Proporciona acceso a capacitaciones sobre productos; recursos sobre mercadeo y ventas; registros de ofertas y más para nuestros distribuidores de valor agregado (VAR), integradores, distribuidores y otros socios de canal.
Preparación de la infraestructura de datos empresariales para la IA a gran escala
Las cargas de trabajo de IA generan volúmenes masivos de datos estructurados y no estructurados. Para respaldar los ciclos de capacitación, inferencia y reentrenamiento, las empresas necesitan almacenamiento escalable y de alta capacidad que pueda manejar el crecimiento continuo de los datos.
No hay éxito en materia de IA sin datos (y sin muchos).
Y no hay conjuntos de datos masivos sin un almacenamiento de datos amplio y eficiente. Las cargas de trabajo de IA crean flujos de datos continuos, desde conjuntos de datos de entrenamiento y registros de inferencia hasta metadatos, incrustaciones y resultados de modelos. A medida que la IA generativa y los modelos de lenguaje grande (LLM) se expanden, el volumen y la variedad de los datos empresariales crecen exponencialmente. Este rápido escalamiento exige arquitecturas de almacenamiento que puedan gestionar la ingesta constante, el acceso de alta velocidad y la conservación confiable a lo largo del tiempo.
Los datos respaldan la IA y los discos duros de gran capacidad respaldan los datos.
Estos conocimientos se ponen de manifiesto en una encuesta realizada en 2025 por la empresa de investigación Recon Analytics.
La encuesta global proporciona detalles de cómo las empresas de múltiples industrias están adaptando su infraestructura para respaldar la IA. Los encuestados representan organizaciones que ya utilizan o planean utilizar IA y ofrecen información sobre las demandas de almacenamiento, los desafíos de escalabilidad y el futuro de la infraestructura de datos empresariales.
La encuesta global encargada por Seagate consultó a 1,062 participantes. Son compradores y tomadores de decisiones de almacenamiento de TI que trabajan en roles de infraestructura de almacenamiento para empresas que informan más de $10 millones en ingresos anuales, tienen más de 50 terabytes (TB) de uso de almacenamiento actual, han adoptado IA o planean adoptar IA en los próximos tres años y están ubicadas en Estados Unidos, China, Reino Unido, Corea del Sur, Singapur, Francia, India, Japón, Taiwán y Alemania.
La encuesta se centró en los efectos de la adopción de IA en las prioridades de infraestructura, la retención de datos y la gestión de datos. Los resultados arrojan luz sobre cómo la IA afectará las necesidades de infraestructura en los próximos tres años.
Perspectivas de la encuesta global: Cómo la adopción de IA transformará la infraestructura de datos
La última encuesta de Recon Analytics revela un cambio fundamental en cómo las empresas están planificando sus ecosistemas de datos para la era de la IA. En lugar de tratar la IA como una iniciativa aislada, las organizaciones ahora están reevaluando las estrategias de almacenamiento, la asignación de recursos y el diseño de infraestructura a largo plazo en respuesta a la aceleración de la adopción de la IA. La encuesta captura cómo los líderes globales de TI se están preparando para un futuro donde el crecimiento de datos, los requisitos de retención y las expectativas de rendimiento aumentarán más rápido que nunca.
Crecimiento de los datos de IA hasta 2028: ¿Por qué está aumentando la demanda de almacenamiento de IA?
En primer lugar, la encuesta demostró que la adopción de IA está impulsando un crecimiento exponencial en la demanda de almacenamiento de datos hasta 2028.
