Seagateでは、私たちのエンジニアリングチームと私は、世界最大規模のクラウドおよびAIインフラ構築企業と定期的に意見交換を行っています。
エクサバイト規模の大容量ハードドライブを供給するだけでなく、私たちはお客様と緊密に連携し、ストレージアーキテクチャの構築を支援しています。
こうしたパートナーシップを通じて、ハイパースケール・ストレージの意思決定がどのように行われるかを、最前線で目の当たりにしてきました。共通するポイントは明らかです。パフォーマンス、効率性、そしてデータの価値を最大化するためには、経済性、ソフトウェアのオーケストレーション、そしてハードウェアの性能が調和していなければなりません。
AIワークロードの増加に伴い、データセットの規模、アクセス頻度、コンテキストウィンドウ、並列処理、保持期間、そして共有ストレージシステムへの負荷がますます高まっているため、こうした整合性はこれまで以上に重要になっています。
こうした規模の変化により、「プライマリストレージ」の意味は根本的に変わりました。
従来、プライマリストレージとは、演算処理装置の近くに配置された、密接に連携したブロックシステムやファイルシステムを指していました。しかし、クラウドやAI環境においては、プライマリストレージは、オブジェクトストレージをワークロード全体にわたる膨大な量のデータを保持・提供する永続的な記録システムとして扱う、ソフトウェア定義型のグローバルに分散されたアーキテクチャによって定義されるケースが増えてきています。
この再定義がどのように進んだのかをより深く理解するために、当初エンタープライズ・ストレージを形作った設計原則について詳しく見ていきましょう。
スケールがストレージのパラダイムをどう変えたか
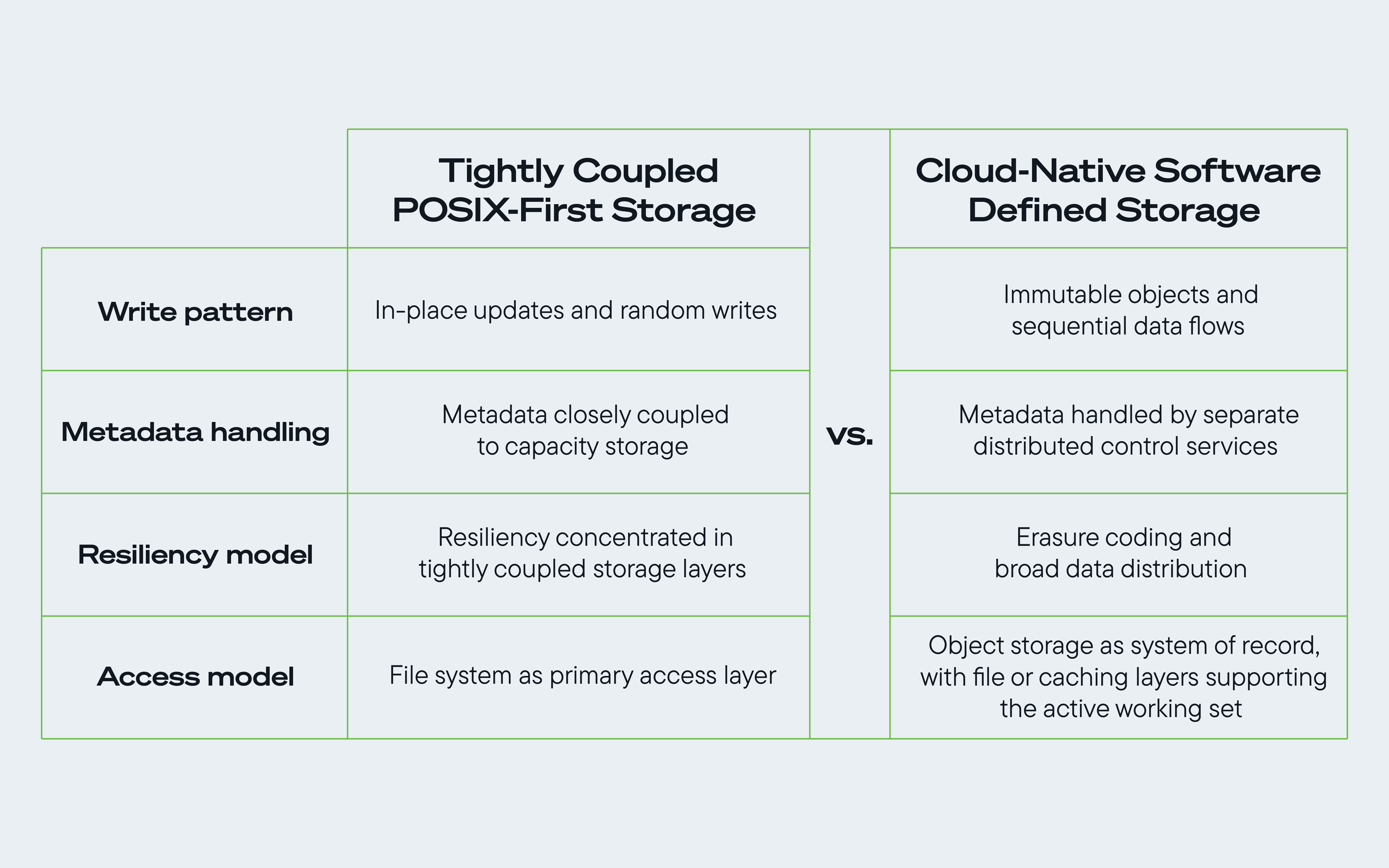
何十年もの間、このエコシステムは「ポータブル・オペレーティング・システム・インターフェース(POSIX)」という共通の標準に基づいて運用されてきました。よりローカルなインフラが主流だった時代に考案されたPOSIXは、開発者にデータとのやり取りを行うための予測可能なモデルを提供しました。
このシステムは、強力な書き込み後の読み取り一貫性、同期ファイルロック、および階層的なディレクトリ構造を重視していました。単一のマシンやローカルなクラスターにおいては非常に効果的であり、現在でも多くの企業環境やアプリケーション環境において不可欠な存在です。
