要点
- 推論のパフォーマンスを高め、コストを削減するには、記憶処理とデータ移動がますます重要になっている
- エージェント型AIには、持続的で長期にわたるコンテキストが必要であり、そうしたコンテキストには大容量のハードディスク・ドライブ・ストレージが不可欠
- 多層アーキテクチャ(ハードディスク・ドライブ+GPUメモリ+NVMe SSD)により、コストの急増なしに、コンテキストを拡張可能
エージェント型AIは、価値実現のための新たな最先端技術と見なされています。
組織のリーダーには、計画、実行、改善を継続的に行えるAIシステム、つまり、多段階のワークフローを実行し、重要なビジネス成果をもたらすエージェント型AIが必要です。
しかし、複雑さやクエリ件数が増大するにつれ、こうしたエージェントが依存するコンテキストの保持に限界が出始めており、これは、もはや無視できない現実になりつつあります。
エージェントは物忘れをすることがありますが、これは、モデルの能力不足ではなく、永続的に使用可能なコンテキストメモリの制限によるものです。
AIエコシステムでは、こうした状況を、コンテキストの壁と表現します。
コンテキストの壁とは、エージェントが作業コンテキストを使い果たした状態で、要約や情報の破棄を行ったり、参照済みの事実を繰り返し取得または確認したりしなければならない時点を意味します。これにより、推論速度が低下しコストが増加するほか、多くの場合、品質も悪くなります。結果的に、一貫性がなく、文脈が途切れた回答が返るようになります。
コンテキストの壁は、すぐにビジネス課題に発展します。例を挙げましょう。
- コンピューティング・コストが増加する(手戻り、データ取得サイクル、トークンの増加による)
- 応答が遅くなる(再計算やコンテキストの再読み込みによる遅延)
- 信頼性が低下する(セッションをまたぐ回答に一貫性がない)
- 能力に限界が生じる(エージェントが長期的なタスクを維持し完遂できなくなる)
コンテキストの壁を乗り越えるうえで、モデルの改善は解決策の1つに過ぎません。その点で特に重要なのは、コンテキスト情報を適切に保存し、提供できるようにすることです。
エージェント型AIのための共同ソリューション
こうした課題に対処しようと、Seagateとパートナー各社は、NVIDIA GTCで、すぐに購入し導入可能な多層AIストレージ・ソリューションを発表しました。このソリューションは、AIワークロードのコンテキスト情報拡張を目的としています。
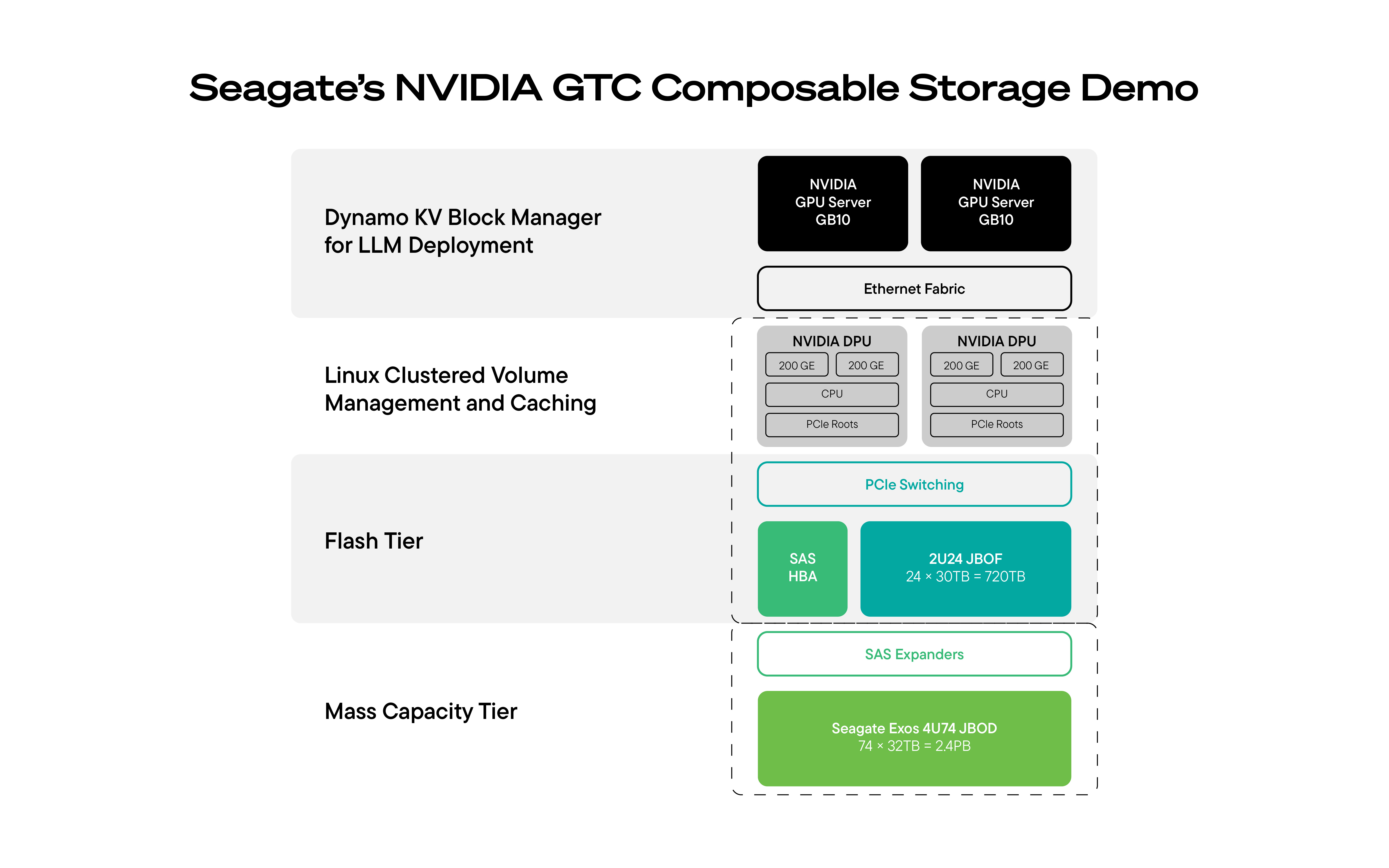
GTCで公表したソリューションは、以下で構成されます。
- NVIDIA DGX Spark GPUクラスタのコンピューティング・ノード:大規模な推論処理を実行
- Supermicro JBOF:高速ネットワーク接続型NVMe SSDキャッシュ層として機能。これにより、直近のコンテキストをコンピューティング環境の近くに保持
- Seagateハードディスク・ドライブJBOD:拡張性に優れた大容量データ・ストレージ層として機能。これにより、コンテキスト情報の長期保存を低コストで実現
- NVIDIA BlueField-3 DPUまたはNVIDIA BlueField-4 DPU:これによって、ストレージからGPUメモリにデータを直接配置する際に、データ移動およびキャッシングをオフロードし、高速化
