Produkte
Wissensbasis
Support-Downloads
Artikel
suggested searches

Es fehlen nur noch [0] für KOSTENLOSEN Versand!
Ihr Warenkorb
Es fehlen nur noch [0] für KOSTENLOSEN Versand!
Ihr Warenkorb
13 Okt., 2025

KI-Anwendungen werden weltweit immer beliebter. Gleichzeitig werden die für KI zugrunde liegenden IT-Lösungen immer leistungsfähiger. Das sorgt für beispiellose Innovationen.
Derzeit stehen vor allem Prozessoren und Logik wegen ihres Beitrags zur KI im Fokus von Unternehmen und Investoren. Selbstverständlich sind Prozessoren unerlässlich für KI- und Hochleistungs-Rechenoperationen. Der Erfolg von KI hängt jedoch nicht nur von Rechenleistung und High-Speed-Performance ab. Ebenso wichtig ist, dass KI-Anwendungen auf Datenspeicher der Enterprise-Klasse zugreifen können, die ein erstes Repository für Rohdaten bieten, Checkpointing für vertrauenswürdige KI-Workflows ermöglichen und Inferenzen sowie die Ergebnisse von KI-Analysen speichern.
Jede erfolgreiche KI-Implementierung erfordert eine Synergie von Rechen- und Datenspeicherressourcen.
Da große Rechenzentren ihre KI-Funktionen immer weiter ausbauen, wird klarer, warum bei der Planung von Rechenzentren für KI-Anwendungen nicht nur auf die Rechenleistung geschaut werden darf. Der Rechen-Cluster umfasst Prozessoren mit Hochleistungs-Speicher mit hoher Bandbreite (HBM), dynamische Direktzugriffsspeicher (DRAM) und leistungsstarke lokale SSDs – die Grundlage für das KI-Training. Die Komponenten des Rechen-Clusters sind lokal und liegen in der Regel direkt nebeneinander, da eine zu große Entfernung voneinander zu Latenz- und Leistungsproblemen führen könnte.
Zudem arbeiten KI-Anwendungen mit einem Speicher-Cluster. Er umfasst Netzwerkfestplatten sowie Netzwerk-SSDs mit großer Kapazität (also solche, die mehr Kapazität haben als die leistungsfähigeren lokalen SSDs im Rechen-Cluster). Der Speicher-Cluster ist vernetzt (verteilt), da bei der Skalierung weniger auf die Geschwindigkeit der Speicher geachtet werden muss. Der Abstand zwischen den Komponenten spielt für die Gesamtlatenz eine geringere Rolle als bei den Rechen-Clustern, wo mitunter Latenzzeiten im Nanosekundenbereich erwartet werden. Der Datenfluss erfolgt am Ende zum Speicher-Cluster, das überwiegend aus Festplatten mit großer Speicherkapazität für die langfristige Speicherung besteht.
In diesem Artikel beleuchten wir, wie Rechenleistung und Speicher in mehreren Phasen eines typischen KI-Workflows zusammenspielen.
