Was this content helpful?
How could we make this article more helpful?
Import to Google Cloud Storage
Prerequisites
Before you can configure and submit your import plan, make sure to complete the following steps so that Lyve Import Service can securely access your specified Google Cloud Storage bucket to import your data:
Google Cloud subscription—Set up an Google Cloud account.
Google Cloud project—Set up a Google Cloud project. To learn more, see Creating and managing projects. Note—Make sure that billing is enabled for your Cloud project. To learn more, see Verify the billing status of your projects.
Google Cloud Storage bucket—Set up a dedicated bucket for your import. To learn more, see Create buckets.
IP address access—If configured by your organization, list Seagate’s IP address(es) as an allowed source. See IP Address Access.
Seagate authorizations—See below.
Seagate authorizations
Seagate requires permissions to read, write, and list to your bucket to perform the import. Hash-based message authentication code (HMAC) keys using an Access ID and Secret are required to authenticate requests to your cloud resources. To generate the HMAC keys, follow the steps below after creating your bucket:
- Using the Google Cloud console, go to the Cloud Storage Buckets page and click Settings.
- Click the Interoperability tab. Click Create A Key For A Service Account.
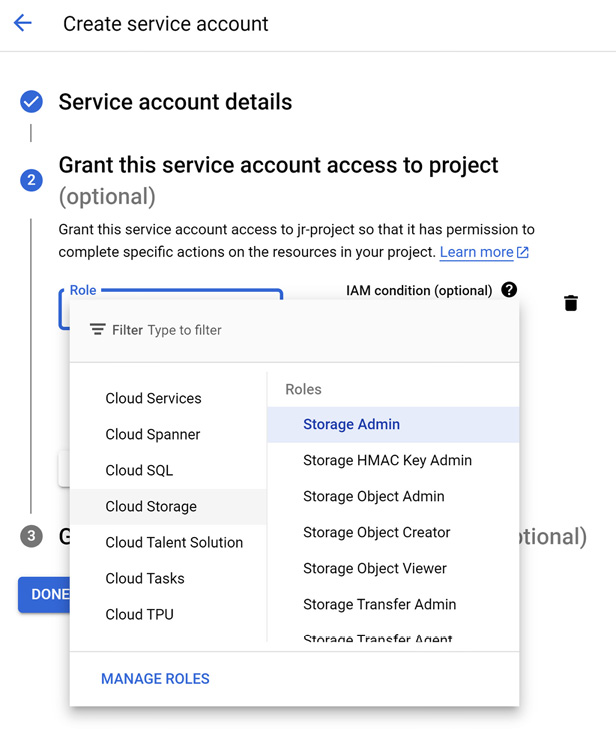
- Select the service account you want the HMAC key to be associated with, or click Create New Account to create a new service account.
- If creating a new service account, select Storage Admin for the role.
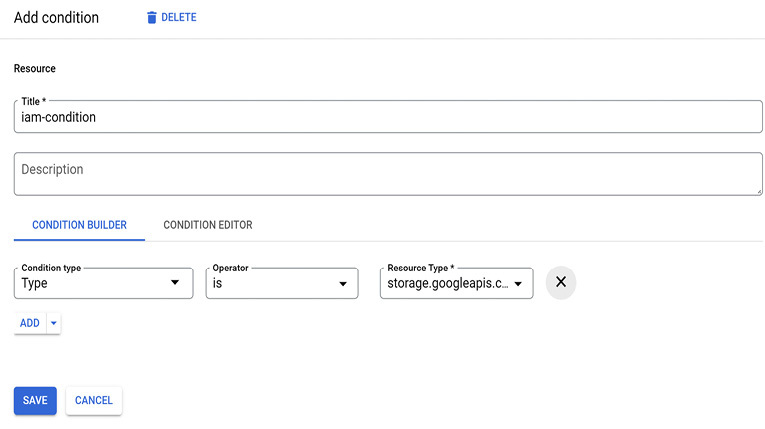
- Add an IAM condition with the following selections:
- Condition type = Type
- Operator = is
- Resource Type = storage.googleapis.com/Bucket.
- Record the service account HMAC key.
- Navigate to the Cloud Storage Buckets page and locate the bucket to which you want to assign access for your import. Click the Bucket overflow menu (
 ) and select Edit Access.