- DPUでオーケストレーションするオープンソースコンポーネント (NVIDIA Dynamo):これにより、ハードディスク・ドライブ上のデータセットを、SSDを介してインテリジェントにキャッシング
このアーキテクチャは、コンテキストを拡張するためだけでなく、AI推論による利益の考察を見直すうえでも重要となります。エージェント・ワークロードを本番環境に移行すると、エージェントの記憶領域やデータ移動が、モデルの品質だけでなく、パフォーマンス、コスト、信頼性のすべてに大きな影響を与えるようになります。
ヴィク・マリヤラ (Vik Malyala) 氏(Supermicro、EMEA担当社長兼専務取締役、ならびに技術およびAI担当上級副社長)は、こう述べています。「SupermicroのJBOFフラッシュ層とSeagateのハードドライブ層を組み合わせているため、推論コストを大幅に削減すると同時に、高いパフォーマンスを維持できます。特に、自律型AIが広く普及し、推論ワークロードが指数関数的に増加していることを考えると、こうした仕組みが重要となります」
記憶処理技術による競争優位性の強化
推論の課題には、見落とされがちな変化があります。コンピューティングと同様に記憶処理も課題になりつつあるのです。高性能なGPUの真価を発揮させるには、適切なデータを適切なタイミング、速度、コストで提供しなければなりません。
エージェントには、これまで以上に、コンテキストの保存容量が求められます。プロンプトのほかに、以下の情報を維持する必要があるからです。
- 長期にわたる会話および判断履歴
- 方針と手順
- 製品およびトラブルシューティングに関する知識
- 各種ログ、チケット、テレメトリ
これらすべてを即時アクセス層(GPUメモリやオールフラッシュ)に保存しようとするのは、高額な当日配送を全社的に運用するようなものです。少数の荷物なら効果的ですが、大量になると経済的に非現実的な運用となるでしょう。
こうした課題を首尾よく解決するには、多層型の永続ストレージ・アーキテクチャを採用します。
多層ストレージが実用的な解決策である理由
AIスタックは、短期記憶と長期記憶を分離し、各層で最も有効な処理を行った場合に性能が発揮されます。
- リアルタイム・アクセス階層(GPU HBMメモリ、CPU DRAM、ローカルおよびネットワークNVMe SSD):現在のコンテキスト(アクティブなトークン、利用頻度の高い埋め込み値、頻繁にアクセスするデータ)を処理
- 容量階層(ハードディスク・ドライブで構成):大規模データセット、永続的な履歴、拡張されたエージェントの記憶といった、長期的なコンテキストを保持
ビジネス価値は、すべての階層でデータを自動的に配置するというシンプルな原則によって、生み出されます。その結果、GPUを常に稼働させ、コストを抑え、コンテキストの詳細を維持できるのです。
DPUによってデータプレーンを最適化する仕組み
これまで、AIでのパフォーマンス階層と容量階層の統合は、技術的に扱いが難しく、多くの場合、複雑な独自ファイル・システムや、CPU上のオーバーヘッドが不可避であり、繊細なチューニングも必要でした。特に、データ量が急増すると、そうした状況に陥ります。
しかし、データ処理ユニット (DPU) の登場により、その状況は、変化しつつあります。