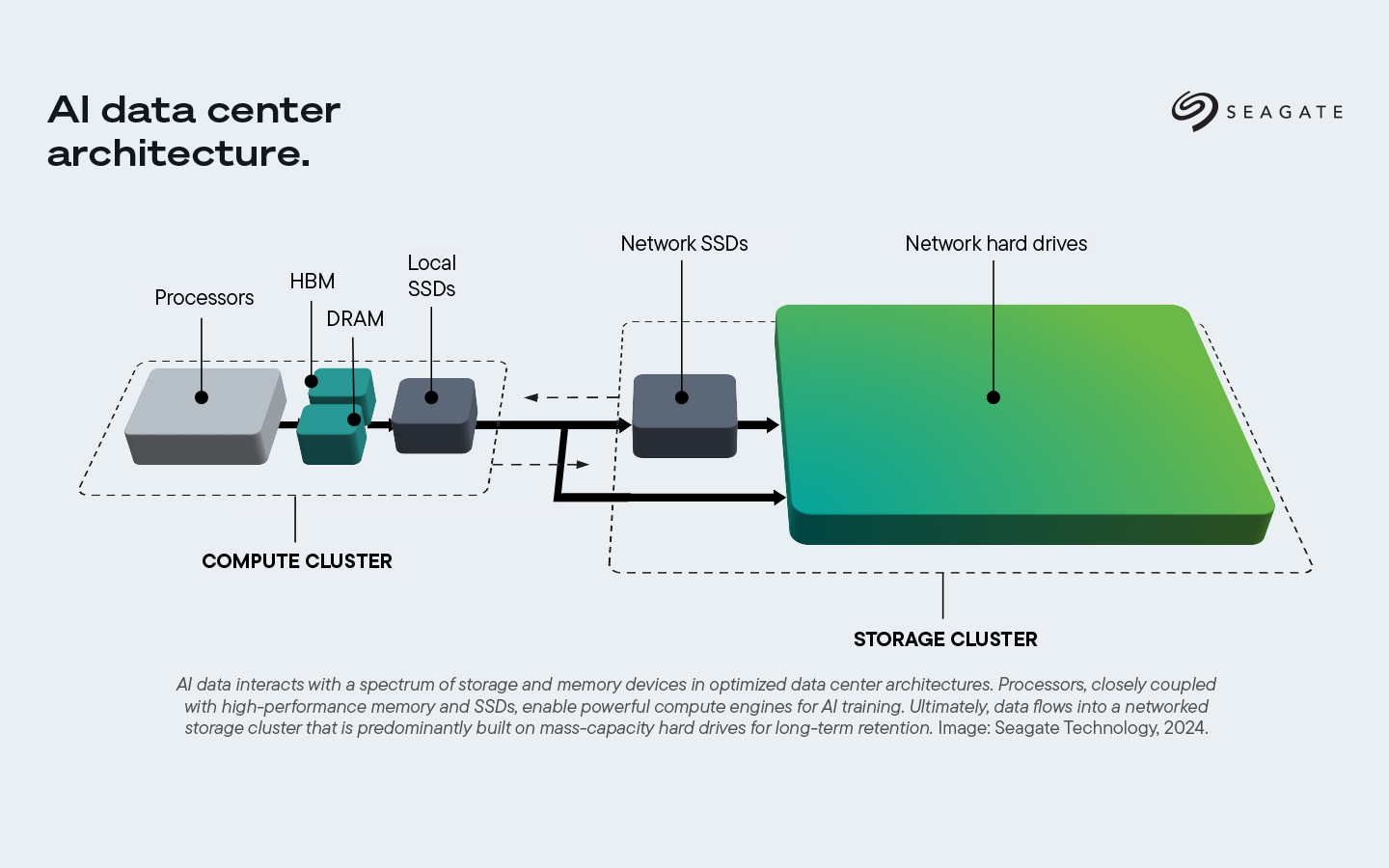
Manche der für KI-Workflows verwendeten Technologien sind besonders leistungsfähig, andere besser skalierbar. Dennoch ist jede davon für den Prozess von entscheidender Bedeutung. Der geräteeigene Arbeitsspeicher ist hochleistungsfähig und besteht im Allgemeinen aus HBM oder DRAM, verbunden mit Prozessoren wie GPUs und CPUs bzw. DPUs (Data Processing Units). DPUs sind funktionale Offload-Engines, die mit CPUs verbunden sind und bei bestimmten Aufgaben unterstützen. Bei manchen Architekturen werden sie genutzt, bei anderen nicht. Der hohe Durchsatz des Arbeitsspeichers ermöglicht eine effiziente Datenaufnahme und das Training von KI-Modellen.

Die geringe Latenz und ausreichende Kapazität von SSDs der Enterprise-Klasse ermöglichen schnelle Inferenz und häufigen Zugriff auf gespeicherte Inhalte. In der Architektur von KI-Rechenzentren gehören schnelle lokale SSDs zum Rechen-Cluster. Sie befinden sich dabei in der Nähe der Prozessoren und des Arbeitsspeichers. Lokale SSDs arbeiten in der Regel mit Triple-Level-Cell-Speicher und bieten eine hohe Widerstandsfähigkeit, sind aber teurer als Netzwerk-SSDs und haben eine geringere Speicherkapazität.