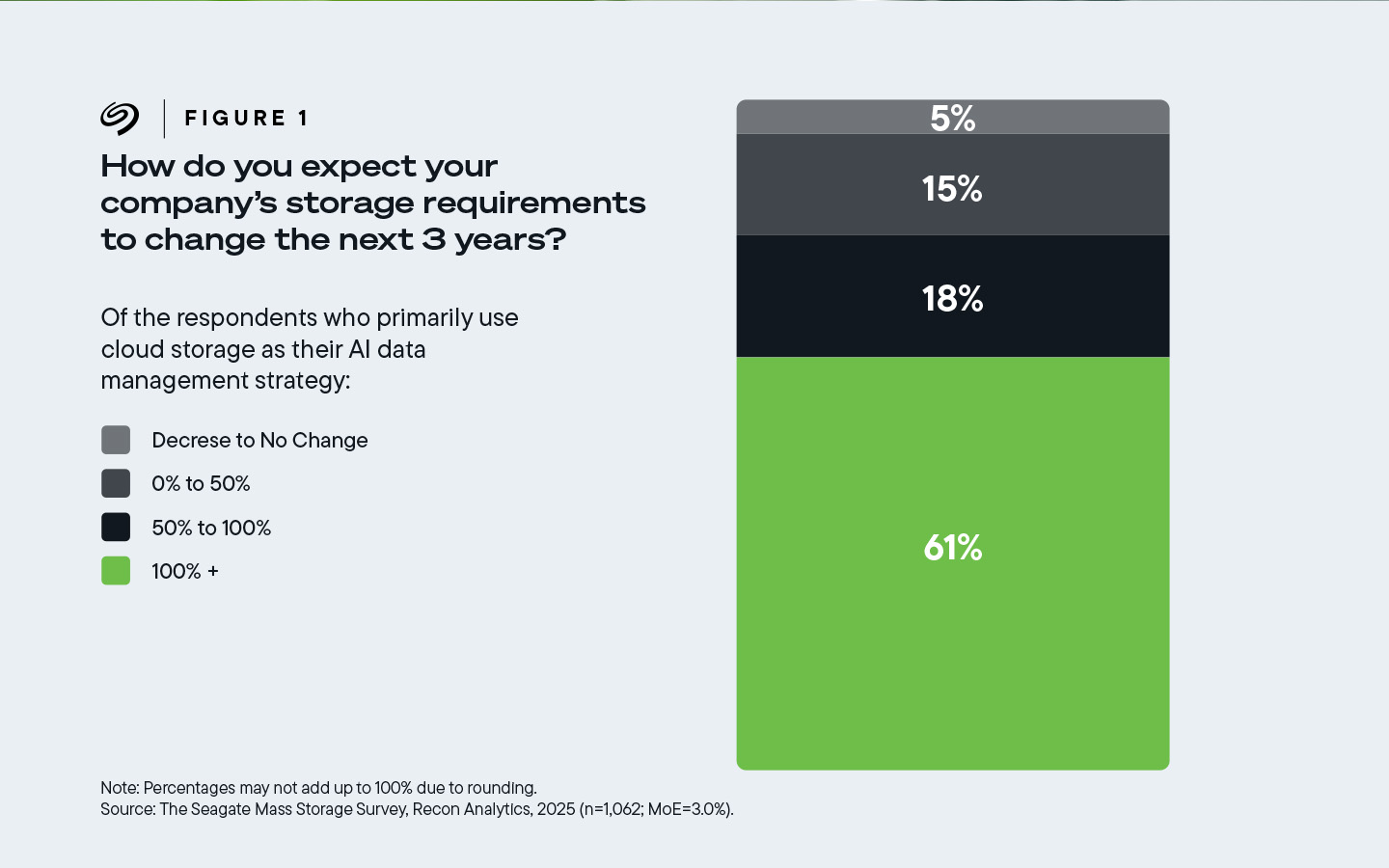
Hasta un 61% de los encuestados de empresas que utilizan predominantemente almacenamiento en la nube dijeron que el almacenamiento basado en la nube de sus empresas tendría que aumentar en más del 100% —es decir, tendría que duplicarse— en los próximos tres años.
Figura 1. El 61% de los encuestados cuyas empresas utilizan principalmente almacenamiento en la nube para la gestión de datos de IA esperan aumentar sus requisitos de almacenamiento en un 100% o más.