しかし、クラウドモデルが登場すると、その際のトレードオフの関係は変わりました。クラウド規模のシステムは、POSIXファーストのシステムが当初想定していたものとは、規模、分散モデル、コスト構造の点で根本的に異なる要件に基づいて構築されました。
分散環境では、ディレクトリのセマンティクス、ファイルのロック、およびインプレース更新を維持するために、POSIXスタイルの実装ではノード間の大規模な調整が必要になる場合があります。
クラウドプラットフォームには大規模な拡張性が求められ、最終的には数十から数百エクサバイト規模まで対応できるようになりました。しかし、このような環境下では、密結合型の設計に伴う調整のオーバーヘッドがレイテンシを引き起こし始め、成長に実質的な制約をもたらすようになりました。
さらに大規模なデータセット、チェックポイント処理、トークン処理、推論、そして高度に並列化されたデータパイプラインを必要とする現代のAIワークロードにおいては、こうした課題はさらに深刻化しています。
業界全体において――Google Cloud Storage(GCS)やColossusから、Microsoft Azure Blob、Amazon S3、MetaのTectonicに至るまで――クラウドプラットフォームは、世界中に分散したデータやハイパースケールなワークロードに特化したソフトウェア定義アーキテクチャを採用し、規模や要件の変化に合わせて、長年にわたりそのアーキテクチャを洗練させてきました。
この新しいパラダイムでは、ソフトウェアがオーケストレーション、耐障害性、およびデータフローに対してより大きな役割を担うことで、基盤となるストレージメディアを可能な限り効率的に活用できるようになります。
ハードディスクは、大規模なストレージの基盤となります
私が上で言及したようなクラウドアーキテクチャにおいて、ハードディスクは、大規模なデータ保存の基盤となっています。
これは、容量に関する不変の経済原理と、高密度記録の物理的特性によるものです。現代の大容量ハードディスクドライブでは、Shingled Magnetic Recording(SMR)やHeat-Assisted Magnetic Recording(HAMR)といった技術が採用されており、面密度を向上させ続け、エクサバイト規模のストレージを実現しています。
この規模では、多数のハードドライブが基幹システムとして機能し、他のストレージ技術では到底及ばない耐久性、コスト効率、および大容量密度を実現します。
大規模データセンターのエクサバイト級のデータの87%がハードドライブに保存されているのには、理由があるのです1!