Netzwerk-SSDs mit höherer Speicherkapazität als lokale SSDs werden in den Speicher-Cluster einbezogen, wobei sie eigene Aufgaben im Workflow einer KI-Anwendung erfüllen. Sie sind nicht so schnell wie lokale SSDs. Netzwerk-SSDs leisten im Vergleich weniger Schreibvorgänge pro Tag, was jedoch durch ihre größere Speicherkapazität wieder wett gemacht wird.
Netzwerkfestplatten, die auch Teil des Speicher-Clusters der Architektur eines KI-Rechenzentrums sind, sind die skalierbarsten und effizientesten IT-Geräte in KI-Workflows. Die Zugriffsgeschwindigkeiten dieser Geräte sind vergleichsweise gering, sie haben aber eine sehr hohe Speicherkapazität – ideal für Instanzen, die keinen schnellen und häufigen Zugriff erfordern.
KI-Workflows arbeiten in einer Endlosschleife aus Aufnahme und Erstellung. Hierfür sind nicht nur Prozessoren und Arbeitsspeicher für die Verarbeitung notwendig, sondern auch Speicherkomponenten. Ein KI-Workflow besteht aus: Datenbeschaffung, Modelltraining, Inhalterstellung, Speicherung von Inhalten, Aufbewahrung von Daten und Wiederverwendung von Daten. Sehen wir uns einmal an, welche Rollen Rechenleistung und Speicher in diesen Phasen spielen.

Zur Phase der Datenbeschaffung gehören die Definition, Ermittlung und Aufbereitung von Daten für die KI-Analyse.
Datenverarbeitung: GPUs spielen eine grundlegende Rolle bei der Datenbeschaffung, da sie eine schnelle Datenvorverarbeitung und -umwandlung ermöglichen. Sie ergänzen die CPUs und führen repetitive Berechnungen parallel aus, während die Hauptanwendung auf der CPU läuft. Die CPU fungiert als primäre Einheit und verwaltet mehrere allgemeine Rechenaufgaben, während die GPU eine kleinere Anzahl spezialisierter Aufgaben ausführt.
Speicher: In der Phase der Datenbeschaffung werden sowohl Netzwerk-SSDs und Netzwerkfestplatten zum Speichern der riesigen Datenmengen verwendet, die für die Modellentwicklung nötig sind. Die Netzwerk-SSDs dienen als unmittelbar zugängliche Datenebene und ermöglichen dadurch eine höhere Leistung. Netzwerkfestplatten bieten nicht nur großen, kompakten und skalierbaren Speicher, sondern ermöglichen auch die langfristige Speicherung und den Schutz der Rohdaten.
Schritt 2: Modelle trainieren
Im Schritt des Modelltrainings lernt das Modell anhand der gespeicherten Daten. Das Training erfolgt im Rahmen von Versuch und Irrtum, wobei ein Modell konvergiert und durch Kontrollpunkte abgesichert wird. Das Training erfordert einen sehr schnellen Datenzugriff.
Rechenleistung: GPUs sind während der Trainingsphase von entscheidender Bedeutung, da sie dank ihrer Fähigkeit zur Parallelverarbeitung die enorme Rechenleistung für das Deep Learning aufbringen. Beim KI-Training erfolgen Tausende von Matrixmultiplikationen, die von GPUs gleichzeitig durchgeführt werden. Das verkürzt den Prozess und es können komplexe Modelle mit Milliarden von Parametern trainiert werden. CPUs arbeiten Seite an Seite mit GPUs und orchestrieren den Datenfluss zwischen Arbeitsspeicher und Rechenressourcen. Die CPUs übernehmen Aufgaben wie die Stapelverarbeitung und das Warteschlangenmanagement, damit die GPUs mit den richtigen Daten zur richtigen Zeit versorgt werden. Sie übernehmen auch die Optimierung der Hyperparameter des Modells und führen Berechnungen durch, die eventuell nicht die zusätzliche Unterstützung durch GPUs erfordern.