DPUがあれば、データ移動をオフロードし高速化できるため、単なるデータのやり取りにホストCPUのリソースを消費する必要がなくなります。具体的には、ネットワークとストレージへの高速なアクセス・パターンを確立するとともに、Linuxベースのサービスを実行して、キャッシング、階層化、レジリエンスおよびセキュリティの確保を行えます。つまり、DPUにより、多層AIストレージの導入と拡張が容易になるのです。
こうした技術こそが、本番環境でも通用する多層アーキテクチャを実現可能にします。
多層アーキテクチャで実現可能な処理および効果
Seagate、Supermicro、NVIDIAが開発したアーキテクチャにより、AIのコンテキストを大規模に、かつ、コスト効率よく拡大するのに必要なコア・コンポーネントを統合できます。具体的には、推論処理にGPU、長期的に使用する大容量コンテキストの保存にハードディスク・ドライブ、即時アクセスにNVMe SSDを使用し、階層間のデータ移動およびキャッシング調整にDPUを使用します。
こうした構成により、お客様が最重視するビジネス成果がもたらされます。
エージェント・コンテキストが詳細なほど、ビジネス価値は高まる
このアプローチは、お客様にとって、次のような意義を持ちます。
1.エージェントの記憶能力が向上し、より良い成果がもたらされる
GPUに隣接するストレージに収まる量よりもはるかに大量の履歴データにアクセスできるため、より長期的な視点での推論や高度なパーソナライゼーションが可能になり、コンテキストの抜け落ちによる失敗も減少します。
2.コンテキスト拡張のコストが減少する
長期記憶にハードディスク・ドライブを使用すると、1TBあたりのコストをかなり抑えられます。データセットやエージェントの履歴は絶えず増加するため、この点は重要です。
3.新たな先端技術で効率性が最適化される
今日の組織では、パフォーマンス(1秒あたりのトークン数)に加え、効率性も追跡されており、トークンあたりの消費電力や持続的なGPU使用率といった指標もその対象になっています。その点で、多層設計は、無駄な作業(再読み込み、再処理、再取得)を減らし、GPUの稼働率を維持するのに有用です。
4.今後のAIインフラストラクチャ動向に整合する
現代のAIシステム設計では、DPU主導のデータプレーンが、中心的な役割を担うようになりましたが、このアプローチは、そうした方向性、つまり、単なる計算能力だけでなく、拡張性のあるデータ提供を実現するという考え方に一致するものです。
単なる構想ではなく、エビデンス:GTCでのデモと今後の展開
GTCでは、稼働中のシステムとしてこのアーキテクチャのデモを行いましたが、その際には、推論にGPU、膨大かつ詳細なコンテキストの保存にハードディスク・ドライブ、即時アクセスにSSDを使用し、効率的なデータ移動とキャッシングのオーケストレーションにDPUを使用しました。
AIは、まだ発展の初期段階にありますが、今後も膨大な量のデータを消費し、生成し続けるでしょう。Seagate、Supermicro、NVIDIAの3社は、これまで以上に持続可能かつ効率的で、大規模展開を想定したアーキテクチャにより、その未来を実現していきます。
エージェントを効果的に拡張するには、コンテキストを戦略的資産として捉え、そのコンテキストを効率的に保存し提供可能なインフラストラクチャを構築する必要があります。
詳細については、専門家にお問い合わせください。エージェント・コンテキストの壁を乗り越えるためのサポートについて具体的にご説明します。






-v4.png/_jcr_content/renditions/4-3-small-416x312.png)