クラウド環境が拡大し続け、AIワークロードがより大量のデータを消費、生成、保持、再利用するにつれ、こうした利点はさらに重要なものとなります。
しかし、ソフトウェアアーキテクチャが大容量ディスクの強みを最大限に活かせるように設計されていなければ、その真価は発揮されません。
従来のPOSIXアクセスパターン――特に、断片的でランダムなインプレース更新を重視する、密結合型の分散ファイルシステムモデルにおいて――は、極端な規模において、必ずしもそれらの強みと十分に整合しているとは限りません。
最新のソフトウェア定義型クラウドプラットフォームは、ハードドライブを中核としたストレージスタックを設計することでこの課題に対処し、シーケンシャルで高スループットなデータフローを優先しつつ、拡張性に優れた運用コスト効率を実現しています。
Amazon S3の場合、500兆個のオブジェクトを保存し、毎秒2億件のリクエストを処理するこのサービスについて――最近のAWS re:Inventの基調講演2では、クラウドストレージのパフォーマンス向上の秘訣は、ハードドライブの性能を最大限に引き出すように最適化されたソフトウェアを開発することにあると強調されました。プレゼンテーションでは、このハードドライブは「工学の驚異」と評されていました。
ドライブを、別の時代に設計されたソフトウェアの抽象化モデルに無理に適合させるのではなく、現代のクラウドアーキテクチャは、最新の高密度ハードドライブの強みを最大限に活かすように設計されています。
クラウドアーキテクチャがハードドライブの効率性をいかに引き出すか
このエンジニアリング設計にはいくつかの形態がありましたが、主要なクラウドプラットフォーム全体を通じて、概ね4つのアーキテクチャ原則に基づいています。これらを総合すると、クラウドストレージが、データフロー、メタデータ、耐障害性、およびデータ取り込みの挙動の管理において、いかにソフトウェア主導型になってきているかがわかります。
1.オブジェクトの不変性は、順次的なデータフローに適しています
GCSやAmazon S3のようなサービスは、オブジェクトの不変性とバージョン管理された更新をサポートするように設計されています。データがオブジェクトストアに書き込まれると、更新処理は通常、既存のオブジェクトをその場で変更するのではなく、新しいバージョンのオブジェクトを書き込むことで行われます。
クラウド規模のアーキテクチャでは、ランダムなインプレースバイナリ書き込みの必要性を減らすことで、ディスクのワークロードをより大規模なシーケンシャルデータフローへとシフトさせます。これは、大容量ドライブが大規模な環境でスループットと効率を実現する仕組みと、よりよく合致しています。この利点は、チェックポイントの作成、データセットの移動、並列パイプラインなどが共有ストレージシステムに継続的な負荷をかけるAIワークロードにおいては、さらに重要になります。
2.メタデータは、独立した、あるいは分散型の管理サービスによって処理されるケースが増えています
従来のPOSIX環境では、ストレージシステムはファイルのメタデータとファイルのペイロードを密接に連携させて管理することがよくあります。ハイパースケール・クラウド・プラットフォームは、メタデータ・サービスとストレージ容量を分離することでこの状況を一変させました。これにより、追跡や調整の大部分を、ディスク自体に負担をかけるのではなく、より高速でスケーラブルな制御層に移行させたのです。
Google CloudのColossusは、こうした作業の多くをメモリ常駐型サービスに移行させていますが、MetaのTectonicは、分散ファイルシステムモデル内でメタデータを分離し、水平スケーラブルなキーバリューストア上で動作するステートレスなマイクロサービスとして実装しています。その結果、基盤となるハードドライブにかかる構造的なオーバーヘッドが軽減され、大規模な環境で高密度かつ効率的なストレージ容量を提供できる可能性が広がります。
3.イレイジャー符号化は分散システムの耐障害性を強化します
3つ目の原則は、消去符号化と広範なデータ分散を活用し、大規模ストレージシステムの耐障害性と効率性を高めることです。
クラウドアーキテクチャは、消去符号化と広範なデータ分散によって、その脆弱性を軽減します。オブジェクトを多数のディスクに分散させることで、これらのシステムは局所的な負荷の集中を隔離し、一時的な遅延の急増時でもデータ提供を継続し、必要に応じてデータを再構築することができます。これにより、ストレージ層の耐障害性が向上し、クラウドとAIのワークロードが混在する環境下でもスループットを維持しやすくなります。
4.多層データパス
4つ目の原則は、データがストレージメディアに書き込まれる前に、どのようにステージングされるかということです。
予測不可能なアプリケーショントラフィックと、高密度ハードドライブが最も得意とする構造化された環境とのギャップを埋めるため、最新のアーキテクチャでは、フラッシュやメモリを組み込んだ多層的なデータパスを採用し、データの取り込みをバッファリングするとともに、データ配置を最適化しています。
フラッシュ層は、APIトラフィックやアプリケーションからの書き込みによる変動する到着レートを吸収します。このシステムは、データがストレージメディアに転送される前に、そのデータをステージングおよび整理し、バックグラウンドプロセスが長い連続処理でハードドライブアレイに書き込むことを可能にします。