Beim Training von Modellen sind HBM und DRAM für den schnellen Datenzugriff unerlässlich, da aktive Datensätze in der Nähe der Prozessoren gespeichert werden. HBM, das normalerweise in GPUs integriert ist, erhöht die Geschwindigkeit der Datenverarbeitung erheblich, indem die am häufigsten genutzten Daten während des Trainings für die GPUs zugänglich gehalten werden.
Lokale SSDs dienen als Speicher mit schnellem Zugriff für die in dieser Phase verwendeten Datensätze. Sie speichern Zwischenergebnisse und ermöglichen das schnelle Abrufen großer Datensätze. Sie eignen sich besonders für Trainingsmodelle, die schnell auf große Datenmengen zugreifen müssen, z. B. Bilderkennungsmodelle mit Millionen von Bildern.
Speicher: Die großen Datenmengen, die für das Trainieren von KI-Modellen benötigt werden, können auf kostengünstige Weise auf Festplatten gespeichert werden. Neben der Bereitstellung der erforderlichen skalierbaren Kapazität tragen Festplatten auch zur Aufrechterhaltung der Datenintegrität bei und speichern und schützen die replizierten Versionen der erstellten Inhalte. Festplatten sind im Vergleich zu anderen Speicheroptionen kostengünstig, bieten eine zuverlässige Langzeitspeicherung und ermöglichen eine effiziente Aufbewahrung und Verwaltung großer Datensätze.
Netzwerkfestplatten und Netzwerk-SSDs speichern unter anderem Checkpoints, um das Modelltraining zu schützen und zu optimieren. Checkpoints sind Momentaufnahmen des Zustands eines Modells zu bestimmten Zeitpunkten während Training, Optimierung und Anpassung. Diese Momentaufnahmen können später zum Nachweis des geistigen Eigentums herangezogen werden oder nachvollziehbar machen, wie der Algorithmus zu seinen Schlussfolgerungen gelangt ist. Wenn SSDs für das Checkpointing verwendet werden, werden die Checkpoints aufgrund der geringen Zugriffslatenz in kurzen Intervallen (d. h. jede Minute) erstellt. Aufgrund der im Vergleich zu Festplatten geringen Speicherkapazität werden diese Daten jedoch nach kurzer Zeit wieder überschrieben. Im Gegensatz dazu werden gespeicherte Checkpoints auf Festplatten in der Regel in größeren Intervallen geschrieben (z. B. alle fünf Minuten), können aber aufgrund der skalierbaren Kapazität von Festplatten nahezu unbegrenzt gespeichert werden.
Die Phase der Inhaltserstellung umfasst den Inferenzprozess, bei dem mit dem trainierten Modell Ausgaben erstellt werden.
Datenverarbeitung: Während der Inhaltserstellung führen GPUs die KI-Inferenzaufgaben aus und wenden das trainierte Modell auf neue Dateneingaben an. Dieser parallele Ansatz ermöglicht es GPUs, mehrere Inferenzen gleichzeitig durchzuführen, was sie unabdingbar für Echtzeitanwendungen wie Videoerzeugung oder KI-Systeme macht. Während GPUs vor allem bei der Inhaltserstellung dominieren, sind CPUs für die Verwaltung der Steuerlogik und die Ausführung von Vorgängen entscheidend, die eine serielle Verarbeitung erfordern. Dazu gehören unter anderem das Erzeugen von Skripts, das Verarbeiten von Benutzereingaben und das Ausführen von Hintergrundaufgaben mit geringerer Priorität, die nicht den hohen Durchsatz einer GPU benötigen.
Bei der Inhaltserstellung werden HBM und DRAM genutzt. Der Arbeitsspeicher spielt hier eine entscheidende Rolle für den Echtzeit-Datenzugriff, da die Ergebnisse von KI-Inferenzen flüchtig gespeichert und zur weiteren Optimierung in das Modell zurückgeführt werden können. Die große DRAM-Kapazität ermöglicht die Erstellung von Inhalten in mehreren Iterationen ohne Verlangsamung des Workflows, insbesondere bei Anwendungen wie der Erstellung von Videos oder der Echtzeit-Bildbearbeitung.
