à capacité élevée assurent un équilibre optimal entre évolutivité, efficacité énergétique et durabilité, permettant aux entreprises d’étendre leur capacité de stockage sans dépasser leurs contraintes budgétaires ou énergétiques.