Por qué la retención de datos a largo plazo mejora la precisión y la confiabilidad de la IA
A medida que las aplicaciones de IA impulsan la creación de datos sin precedentes, cuanto más datos guarden las organizaciones, más podrán validar que la IA actúa como se espera. Con acceso a datos de comportamiento (como conjuntos de datos de entrenamiento, puntos de control de modelos, indicaciones y respuestas), las empresas pueden examinar algoritmos y comprender y refinar mejor la toma de decisiones de IA. Sin la escala y la eficiencia de los centros de datos, el potencial de la IA sería limitado, ya que la capacidad de almacenar y recuperar conjuntos de datos masivos es fundamental para el éxito de la IA.
No es solo la cantidad de almacenamiento lo que impulsa el éxito de la IA. La duración del almacenamiento de datos también es importante.
Industrias como las finanzas, la atención médica, la manufactura y las operaciones gubernamentales dependen de la retención a largo plazo para cumplir con los requisitos de cumplimiento y las necesidades de auditoría. La conservación de datos históricos fortalece los marcos de gobernanza, respalda los informes regulatorios y hace que los resultados de IA sean más precisos a lo largo del tiempo.
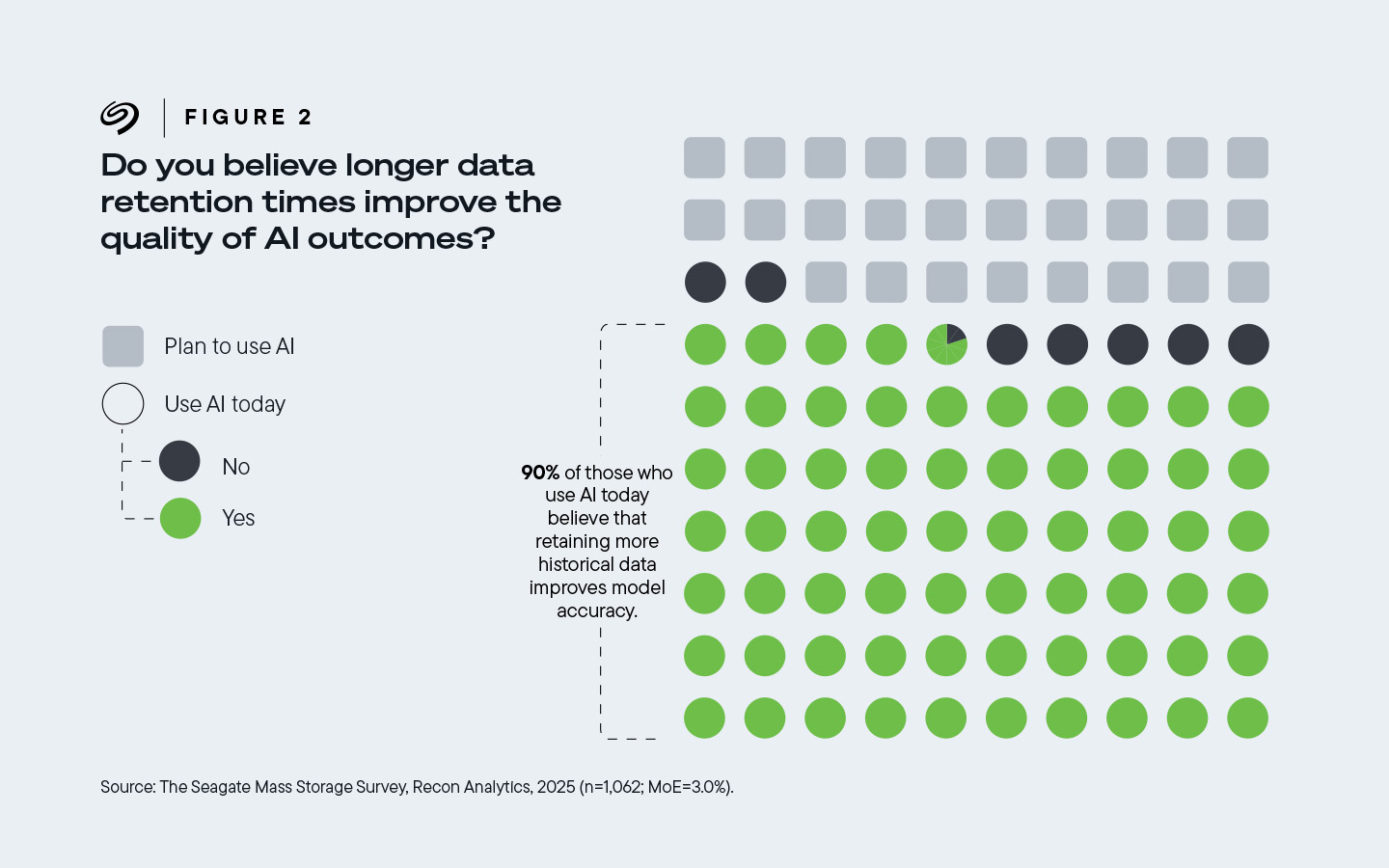
Del total de encuestados que trabajan para empresas que han adoptado tecnología de IA, el 90 % cree que una mayor retención de datos mejora la calidad de los resultados de la IA.