AIワークロードでは、データ取り込み、チェックポイントの作成、データセットの移動が特に突発的に発生しやすいため、このバッファリング機能は、低遅延でのデータ取り込みとハードドライブの効率的な利用の両方を維持するのに役立つことから、さらに重要になります。
図1.ハードドライブ中心のストレージアーキテクチャのメリットを最大限に引き出すための、従来のPOSIXストレージとクラウドネイティブストレージソフトウェアの比較。
一次記憶装置の新しいモデル
こうしたアーキテクチャ上の変化が相まって、プライマリストレージの定義そのものが一新されました。従来、「プライマリストレージ」とは、多くの場合、コンピューティング環境に密接に接続された、高価で可用性の高いブロックシステムやファイルシステムを指していました。オブジェクトストレージは、これまで主にアーカイブ、バックアップ、あるいはセカンダリデータ用の下位層の保存先として扱われてきました。
今日、多くのクラウドネイティブアーキテクチャでは、プライマリストレージをより広義に定義しています。すなわち、ステートレスなコンピューティングとグローバルなオブジェクトストアを組み合わせたものです。S3、Azure、GCSなどのプラットフォーム上に構築されたデータレイクは、大規模な分析、クラウドアプリケーション、AIワークフローにおける記録システムとしての役割をますます果たすようになっています。
このモデルでは、プライマリストレージはますますソフトウェア定義型となり、オブジェクトサービス、メタデータ層、フラッシュバッファリング、および大容量ハードドライブが連携して、統合されたシステムとして機能します。
コンピュートインスタンスは、多くの場合、より弾力性が高くステートレスなものと見なされており、オブジェクト層からデータを取得して処理し、その結果を同じ共有環境に書き戻します。
オブジェクトストレージとファイルセマンティクスの融合
過去10年間でオブジェクトストレージがクラウドアーキテクチャの中核となり、さらに最近ではAIワークフローにおいても重要な役割を果たすようになるにつれ、もう一つの重要なトレンドが現れました。それは、高性能な並列ファイルシステムです。
Lustre、Weka、VAST などのシステムは、密結合型のワークロードにおいてパフォーマンスを最大化するように設計されており、チェックポイント機能、協調処理、および高スループットのデータアクセスをサポートするために、POSIX 準拠のインターフェースを提供することがよくあります。
一方で、オブジェクトストレージプラットフォームは進化を続けており、グローバルなスケーラビリティを最適化するとともに、拡大するAIやデータ集約型のワークロードに対応できるよう、パフォーマンスの向上を図っています。
大規模なクラウドおよびAI環境において、これらのアプローチは融合しつつあります。高性能ファイルシステムは、多くの場合、オブジェクトストレージのバックエンドの上に構築されるか、または階層化され、アクティブなワーキングセット向けのパフォーマンスと、記録用システムとしてのオブジェクトストレージの拡張性およびコスト効率を両立させています。
この融合は、より広範なアーキテクチャの変遷を反映しています。すなわち、現代のシステムでは、ファイルとオブジェクトのどちらかを選択するのではなく、両者を組み合わせているのです。オブジェクトストレージのスケールメリットを損なうことなく、フォルダやネームスペース、そして使い慣れたファイル操作の利便性を維持しています。
クラウドおよびAIインフラ構築事業者への示唆
これらの変化を総合的に見ると、より広範な結論が導き出されます。すなわち、クラウドやAIのアーキテクチャでは、POSIXファーストのモデルが当初最適化を目的として設計されたものとは異なる、ソフトウェアとシステムに関するトレードオフが必要とされたということです。
こうしたトレードオフにより、システムが構築されている基盤となるハードドライブ・フリートの利用を最適化するようソフトウェアを設計することの重要性が高まりました。その意味で、クラウドやAIのワークロードは、ストレージのアーキテクチャを変えただけでなく、プライマリストレージそのものを再定義したのです。
インフラ構築者にとって、その教訓は明らかです。現代のシステムを設計するとは、プライマリストレージがローカルのOSファイルツリーにきっちりと対応していなければならないという前提を乗り越えることを意味します。つまり、大規模なAIの経済的側面、物理的特性、およびワークロードの実情に見合ったソフトウェアとアクセスモデルを選択することを意味します。
これを適切に実現できた組織は、GPUの利用率向上、推論コストの削減、パフォーマンスのボトルネック解消により、AI戦略を効率的に実行できる体制を整えることができるでしょう。
世界最大級のAIおよびクラウドインフラ構築企業を支えるプライマリストレージを支える、ハードドライブの革新技術について詳しくご覧ください。
出典
1.IDC Datasphere および IDC Storagesphere
2.AWS re:Invent 2025、アンディ・ウォーフィールド氏の基調講演:S3は500兆個以上のオブジェクトを保存し、毎秒2億件のリクエストを処理し、年間1兆兆件以上のリクエストを処理しています