Bei der Erstellung von Inhalten bieten lokale SSDs die schnellen Lese- und Schreibgeschwindigkeiten, die für die Verarbeitung in Echtzeit erforderlich sind. Unabhängig davon, ob die KI neue Bilder, Videos oder Text erzeugen soll – SSDs ermöglichen dem System die Bewältigung von häufigen schnellen I/O-Vorgängen ohne Kapazitätsengpässe, wodurch Inhalte schnell produziert werden können.
Speicher: Die primären Speichereinheiten für die Phase der Inhaltserstellung sind HBM, DRAM und lokale SSDs.
In der Phase der Inhaltsspeicherung werden die neu erzeugten Daten zur weiteren Verbesserung, Qualitätssicherung und Compliance gespeichert.
Datenverarbeitung: GPUs und CPUs sind zwar nicht direkt an der langfristigen Speicherung beteiligt, können aber bei der Komprimierung oder Verschlüsselung von Daten behilflich sein, die für die Speicherung vorbereitet werden. Durch die schnelle Verarbeitung großer Datenmengen stehen die Inhalte ohne Verzögerung zur Archivierung bereit.
Arbeitsspeicher wird als temporärer Cache verwendet, bevor die Daten in den Langzeitspeicher verschoben werden. DRAM beschleunigt das Schreiben und ermöglicht schnelles und effizientes Speichern von KI-generierten Inhalten. Das ist besonders bei Echtzeit-KI-Anwendungen wichtig, denn dort können Verzögerungen bei der Datenspeicherung zu Engpässen führen.
Speicher: Bei der Inhaltsspeicherung sind sowohl Netzwerk-SSDs als auch Netzwerkfestplatten involviert. Auf ihnen werden Daten zur kontinuierlichen Optimierung, Qualitätssicherung und für die Compliance gespeichert. Netzwerk-SSDs bieten eine Datenebene mit entsprechender Geschwindigkeit und werden für die kurzfristige, schnelle Speicherung von KI-generierten Inhalten verwendet. Aufgrund der geringeren Speicherkapazität im Vergleich zu Festplatten werden auf SSDs gerne häufig aufgerufene Inhalte geschrieben, oder solche Inhalte, die sofort zur Bearbeitung oder Optimierung verfügbar sein müssen.
Bei der Iteration entstehen neue, validierte Daten, die einen Speicher erfordern. Diese Daten werden zur kontinuierlichen Optimierung, Qualitätssicherung und Compliance gespeichert. Festplatten speichern und schützen die replizierten Versionen der erstellten Inhalte und bieten die wichtige Kapazität für die Speicherung der bei KI-Prozessen generierten Inhalte. Sie sind hierfür besonders gut geeignet, da sie im Vergleich zu anderen Lösungen wie SSDs eine große Speicherkapazität zu einem relativ günstigen Preis bieten.
Im Schritt der Datenaufbewahrung werden replizierte Datensätze über Regionen und Umgebungen hinweg aufbewahrt. In dieser Phase spielen gewöhnlich Speicherressourcen die Hauptrolle.
Speicher: Die gespeicherten Daten sind die Grundlage einer zuverlässigen KI. Damit können Data Scientists sicherstellen, dass die Modelle wie erwartet funktionieren. Netzwerk-SSDs werden als Leistungsbrücke verwendet, um Festplatten mit der lokalen SSD-Ebene zu verbinden und den Datenverkehr in der Umgebung zu unterstützen.
Festplatten der Enterprise-Klasse sind die wichtigsten Geräte für Daten, die langfristig gespeichert und geschützt werden müssen. Sie tragen dazu bei, dass die Ergebnisse der Erstellung von KI-Inhalten erhalten bleiben, indem die generierten Inhalte sicher gespeichert werden, damit bei Bedarf auf sie zugegriffen werden kann. Sie bieten zudem die erforderliche Skalierbarkeit zur effizienten Bewältigung des wachsenden Datenvolumens.