Figura 2. El 90% de las empresas que utilizan IA hoy en día creen que conservar más datos históricos mejora la precisión del modelo.
Este hallazgo apunta a una correlación entre la conservación de datos durante períodos más largos y una información más confiable por parte de la IA. Esto puede deberse a varios factores. En primer lugar, el procesamiento iterativo constante es intrínseco al funcionamiento de los algoritmos de la IA. Las salidas de contenido retroalimentan el modelo, lo cual mejora su precisión y permite nuevos modelos. Los conjuntos de datos sin procesar y los resultados se convierten en fuentes para un mayor desarrollo y nuevos flujos de trabajo.
El papel del linaje de datos, el cumplimiento normativo y la protección de la propiedad intelectual en una IA confiable
Pero conservar conjuntos de datos durante más tiempo también cumple otras funciones críticas para el negocio, porque protege la propiedad intelectual de una empresa. Mantiene “recibos” de los conjuntos de datos y procesos originales del modelo, y proporciona una explicación de los resultados cuando es necesario (por ejemplo, como parte de un proceso legal).
Estos recibos establecen el linaje de los datos y describen un registro claro del recorrido que realizan los datos desde la entrada hasta la salida. El linaje de datos permite a las organizaciones rastrear el origen y el uso de los conjuntos de datos, por lo que los modelos de IA se basan en datos precisos. Permite que los sistemas de IA sean totalmente auditables y respalda tanto el cumplimiento normativo como la responsabilidad interna.
Además, las empresas pueden optar por almacenar más datos durante más tiempo porque se dan cuenta de que no pueden saber hoy qué información nueva y valiosa podrían descubrir los algoritmos del mañana a partir de los datos de ayer. Una mayor retención de datos permite el procesamiento de datos antiguos por parte de modelos de IA aún no desarrollados. Por estas razones, una mayor retención de datos aumenta el valor comercial que puede proporcionar la IA.
En un hallazgo relacionado, los tomadores de decisiones de infraestructura consideran que la retención extendida de datos es esencial para generar confianza, una base fundamental sin la cual los conocimientos de IA tienen poco valor.
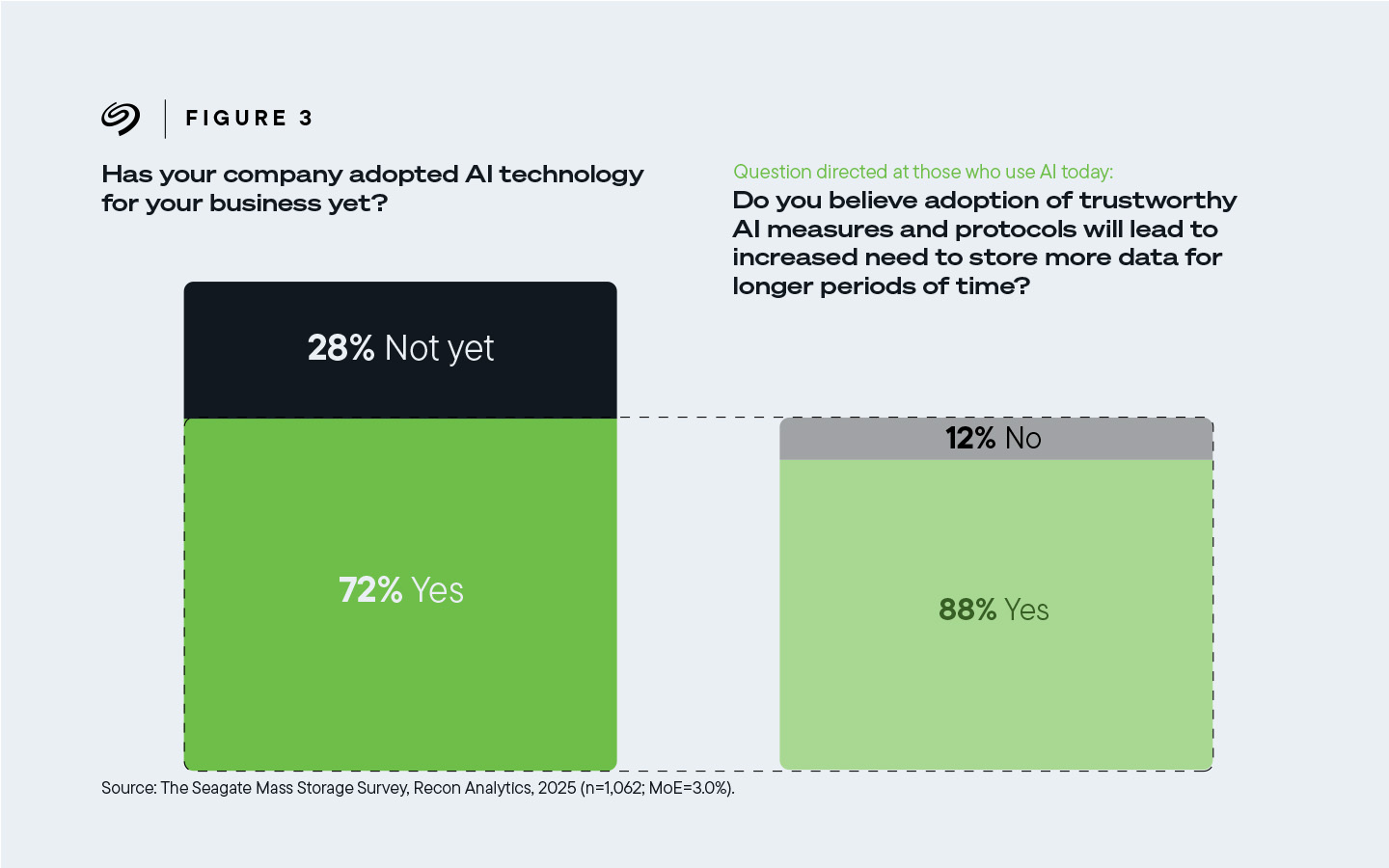
El 88 % de los encuestados cuyas empresas usan IA en la actualidad creen que la adopción de una IA confiable aumenta la necesidad de almacenar más datos durante más tiempo.
Figura 3. El 88% de los encuestados cuyas empresas utilizan IA hoy dijeron que la adopción de una IA confiable requiere una mayor necesidad de almacenar más datos durante períodos de tiempo más prolongados.
Seagate define la IA confiable como flujos de trabajo y modelos de datos de IA que utilizan entradas confiables y generan información fiable. La IA de confianza se basa en datos que cumplen los siguientes criterios:
Alta calidad y precisión
Clara legalidad, propiedad y procedencia
Almacenamiento y protección seguros
Transformaciones explicables y rastreables por el algoritmo
Resultados consistentes y confiables del procesamiento de datos
La infraestructura de almacenamiento escalable respalda una IA confiable porque administra, almacena y protege adecuadamente grandes cantidades de datos utilizados por los sistemas de IA.
Como parte de la construcción de una IA confiable, el 80% de los encuestados destacó la importancia de los puntos de control.
Puntos de control: Por qué las instantáneas frecuentes de modelos dependen de un almacenamiento en disco duro confiable y de alta capacidad
Un punto de control es el proceso de guardar el estado de un modelo de IA en intervalos cortos específicos durante su entrenamiento. Los modelos de IA se entrenan en grandes conjuntos de datos a través de procesos iterativos, que pueden llevar desde minutos hasta meses. La duración del entrenamiento de un modelo depende de la complejidad del modelo, el tamaño del conjunto de datos y la potencia computacional disponible. Durante este tiempo, los modelos se alimentan de datos, se ajustan los parámetros y el sistema aprende a predecir resultados basándose en la información que procesa.
Los puntos de control actúan esencialmente como instantáneas del estado actual del modelo (sus datos, parámetros y configuraciones) en muchos puntos durante el entrenamiento. Las instantáneas guardadas a intervalos regulares conservan un registro de la progresión del modelo y protegen contra la pérdida de datos causada por interrupciones inesperadas.
Según la encuesta, las empresas que utilizan más de 100 PB de almacenamiento guardan y realizan copias de seguridad de los puntos de control a diario o semanalmente, y el 87 % de ellas almacenan estos puntos de control en la nube o en una combinación de discos duros y SDD.
Para soportar puntos de control a esta escala, las empresas necesitan sistemas de almacenamiento capaces de mantener una actividad de escritura constante sin interrumpir el progreso del modelo. Los discos duros de alta capacidad y las arquitecturas de nube híbrida brindan la confiabilidad y la rentabilidad necesarias para mantener estos ciclos rápidos de instantáneas. Al capturar y proteger constantemente los puntos de control, las organizaciones pueden salvaguardar el progreso de la capacitación, acelerar la recuperación de las interrupciones y mantener flujos de trabajo de desarrollo de IA estables y predecibles.
Almacenamiento: El secreto detrás de los sistemas de IA escalables y rentables
La computación y la energía son temas populares en las discusiones sobre la adopción de la IA. Pero la encuesta de Recon Analytics destaca el almacenamiento como el factor crítico.
Desde la perspectiva de los compradores de infraestructura, el almacenamiento de datos se clasificó como la segunda parte más importante de la infraestructura de la IA, solo por detrás de la seguridad. A la seguridad y el almacenamiento les siguieron la gestión de datos, la capacidad de la red, la computación, las regulaciones, la viabilidad de LLM y la energía, en orden de importancia.
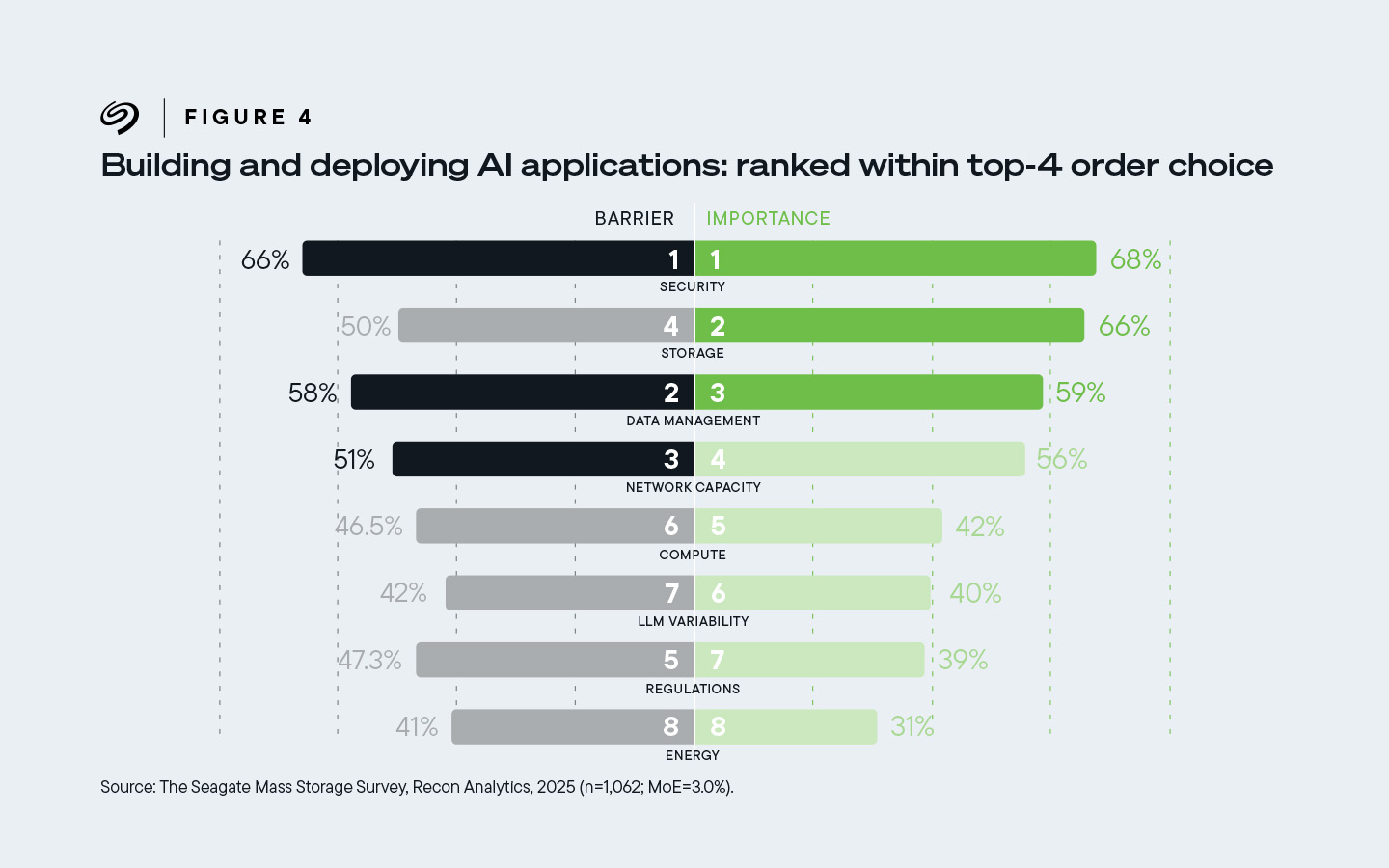
Dos tercios (66%) de los encuestados clasificaron el almacenamiento como el segundo factor más importante entre sus cuatro principales facilitadores de IA, y como la cuarta barrera más importante para la adopción.
Figura 4. El 66% de los tomadores de decisiones de infraestructura clasificaron el almacenamiento como el segundo componente más importante entre sus cuatro principales facilitadores de IA. También clasificaron el almacenamiento como la cuarta barrera más importante para la implementación de la IA.
“Los resultados de la encuesta generalmente apuntan a un próximo aumento en la demanda de almacenamiento de datos, con las unidades de disco duro emergiendo como el claro ganador. Si tenemos en cuenta que los líderes empresariales que encuestamos tienen la intención de almacenar cada vez más datos impulsados por IA en la nube, los servicios en la nube están bien posicionados para aprovechar una segunda ola de crecimiento”.
Roger Entner, fundador y analista principal de Recon, describe la principal conclusión de la siguiente manera:
Para obtener el máximo valor de la IA, las empresas deben prepararse con un almacenamiento de datos escalable y eficiente. Ya sea directamente o a través de servicios en la nube, la dependencia de la IA de los datos depende de los discos duros (que ofrecen capacidad, rentabilidad y sostenibilidad inigualables) como la columna vertebral de una IA confiable.
Los discos duros ofrecen ventajas inigualables en costo por TB para el almacenamiento de IA a gran escala. Los discos duros de gran capacidad ofrecen el equilibrio óptimo entre escalabilidad, eficiencia energética y sostenibilidad, lo que permite a las empresas ampliar las capacidades de almacenamiento sin exceder el presupuesto o las limitaciones de energía.