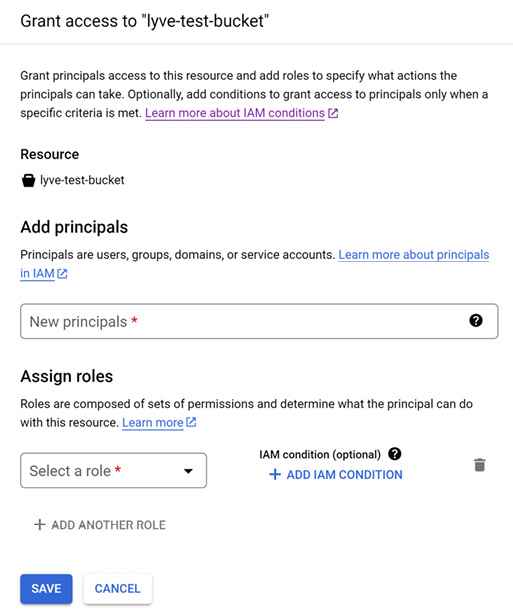
) and select Edit Access. - Click Add Principal.
- Enter the email address of the service account the HMAC keys are associated with. Note—You can find the service account email in the IAM console.
- Select the Storage Admin role and click Save.

Click Save.
Recommendations
Seagate strongly recommends the following best practices:
- Create a bucket dedicated to your import plan.
- When creating your bucket, select “Region” for location type.
- Block all public access for your bucket.
- Disable or delete the HMAC key after the import plan has ended.
Configure your import plan
Add your cloud destination credentials and bucket information to configure your cloud import plan.
- All devices within a subscription must be imported to the same destination and region.
- You will be required to enter and validate your bucket credentials.
- On your Home page, select Subscriptions from the sidebar.
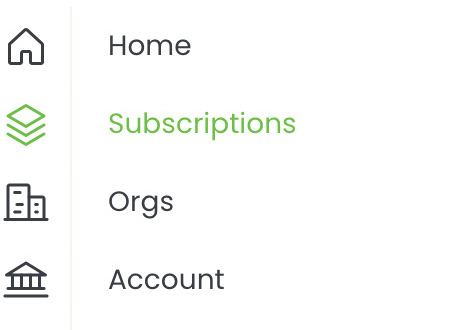
- Select a Lyve Mobile service subscription from the list that includes a Cloud Import plan.
- Select Import Plans in the sidebar, or select the link at the top of the page:

- Confirm the Cloud Destination and Region. Select Next.
- Add the Access ID and Secret for your cloud destination. Specify an existing bucket for the subscription. Select Validate Credentials.
- To enable the checkbox, select the IP Address Access Guide link.
- Select the checkbox, and then select Submit.
Inviting another user to configure an import plan
If a different member of your Org needs to configure the import plan for a Lyve Mobile subscription, you can invite them to do so in Lyve Management Portal.
- The person must be a member of the Org containing the Lyve Mobile subscription to which you want to add the import plan. See Manage Org members in the Lyve Management Portal User Manual.
- The member must be given the Manage Import Plans permission. See Manage subscription members in the Lyve Management Portal User Manual.
Naming guidelines
Bucket naming guidelines:
- Bucket names can only contain lowercase letters, numeric characters, dashes - , underscores _ , and dots . . Spaces are not allowed. Names containing dots require verification.
- Bucket names must start and end with a number or letter.
- Bucket names must contain 3-63 characters. Names containing dots can contain up to 222 characters, but each dot-separated component can be no longer than 63 characters.
- Bucket names cannot be represented as an IP address in dotted-decimal notation (for example, 192.168.5.4).
- Bucket names cannot begin with the goog prefix.
- Bucket names cannot contain google or close misspellings, such as g00gle .
Object naming guidelines:
- Object names can contain any sequence of valid Unicode characters, of length 1-1024 bytes when UTF-8 encoded.
- Object names cannot contain Carriage Return or Line Feed characters.
- Object names cannot start with .well-known/acme-challenge/.
- Objects cannot be named . or .. .
Avoid the Following in Object Names:
- Control characters that are illegal in XML 1.0 (#x7F–#x84 and #x86–#x9F): these characters cause XML listing issues when you try to list your objects.
- The # character: Google Cloud CLI commands interpret object names ending with #<numeric string> as version identifiers, so including # in object names can make it difficult or impossible to perform operations on such versioned objects using the gcloud CLI.
- The [ , ] , * , or ? characters: gcloud storage and gsutil interpret these characters as wildcards, so including them in object names can make it difficult or impossible to perform wildcard operations with those tools.
- Sensitive or personally identifiable information (PII): object names are more broadly visible than object data. For example, object names appear in URLs for the object and when listing objects in a bucket.
To learn more, see Object Naming Requirements.
Best practices
See the following knowledge base article:
Troubleshooting
See the following knowledge base articles: