Tutaj, w Seagate, moje zespoły inżynierów i ja regularnie spotykamy się z największymi na świecie twórcami infrastruktury chmurowej i sztucznej inteligencji.
Oprócz dostarczania eksabajtów dysków twardych o dużej pojemności, współpracujemy z nimi, aby pomóc im kształtować architekturę pamięci masowej.
Dzięki tym partnerstwom miałem okazję osobiście przekonać się, w jaki sposób podejmowane są decyzje dotyczące pamięci masowych o dużej skali. Wspólny mianownik jest oczywisty: ekonomia, koordynacja oprogramowania i możliwości sprzętu muszą być ze sobą spójne, aby zmaksymalizować wydajność, efektywność i wartość danych.
To dostosowanie stało się jeszcze ważniejsze, ponieważ obciążenia sztucznej inteligencji stale zwiększają rozmiary zbiorów danych, częstotliwość dostępu, okna kontekstowe, paralelizm, czas retencji i wymagania stawiane systemom współdzielonej pamięci masowej.
Te zmiany skali zasadniczo zmieniły znaczenie pojęcia „pamięć podstawowa”.
Historycznie rzecz biorąc, termin „pamięć podstawowa” odnosił się do ściśle powiązanych bloków lub systemów plików, zlokalizowanych blisko komputerów. W środowiskach chmurowych i sztucznej inteligencji pamięć podstawowa jest coraz częściej definiowana przez programowo zdefiniowane, globalnie rozproszone architektury, które traktują pamięć masową obiektów jako trwały system rekordów przechowujący i udostępniający ogromne ilości danych w różnych obciążeniach.
Aby lepiej zrozumieć, jak przebiegała ta redefinicja, przyjrzyjmy się zasadom projektowania, które pierwotnie ukształtowały pamięć masową dla przedsiębiorstw.
Jak skala zmieniła paradygmat przechowywania danych
Przez dziesięciolecia ekosystem funkcjonował w oparciu o wspólny standard: Portable Operating System Interface (POSIX). Opracowany w erze bardziej zlokalizowanej infrastruktury, POSIX udostępnił programistom przewidywalny model interakcji z danymi.
Kładziono w nim nacisk na silną spójność odczytu po zapisie, synchroniczne blokowanie plików i hierarchiczną strukturę katalogów. Było to bardzo skuteczne rozwiązanie zarówno dla pojedynczej maszyny, jak i dla lokalnego klastra, a obecnie nadal ma kluczowe znaczenie dla wielu środowisk korporacyjnych i aplikacyjnych.
Jednak wraz z pojawieniem się modelu chmurowego, decydujące o tym kompromisy uległy zmianie. Systemy działające w chmurze zostały stworzone z myślą o zupełnie innej skali, modelu dystrybucji i strukturze kosztów niż te, do których pierwotnie zaprojektowano systemy POSIX.
W środowisku rozproszonym implementacje w stylu POSIX mogą wymagać znacznej orkiestracji między węzłami w celu zachowania semantyki katalogów, blokowania plików i aktualizacji na miejscu.
Platformy chmurowe wymagały ogromnej skali — z czasem musiały zostać rozbudowane do obsługi dziesiątek, a nawet setek eksabajtów — a w tym środowisku obciążenie koordynacyjne ściśle powiązanych projektów zaczęło wprowadzać opóźnienia i nakładać praktyczne ograniczenia na rozwój.
W przypadku nowoczesnych obciążeń związanych ze sztuczną inteligencją, wymagających jeszcze większych zestawów danych, punktów kontrolnych, przetwarzania tokenów, wnioskowania i wysoce równoległych potoków danych, te obciążenia tylko się nasiliły.
W całej branży — od Google Cloud Storage (GCS) i Colossus po Microsoft Azure Blob, Amazon S3 i Tectonic firmy Meta — platformy chmurowe przyjęły zdefiniowane programowo architektury stworzone specjalnie z myślą o globalnie rozproszonych danych i obciążeniach o dużej skali, a następnie udoskonalały je z czasem w miarę rozwoju skali i wymagań.
W tym nowym paradygmacie oprogramowanie przejmuje większą odpowiedzialność za koordynację, odporność i przepływ danych, dzięki czemu podstawowe nośniki danych mogą być wykorzystywane możliwie najefektywniej.
Dyski twarde zakotwiczają pamięć masową na dużą skalę
W architekturach chmurowych, takich jak te, o których wspominałem powyżej, dyski twarde stanowią podstawę do przechowywania danych na dużą skalę.
Odzwierciedla to trwałą ekonomikę pojemności i fizykę zapisu o dużej gęstości. Nowoczesne dyski twarde o dużej pojemności wykorzystują technologie takie jak Shingled Magnetic Recording (SMR) i Heat-Assisted Magnetic Recording (HAMR), aby zapewnić coraz większą gęstość powierzchniową i umożliwić przechowywanie danych w skali eksabajtów.
W tej skali floty dysków twardych pełnią funkcję systemu zapisu, zapewniając trwałość, efektywność kosztową i gęstość objętościową, jakiej alternatywne technologie pamięci masowej po prostu nie są w stanie dorównać.
Nie bez powodu 87% dużych eksabajtów w centrach danych jest przechowywanych na dyskach twardych1!
W miarę jak zasoby chmurowe nieustannie się rozrastają, a obciążenia związane ze sztuczną inteligencją zużywają, generują, przechowują i ponownie wykorzystują coraz większe ilości danych, zalety te stają się jeszcze ważniejsze.
Ale ich pełne wykorzystanie będzie możliwe tylko wtedy, gdy architektura oprogramowania zostanie zaprojektowana tak, aby wykorzystać mocne strony dysków o dużej pojemności.
Tradycyjne wzorce dostępu POSIX — zwłaszcza w ramach ściśle powiązanych modeli rozproszonych systemów plików, które kładą nacisk na fragmentaryczne, losowe aktualizacje w miejscu — nie zawsze dobrze współgrają z mocnymi stronami tych rozwiązań w ekstremalnej skali.
Nowoczesne platformy chmurowe definiowane programowo rozwiązały ten problem, projektując stosy pamięci masowej wokół dysków twardych, co pozwoliło im na priorytetyzację sekwencyjnych przepływów danych o dużej przepustowości, a jednocześnie wspierało skalowalność ekonomiczną operacji.
W przypadku Amazon S3, usługi przechowującej 500 bilionów obiektów i obsługującej 200 milionów żądań na sekundę, w niedawnym wystąpieniu na konferencji AWS re:Invent2 podkreślono, że sekretem wydajności pamięci masowej w chmurze jest pisanie oprogramowania optymalizującego możliwości dysku twardego, opisanego w prezentacji jako „cud inżynierii”.
Zamiast zmuszać dysk do dostosowywania się do abstrakcji oprogramowania zaprojektowanych dla innej epoki, nowoczesne architektury chmurowe są projektowane w taki sposób, aby uzupełniać mocne strony nowoczesnych dysków twardych o dużej gęstości.
Jak architektury chmurowe zwiększają wydajność dysków twardych
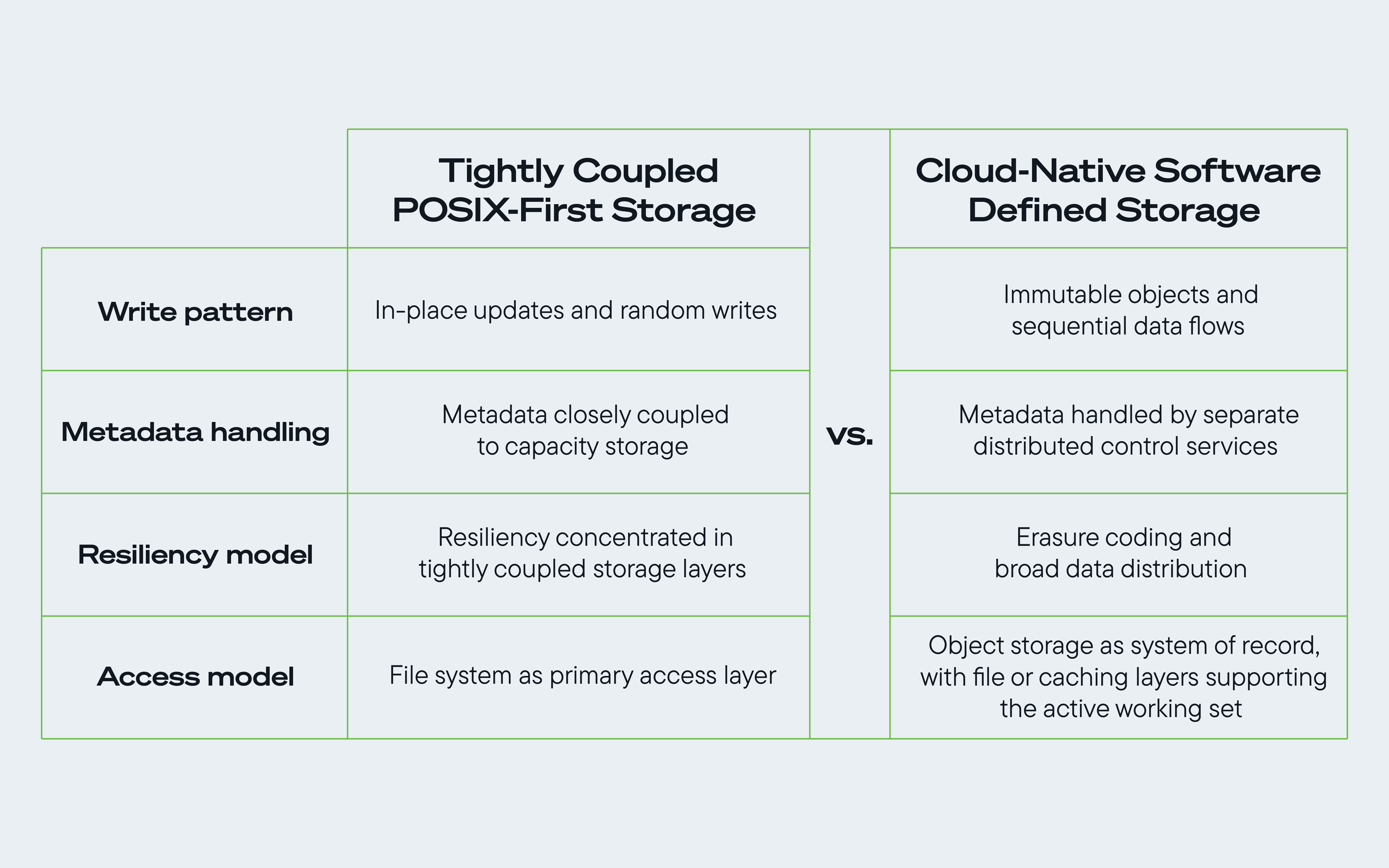
Ten projekt inżynieryjny przybierał różne formy, ale na wiodących platformach chmurowych generalnie odzwierciedlał cztery zasady architektoniczne. Razem pokazują, w jaki sposób przechowywanie danych w chmurze staje się coraz bardziej zależne od oprogramowania pod względem sposobu zarządzania przepływem danych, metadanymi, odpornością i zachowaniem przetwarzania.
1. Niezmienność obiektów sprzyja sekwencyjnym przepływom danych
Usługi takie jak GCS i Amazon S3 są zaprojektowane tak, aby obsługiwać niezmienność obiektów i aktualizacje wersji. Po zapisaniu danych w magazynie obiektów aktualizacje są zazwyczaj obsługiwane przez zapisanie nowej wersji obiektu, a nie przez modyfikowanie istniejącej.
Ograniczając potrzebę losowych, binarnych zapisów w miejscu wystąpienia zdarzenia, architektury o zasięgu chmury przenoszą większą część obciążenia dysku na duże, sekwencyjne przepływy danych. Jest to bardziej zgodne ze sposobem, w jaki dyski o dużej pojemności zapewniają przepustowość i wydajność na dużą skalę. Korzyść ta staje się jeszcze ważniejsza w przypadku obciążeń związanych ze sztuczną inteligencją, w których punkty kontrolne, przenoszenie zestawów danych i równoległe potoki mogą generować stałe obciążenie dla współdzielonych systemów pamięci masowej.
2. Metadane są coraz częściej obsługiwane przez oddzielne lub rozproszone usługi kontrolne
W tradycyjnym środowisku POSIX systemy pamięci masowej często ściśle ze sobą powiązane zarządzają metadanymi plików i ładunkami plików. Platformy chmurowe o dużej skali zmieniły tę sytuację, oddzielając usługi metadanych od pamięci masowej, przenosząc znaczną część zadań śledzenia i koordynacji do szybszych, bardziej skalowalnych warstw kontrolnych, zamiast obciążać tym zadaniem same dyski.
Colossus firmy Google Cloud przenosi znaczną część tej pracy do usług rezydujących w pamięci, podczas gdy Tectonic firmy Meta oddziela metadane — w ramach rozproszonego modelu systemu plików — do bezstanowych mikrousług działających w skalowalnym poziomo magazynie wartości kluczowych. W rezultacie mniejsze jest obciążenie strukturalne podstawowych dysków twardych i większe prawdopodobieństwo zapewnienia dużej pojemności i wydajności na dużą skalę.
3. Kodowanie wymazywania wzmacnia rozproszoną odporność
Trzecią zasadą jest wykorzystanie kodowania kasującego i szerokiej dystrybucji danych w celu zwiększenia odporności i wydajności systemów pamięci masowej na dużą skalę.
Architektura chmurowa ogranicza tę wrażliwość poprzez kodowanie wymazujące i szeroką dystrybucję danych. Rozmieszczając obiekty na wielu dyskach, systemy te mogą izolować zlokalizowane punkty aktywne, kontynuować udostępnianie danych pomimo krótkich okresów opóźnień i rekonstruować dane w razie potrzeby. Dzięki temu warstwa pamięci masowej staje się bardziej odporna, a przepustowość jest utrzymywana w przypadku mieszanych obciążeń chmury i sztucznej inteligencji.
4. Wielowarstwowa ścieżka danych
Czwartą zasadą jest sposób przygotowania danych zanim trafią do nośnika pojemnościowego.
Aby zniwelować różnice między nieprzewidywalnym ruchem aplikacji a ustrukturyzowanym środowiskiem, w którym najlepiej sprawdzają się dyski twarde o dużej gęstości, nowoczesne architektury wykorzystują wielowarstwową ścieżkę danych, obejmującą pamięć flash lub inną pamięć masową do buforowania pobierania i optymalizacji rozmieszczania danych.
Warstwa flash absorbuje zmienne szybkości przybycia z ruchu API i zapisów w aplikacjach. Przetwarza i porządkuje przychodzące dane przed ich przeniesieniem na nośniki pojemnościowe, umożliwiając procesom działającym w tle ich zapis na tablicach dysków twardych w długich, sekwencyjnych przejściach.
W przypadku obciążeń związanych ze sztuczną inteligencją, w których pobieranie, tworzenie punktów kontrolnych i przesyłanie zestawów danych może odbywać się szczególnie dynamicznie, rola bufora staje się jeszcze ważniejsza, ponieważ pomaga zachować niskie opóźnienia przy pobieraniu i efektywne wykorzystanie dysku twardego.
Rys. 1. Porównanie tradycyjnego oprogramowania do przechowywania danych POSIX i oprogramowania do przechowywania danych w chmurze pod kątem maksymalizacji korzyści płynących z architektury przechowywania danych opartej na dyskach twardych.
Nowy model pamięci masowej
Wszystkie te zmiany architektoniczne zmieniły sposób definiowania podstawowej pamięci masowej. Historycznie, termin „podstawowa pamięć masowa” często odnosił się do drogich, wysoce dostępnych systemów blokowych lub plików, ściśle połączonych z procesorem. Pamięć masowa obiektów była częściej traktowana jako miejsce docelowe niższego rzędu, przeznaczone do archiwizacji, tworzenia kopii zapasowych lub przechowywania danych drugorzędnych.
Obecnie wiele architektur chmurowych definiuje podstawową pamięć masową szerzej: obliczenia bezstanowe połączone z globalnym magazynem obiektów. Jeziora danych zbudowane na platformach takich jak S3, Azure i GCS coraz częściej służą jako system rejestrowania analiz na dużą skalę, aplikacji w chmurze i przepływów pracy związanych ze sztuczną inteligencją.
W tym modelu pamięć podstawowa jest coraz częściej definiowana programowo, z usługami obiektowymi, warstwami metadanych, buforowaniem flash i dyskami twardymi o dużej pojemności współpracującymi ze sobą jako skoordynowany system.
Instancje obliczeniowe są często traktowane jako bardziej elastyczne i bezstanowe – pobierają dane z warstwy obiektów, przetwarzają je, a wyniki zapisują z powrotem w tym samym współdzielonym środowisku.
Konwergencja pamięci masowej obiektów i semantyki plików
Wraz ze wzrostem znaczenia pamięci masowej obiektów w architekturach chmurowych w ciągu ostatniej dekady, a ostatnio także w przepływach pracy związanych ze sztuczną inteligencją, pojawił się kolejny ważny trend: wydajne, równoległe systemy plików.
Systemy takie jak Lustre, Weka i VAST są projektowane w celu maksymalizacji wydajności ściśle powiązanych obciążeń, często udostępniając interfejsy zgodne ze standardem POSIX w celu obsługi punktów kontrolnych, koordynacji i dostępu do danych o dużej przepustowości.
Jednocześnie platformy pamięci masowej obiektów nieustannie ewoluują — optymalizują się pod kątem globalnej skalowalności, a jednocześnie zwiększają wydajność, aby obsługiwać coraz szerszy zakres obciążeń wymagających dużej ilości danych i sztucznej inteligencji.
W środowiskach chmury obliczeniowej i sztucznej inteligencji podejścia te zaczynają się ze sobą łączyć. Wysokowydajne systemy plików często stanowią warstwę nad systemami pamięci masowej obiektów lub są ich częścią, łącząc wydajność aktywnego zestawu roboczego ze skalowalnością i ekonomicznością pamięci masowej obiektów jako systemu rekordów.
Ta konwergencja odzwierciedla szerszą zmianę architektoniczną: zamiast wybierać między plikiem a obiektem, nowoczesne systemy je łączą. Zapewnia wygodę korzystania z folderów, przestrzeni nazw i znanych zachowań plików bez poświęcania korzyści skali związanych z przechowywaniem obiektów.
Konsekwencje dla twórców infrastruktury chmurowej i sztucznej inteligencji
Łącznie te zmiany prowadzą do szerszego wniosku: architektura chmury i sztucznej inteligencji wymaga innych kompromisów w zakresie oprogramowania i systemów niż te, które pierwotnie miały być zoptymalizowane pod kątem modeli POSIX.
Kompromisy te zwiększyły znaczenie projektowania oprogramowania optymalizującego wykorzystanie zasobów dysków twardych, na których zbudowane są systemy. W tym sensie obciążenia w chmurze i sztucznej inteligencji nie tylko zmieniły architekturę pamięci masowej, ale także zdefiniowały na nowo samą pamięć podstawową.
Dla twórców infrastruktury wniosek jest jasny: projektowanie nowoczesnych systemów oznacza odejście od założenia, że pamięć podstawowa musi być czytelnie odwzorowana na lokalnym drzewie plików systemu operacyjnego. Oznacza to wybór oprogramowania i modeli dostępu, które są zgodne z ekonomią, prawami fizyki i realiami obciążenia pracą sztucznej inteligencji na dużą skalę.
Organizacje, które podejmą ten temat właściwie, będą lepiej przygotowane do efektywnego wdrażania strategii sztucznej inteligencji, dzięki lepszemu wykorzystaniu procesorów graficznych, lepszej ekonomice wnioskowania i mniejszej liczbie wąskich gardeł wydajnościowych.
Dowiedz się więcej o innowacjach w zakresie dysków twardych, które stanowią podstawę pamięci masowej największych na świecie producentów infrastruktury AI i chmury.
Źródła
1. IDC Datasphere i IDC Storagesphere
2. AWS re:Invent 2025, wykład Andy'ego Warfielda: S3 przechowuje ponad 500 bilionów obiektów, obsługuje 200 milionów żądań na sekundę, przetwarza ponad 1 kwadrylion żądań rocznie