In der Phase der Datenwiederverwendung werden die Quell-, Trainings- und Inferenzdaten schließlich auf die nächste Iteration des Workflows angewendet.
Datenverarbeitung: GPUs spielen eine wichtige Rolle bei der Wiederverwendung von Daten, indem sie Modelle auf archivierten Datensätzen für neue Inferenzen oder zusätzliches Training erneut ausführen und so den KI-Datenzyklus neu beginnen können. Die Fähigkeit, parallele Berechnungen an großen Datensätzen durchzuführen, ermöglicht KI-Systemen die kontinuierliche Verbesserung der Modellgenauigkeit bei minimalem Zeitaufwand. Die CPUs fragen gespeicherte Daten ab und rufen sie zur Wiederverwendung ab. Sie filtern und verarbeiten ältere Daten effizient und speisen relevante Teile wieder in die Trainingsmodelle ein. In großen KI-Systemen übernehmen CPUs diese Aufgaben oft und managen gleichzeitig die Interaktionen zwischen Speichersystemen und Rechen-Clustern.
Wenn ältere Daten zur Wiederverwendung in einer anderen Iteration der Analyse des KI-Modells abgerufen werden, sorgt der Arbeitsspeicher für schnellen Zugriff auf große Datensätze. HBM ermöglicht das schnelle Laden von Datensätzen in den GPU-Speicher, wo sie sofort für neues Training oder Echtzeit-Inferenz verwendet werden können.
Speicher: Die Inhaltsergebnisse fließen wieder in das Modell ein, was dessen Genauigkeit verbessert und neue Modelle ermöglicht. Netzwerkfestplatten und -SSDs unterstützen die geografisch verteilte KI-Datenerstellung. Rohdatensätze und -ergebnisse werden zu Quellen für neue Workflows. SSDs beschleunigen das Abrufen zuvor gespeicherter Daten. Der latenzarme Zugriff erleichtert die Wiederintegration dieser Daten in KI-Workflows, wodurch Wartezeiten reduziert und die Gesamteffizienz des Systems erhöht werden.
Festplatten ermöglichen die massenhafte Speicherung in der Phase der Wiederverwendung von Daten und ermöglichen so eine Implementierung der anschließenden Iteration des Modells zu angemessenen Kosten.
Wie wir gesehen haben, erfordern KI-Workflows leistungsstarke Prozessoren und Datenspeicherlösungen. On-Device-Arbeitsspeicher und SSDs haben durch ihre High-Speed-Performance und die dadurch mögliche schnelle Interferenz zurecht eine wichtige Rolle bei KI-Anwendungen Aus unserer Sicht sind jedoch Festplatten gewissermaßen das Rückgrat von KI. Besonders wichtig sind sie deshalb, weil sie wirtschaftliches Skalieren ermöglichen – in vielen KI-Workflows unerlässlich.
Seagate-Festplatten mit Mozaic 3+™-Technologie – unserer einzigartigen Implementierung der HAMR-Technologie (Heat-Assisted Magnetic Recording) – sind aufgrund ihrer Flächendichte, Effizienz und Platzoptimierung eine leistungsstarke Wahl für KI-Anwendungen. Sie bieten eine beispiellose Flächendichte von über 3 TB pro Platte, sind derzeit mit Kapazitäten ab 30 TB erhältlich und werden in großen Mengen an Hyperscaler ausgeliefert. Bei der aktuell in der Testphase befindlichen Seagate Mozaic-Plattform werden bereits Kapazitäten von über 4 und 5 TB pro Platte erreicht.
Im Vergleich zu den aktuellen Festplatten mit vertikaler Aufzeichnung (PMR) benötigen die Mozaic 3+ viermal weniger Betriebsleistung und produzieren zehnmal weniger grauen Kohlenstoff pro Terabyte.

KI-Workloads sind ein Zusammenspiel aus Rechenleistung und Speicher. Rechenleistung und Arbeitsspeicher sowie hochleistungsfähige SSDs sind für KI-Anwendungen unerlässlich. Ebenso unerlässlich sind jedoch auch skalierbare Speicherlösungen, allen voran die Festplatten von Seagate.












